 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Classification and Segmentation in Osteosarcoma Assessment via Foundation and Discrete Diffusion Models
Jan 03, 2025
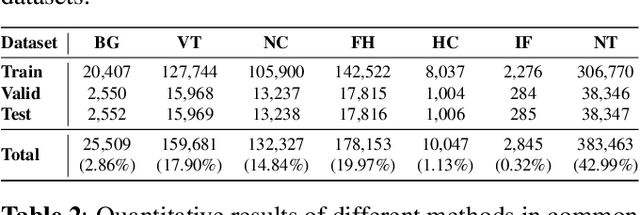
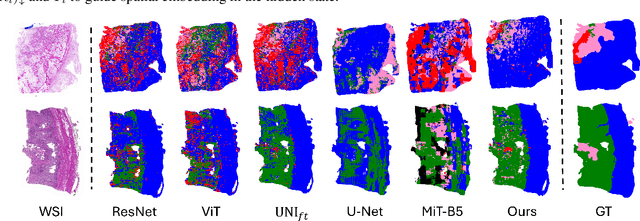
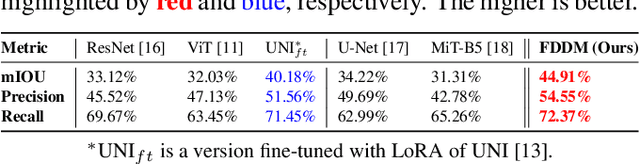
Osteosarcoma, the most common primary bone cancer, often requires accurate necrosis assessment from whole slide images (WSIs) for effective treatment planning and prognosis. However, manual assessments are subjective and prone to variability. In response, we introduce FDDM, a novel framework bridging the gap between patch classification and region-based segmentation. FDDM operates in two stages: patch-based classification, followed by region-based refinement, enabling cross-patch information intergation. Leveraging a newly curated dataset of osteosarcoma images, FDDM demonstrates superior segmentation performance, achieving up to a 10% improvement mIOU and a 32.12% enhancement in necrosis rate estimation over state-of-the-art methods. This framework sets a new benchmark in osteosarcoma assessment, highlighting the potential of foundation models and diffusion-based refinements in complex medical imaging tasks.
CT to PET Translation: A Large-scale Dataset and Domain-Knowledge-Guided Diffusion Approach
Oct 29, 2024



Positron Emission Tomography (PET) and Computed Tomography (CT) are essential for diagnosing, staging, and monitoring various diseases, particularly cancer. Despite their importance, the use of PET/CT systems is limited by the necessity for radioactive materials, the scarcity of PET scanners, and the high cost associated with PET imaging. In contrast, CT scanners are more widely available and significantly less expensive. In response to these challenges, our study addresses the issue of generating PET images from CT images, aiming to reduce both the medical examination cost and the associated health risks for patients. Our contributions are twofold: First, we introduce a conditional diffusion model named CPDM, which, to our knowledge, is one of the initial attempts to employ a diffusion model for translating from CT to PET images. Second, we provide the largest CT-PET dataset to date, comprising 2,028,628 paired CT-PET images, which facilitates the training and evaluation of CT-to-PET translation models. For the CPDM model, we incorporate domain knowledge to develop two conditional maps: the Attention map and the Attenuation map. The former helps the diffusion process focus on areas of interest, while the latter improves PET data correction and ensures accurate diagnostic information. Experimental evaluations across various benchmarks demonstrate that CPDM surpasses existing methods in generating high-quality PET images in terms of multiple metrics. The source code and data samples are available at https://github.com/thanhhff/CPDM.
