 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Free Condition Video Diffusion Models for single frame Spatial-Semantic Echocardiogram Synthesis
Aug 06, 2024
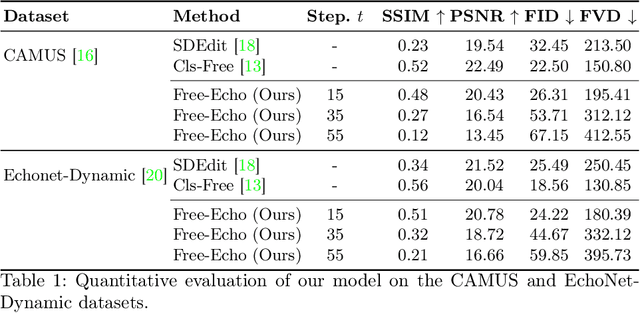
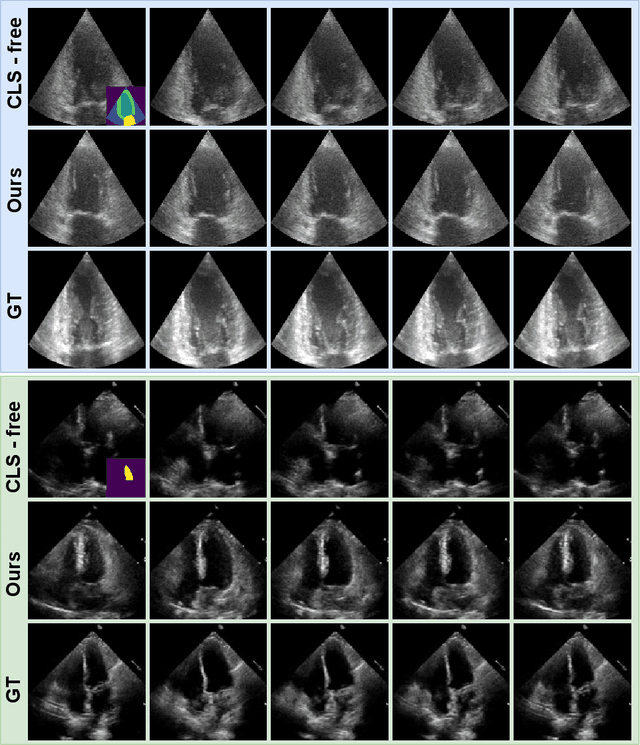
Conditional video diffusion models (CDM) have shown promising results for video synthesis, potentially enabling the generation of realistic echocardiograms to address the problem of data scarcity. However, current CDMs require a paired segmentation map and echocardiogram dataset. We present a new method called Free-Echo for generating realistic echocardiograms from a single end-diastolic segmentation map without additional training data. Our method is based on the 3D-Unet with Temporal Attention Layers model and is conditioned on the segmentation map using a training-free conditioning method based on SDEdit. We evaluate our model on two public echocardiogram datasets, CAMUS and EchoNet-Dynamic. We show that our model can generate plausible echocardiograms that are spatially aligned with the input segmentation map, achieving performance comparable to training-based CDMs. Our work opens up new possibilities for generating echocardiograms from a single segmentation map, which can be used for data augmentation, domain adaptation, and other applications in medical imaging. Our code is available at \url{https://github.com/gungui98/echo-free}