FedMAC: Tackling Partial-Modality Missing in Federated Learning with Cross-Modal Aggregation and Contrastive Regularization
Oct 04, 2024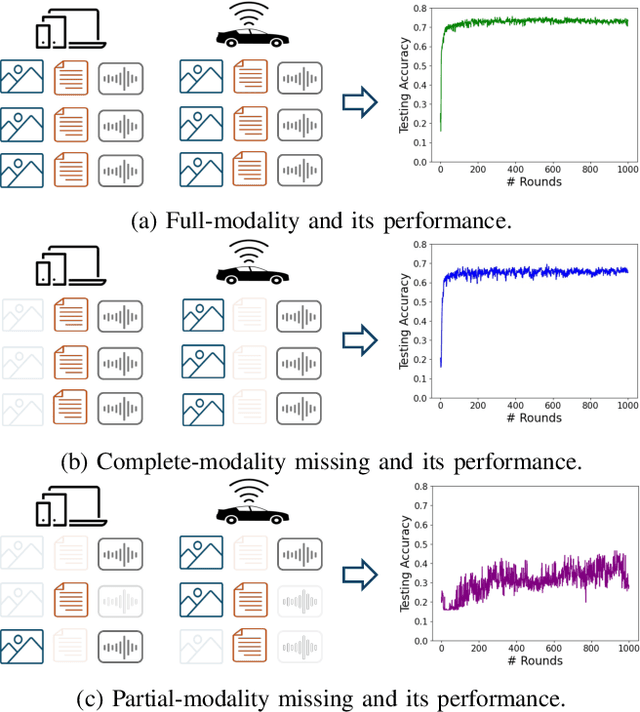
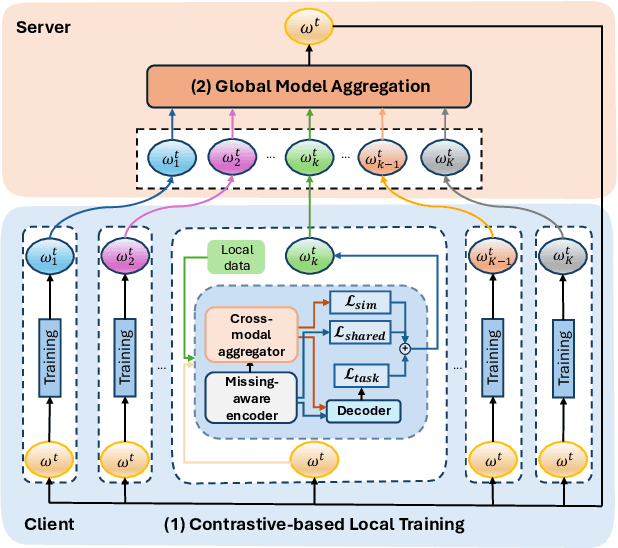
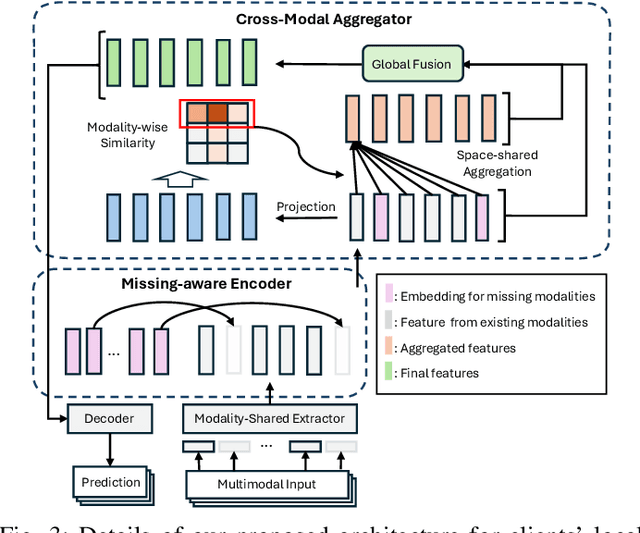
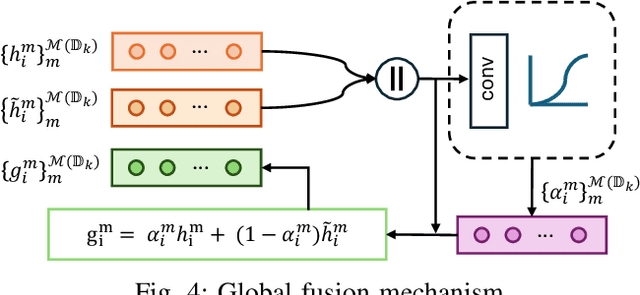
Federated Learning (FL) is a method for training machine learning models using distributed data sources. It ensures privacy by allowing clients to collaboratively learn a shared global model while storing their data locally. However, a significant challenge arises when dealing with missing modalities in clients' datasets, where certain features or modalities are unavailable or incomplete, leading to heterogeneous data distribution. While previous studies have addressed the issue of complete-modality missing, they fail to tackle partial-modality missing on account of severe heterogeneity among clients at an instance level, where the pattern of missing data can vary significantly from one sample to another. To tackle this challenge, this study proposes a novel framework named FedMAC, designed to address multi-modality missing under conditions of partial-modality missing in FL. Additionally, to avoid trivial aggregation of multi-modal features, we introduce contrastive-based regularization to impose additional constraints on the latent representation space. The experimental results demonstrate the effectiveness of FedMAC across various client configurations with statistical heterogeneity, outperforming baseline methods by up to 26% in severe missing scenarios, highlighting its potential as a solution for the challenge of partially missing modalities in federated systems.
Training-Free Condition Video Diffusion Models for single frame Spatial-Semantic Echocardiogram Synthesis
Aug 06, 2024
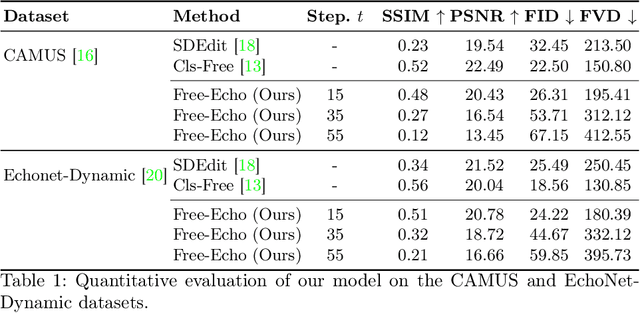
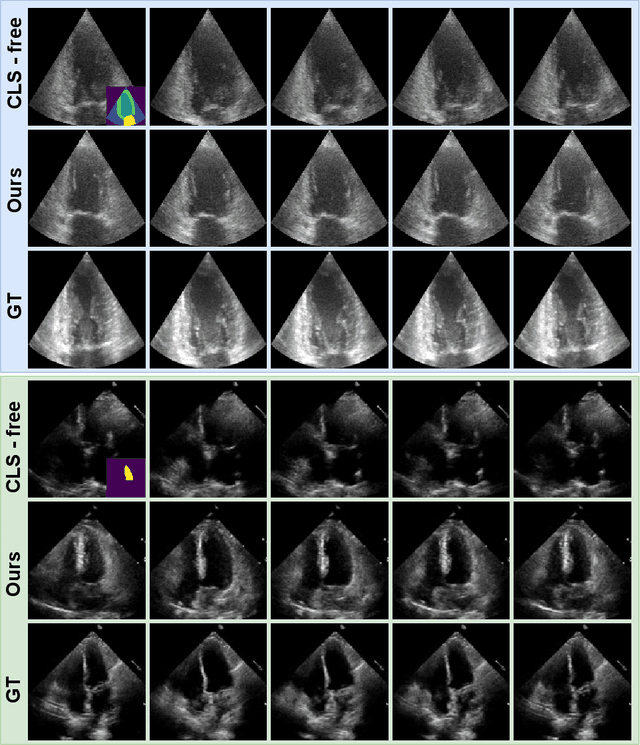
Conditional video diffusion models (CDM) have shown promising results for video synthesis, potentially enabling the generation of realistic echocardiograms to address the problem of data scarcity. However, current CDMs require a paired segmentation map and echocardiogram dataset. We present a new method called Free-Echo for generating realistic echocardiograms from a single end-diastolic segmentation map without additional training data. Our method is based on the 3D-Unet with Temporal Attention Layers model and is conditioned on the segmentation map using a training-free conditioning method based on SDEdit. We evaluate our model on two public echocardiogram datasets, CAMUS and EchoNet-Dynamic. We show that our model can generate plausible echocardiograms that are spatially aligned with the input segmentation map, achieving performance comparable to training-based CDMs. Our work opens up new possibilities for generating echocardiograms from a single segmentation map, which can be used for data augmentation, domain adaptation, and other applications in medical imaging. Our code is available at \url{https://github.com/gungui98/echo-free}
FedGrad: Mitigating Backdoor Attacks in Federated Learning Through Local Ultimate Gradients Inspection
Apr 29, 2023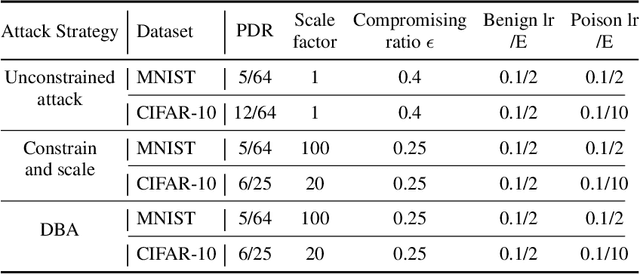
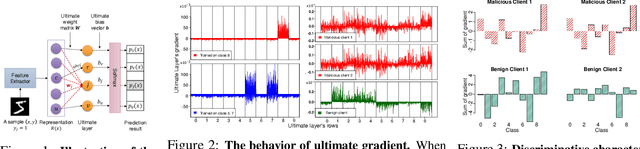
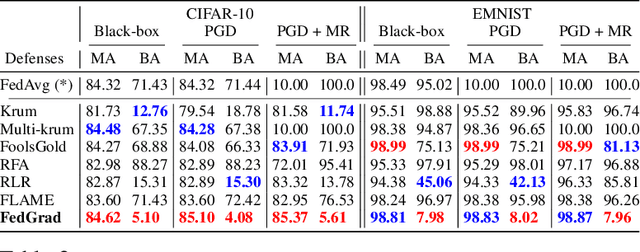
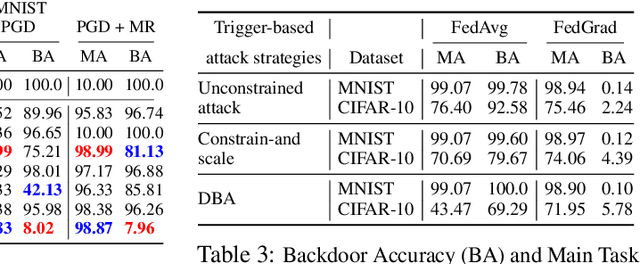
Federated learning (FL) enables multiple clients to train a model without compromising sensitive data. The decentralized nature of FL makes it susceptible to adversarial attacks, especially backdoor insertion during training. Recently, the edge-case backdoor attack employing the tail of the data distribution has been proposed as a powerful one, raising questions about the shortfall in current defenses' robustness guarantees. Specifically, most existing defenses cannot eliminate edge-case backdoor attacks or suffer from a trade-off between backdoor-defending effectiveness and overall performance on the primary task. To tackle this challenge, we propose FedGrad, a novel backdoor-resistant defense for FL that is resistant to cutting-edge backdoor attacks, including the edge-case attack, and performs effectively under heterogeneous client data and a large number of compromised clients. FedGrad is designed as a two-layer filtering mechanism that thoroughly analyzes the ultimate layer's gradient to identify suspicious local updates and remove them from the aggregation process. We evaluate FedGrad under different attack scenarios and show that it significantly outperforms state-of-the-art defense mechanisms. Notably, FedGrad can almost 100% correctly detect the malicious participants, thus providing a significant reduction in the backdoor effect (e.g., backdoor accuracy is less than 8%) while not reducing the main accuracy on the primary task.
High Accurate and Explainable Multi-Pill Detection Framework with Graph Neural Network-Assisted Multimodal Data Fusion
Mar 17, 2023


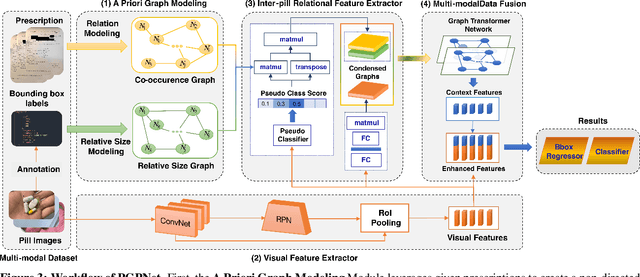
Due to the significant resemblance in visual appearance, pill misuse is prevalent and has become a critical issue, responsible for one-third of all deaths worldwide. Pill identification, thus, is a crucial concern needed to be investigated thoroughly. Recently, several attempts have been made to exploit deep learning to tackle the pill identification problem. However, most published works consider only single-pill identification and fail to distinguish hard samples with identical appearances. Also, most existing pill image datasets only feature single pill images captured in carefully controlled environments under ideal lighting conditions and clean backgrounds. In this work, we are the first to tackle the multi-pill detection problem in real-world settings, aiming at localizing and identifying pills captured by users in a pill intake. Moreover, we also introduce a multi-pill image dataset taken in unconstrained conditions. To handle hard samples, we propose a novel method for constructing heterogeneous a priori graphs incorporating three forms of inter-pill relationships, including co-occurrence likelihood, relative size, and visual semantic correlation. We then offer a framework for integrating a priori with pills' visual features to enhance detection accuracy. Our experimental results have proved the robustness, reliability, and explainability of the proposed framework. Experimentally, it outperforms all detection benchmarks in terms of all evaluation metrics. Specifically, our proposed framework improves COCO mAP metrics by 9.4% over Faster R-CNN and 12.0% compared to vanilla YOLOv5. Our study opens up new opportunities for protecting patients from medication errors using an AI-based pill identification solution.
CADIS: Handling Cluster-skewed Non-IID Data in Federated Learning with Clustered Aggregation and Knowledge DIStilled Regularization
Feb 21, 2023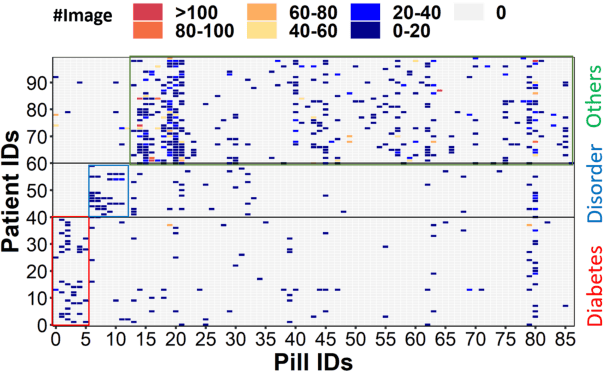

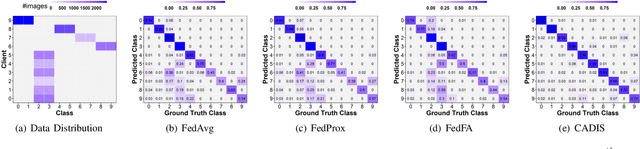
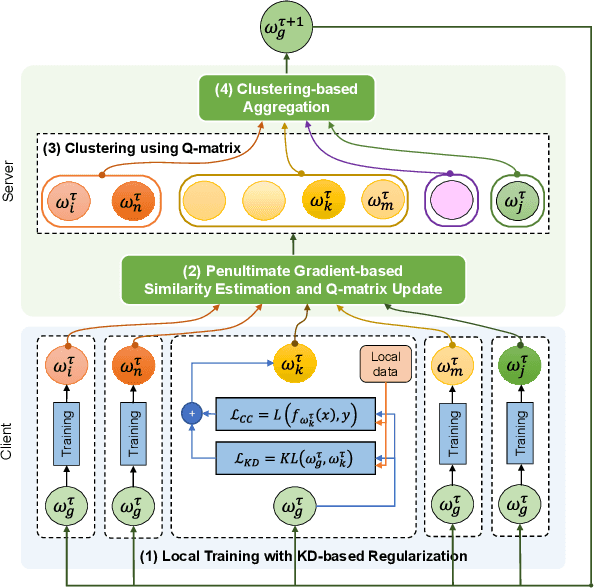
Federated learning enables edge devices to train a global model collaboratively without exposing their data. Despite achieving outstanding advantages in computing efficiency and privacy protection, federated learning faces a significant challenge when dealing with non-IID data, i.e., data generated by clients that are typically not independent and identically distributed. In this paper, we tackle a new type of Non-IID data, called cluster-skewed non-IID, discovered in actual data sets. The cluster-skewed non-IID is a phenomenon in which clients can be grouped into clusters with similar data distributions. By performing an in-depth analysis of the behavior of a classification model's penultimate layer, we introduce a metric that quantifies the similarity between two clients' data distributions without violating their privacy. We then propose an aggregation scheme that guarantees equality between clusters. In addition, we offer a novel local training regularization based on the knowledge-distillation technique that reduces the overfitting problem at clients and dramatically boosts the training scheme's performance. We theoretically prove the superiority of the proposed aggregation over the benchmark FedAvg. Extensive experimental results on both standard public datasets and our in-house real-world dataset demonstrate that the proposed approach improves accuracy by up to 16% compared to the FedAvg algorithm.
A Novel Approach for Pill-Prescription Matching with GNN Assistance and Contrastive Learning
Sep 02, 2022

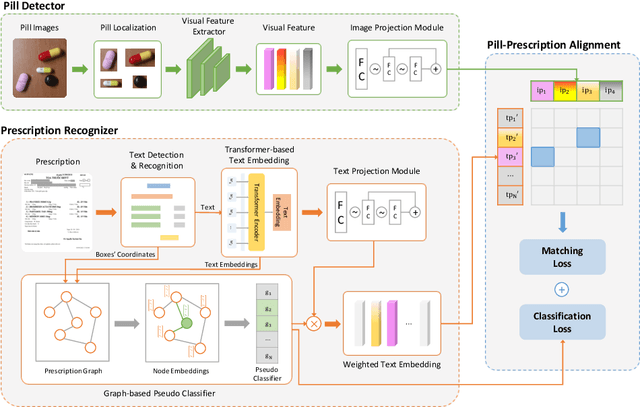
Medication mistaking is one of the risks that can result in unpredictable consequences for patients. To mitigate this risk, we develop an automatic system that correctly identifies pill-prescription from mobile images. Specifically, we define a so-called pill-prescription matching task, which attempts to match the images of the pills taken with the pills' names in the prescription. We then propose PIMA, a novel approach using Graph Neural Network (GNN) and contrastive learning to address the targeted problem. In particular, GNN is used to learn the spatial correlation between the text boxes in the prescription and thereby highlight the text boxes carrying the pill names. In addition, contrastive learning is employed to facilitate the modeling of cross-modal similarity between textual representations of pill names and visual representations of pill images. We conducted extensive experiments and demonstrated that PIMA outperforms baseline models on a real-world dataset of pill and prescription images that we constructed. Specifically, PIMA improves the accuracy from 19.09% to 46.95% compared to other baselines. We believe our work can open up new opportunities to build new clinical applications and improve medication safety and patient care.
Image-based Contextual Pill Recognition with Medical Knowledge Graph Assistance
Aug 09, 2022

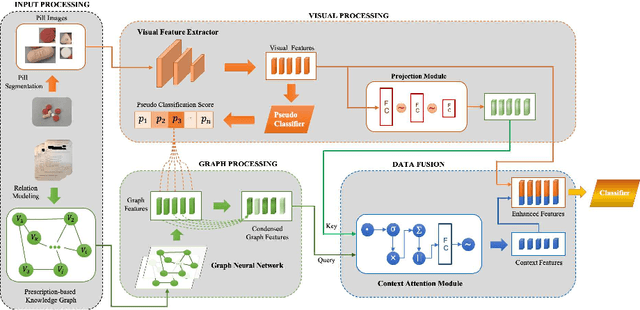
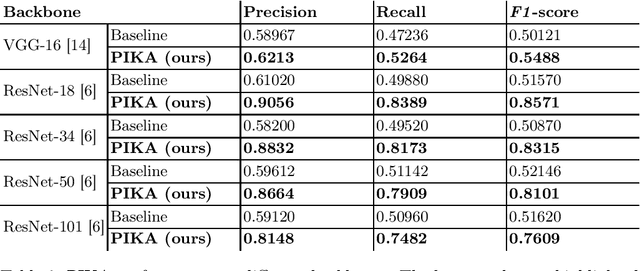
Identifying pills given their captured images under various conditions and backgrounds has been becoming more and more essential. Several efforts have been devoted to utilizing the deep learning-based approach to tackle the pill recognition problem in the literature. However, due to the high similarity between pills' appearance, misrecognition often occurs, leaving pill recognition a challenge. To this end, in this paper, we introduce a novel approach named PIKA that leverages external knowledge to enhance pill recognition accuracy. Specifically, we address a practical scenario (which we call contextual pill recognition), aiming to identify pills in a picture of a patient's pill intake. Firstly, we propose a novel method for modeling the implicit association between pills in the presence of an external data source, in this case, prescriptions. Secondly, we present a walk-based graph embedding model that transforms from the graph space to vector space and extracts condensed relational features of the pills. Thirdly, a final framework is provided that leverages both image-based visual and graph-based relational features to accomplish the pill identification task. Within this framework, the visual representation of each pill is mapped to the graph embedding space, which is then used to execute attention over the graph representation, resulting in a semantically-rich context vector that aids in the final classification. To our knowledge, this is the first study to use external prescription data to establish associations between medicines and to classify them using this aiding information. The architecture of PIKA is lightweight and has the flexibility to incorporate into any recognition backbones. The experimental results show that by leveraging the external knowledge graph, PIKA can improve the recognition accuracy from 4.8% to 34.1% in terms of F1-score, compared to baselines.
FedDRL: Deep Reinforcement Learning-based Adaptive Aggregation for Non-IID Data in Federated Learning
Aug 04, 2022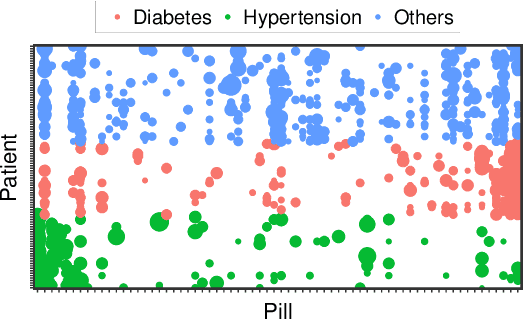

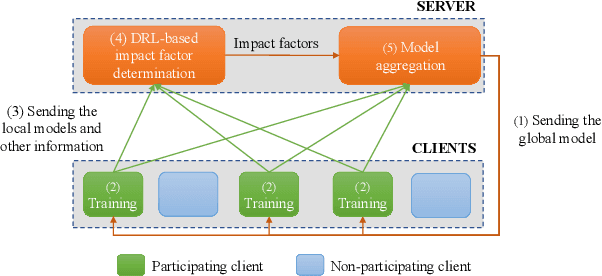
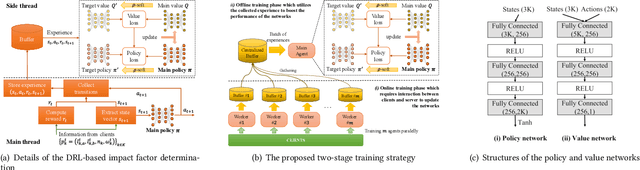
The uneven distribution of local data across different edge devices (clients) results in slow model training and accuracy reduction in federated learning. Naive federated learning (FL) strategy and most alternative solutions attempted to achieve more fairness by weighted aggregating deep learning models across clients. This work introduces a novel non-IID type encountered in real-world datasets, namely cluster-skew, in which groups of clients have local data with similar distributions, causing the global model to converge to an over-fitted solution. To deal with non-IID data, particularly the cluster-skewed data, we propose FedDRL, a novel FL model that employs deep reinforcement learning to adaptively determine each client's impact factor (which will be used as the weights in the aggregation process). Extensive experiments on a suite of federated datasets confirm that the proposed FedDRL improves favorably against FedAvg and FedProx methods, e.g., up to 4.05% and 2.17% on average for the CIFAR-100 dataset, respectively.