 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusion and Cross-Modal Transfer for Zero-Shot Human Action Recognition
Jul 23, 2024



Despite living in a multi-sensory world, most AI models are limited to textual and visual interpretations of human motion and behavior. Inertial measurement units (IMUs) provide a salient signal to understand human motion; however, they are challenging to use due to their uninterpretability and scarcity of their data. We investigate a method to transfer knowledge between visual and inertial modalities using the structure of an informative joint representation space designed for human action recognition (HAR). We apply the resulting Fusion and Cross-modal Transfer (FACT) method to a novel setup, where the model does not have access to labeled IMU data during training and is able to perform HAR with only IMU data during testing. Extensive experiments on a wide range of RGB-IMU datasets demonstrate that FACT significantly outperforms existing methods in zero-shot cross-modal transfer.
Learning Robust and Consistent Time Series Representations: A Dilated Inception-Based Approach
Jun 11, 2023



Representation learning for time series has been an important research area for decades. Since the emergence of the foundation models, this topic has attracted a lot of attention in contrastive self-supervised learning, to solve a wide range of downstream tasks. However, there have been several challenges for contrastive time series processing. First, there is no work considering noise, which is one of the critical factors affecting the efficacy of time series tasks. Second, there is a lack of efficient yet lightweight encoder architectures that can learn informative representations robust to various downstream tasks. To fill in these gaps, we initiate a novel sampling strategy that promotes consistent representation learning with the presence of noise in natural time series. In addition, we propose an encoder architecture that utilizes dilated convolution within the Inception block to create a scalable and robust network architecture with a wide receptive field. Experiments demonstrate that our method consistently outperforms state-of-the-art methods in forecasting, classification, and abnormality detection tasks, e.g. ranks first over two-thirds of the classification UCR datasets, with only $40\%$ of the parameters compared to the second-best approach. Our source code for CoInception framework is accessible at https://github.com/anhduy0911/CoInception.
FedGrad: Mitigating Backdoor Attacks in Federated Learning Through Local Ultimate Gradients Inspection
Apr 29, 2023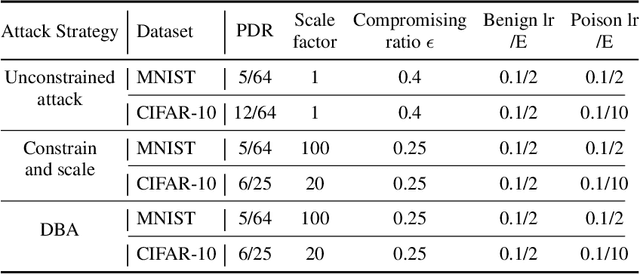
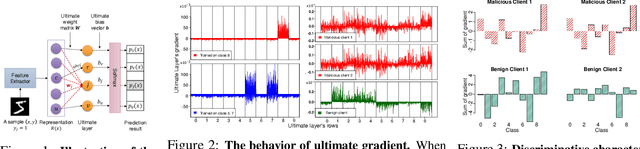
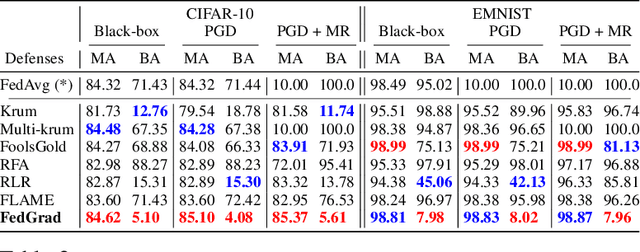
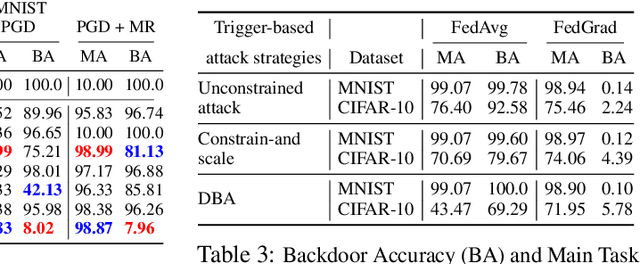
Federated learning (FL) enables multiple clients to train a model without compromising sensitive data. The decentralized nature of FL makes it susceptible to adversarial attacks, especially backdoor insertion during training. Recently, the edge-case backdoor attack employing the tail of the data distribution has been proposed as a powerful one, raising questions about the shortfall in current defenses' robustness guarantees. Specifically, most existing defenses cannot eliminate edge-case backdoor attacks or suffer from a trade-off between backdoor-defending effectiveness and overall performance on the primary task. To tackle this challenge, we propose FedGrad, a novel backdoor-resistant defense for FL that is resistant to cutting-edge backdoor attacks, including the edge-case attack, and performs effectively under heterogeneous client data and a large number of compromised clients. FedGrad is designed as a two-layer filtering mechanism that thoroughly analyzes the ultimate layer's gradient to identify suspicious local updates and remove them from the aggregation process. We evaluate FedGrad under different attack scenarios and show that it significantly outperforms state-of-the-art defense mechanisms. Notably, FedGrad can almost 100% correctly detect the malicious participants, thus providing a significant reduction in the backdoor effect (e.g., backdoor accuracy is less than 8%) while not reducing the main accuracy on the primary task.
High Accurate and Explainable Multi-Pill Detection Framework with Graph Neural Network-Assisted Multimodal Data Fusion
Mar 17, 2023


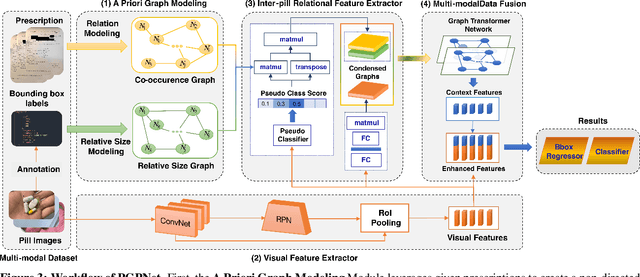
Due to the significant resemblance in visual appearance, pill misuse is prevalent and has become a critical issue, responsible for one-third of all deaths worldwide. Pill identification, thus, is a crucial concern needed to be investigated thoroughly. Recently, several attempts have been made to exploit deep learning to tackle the pill identification problem. However, most published works consider only single-pill identification and fail to distinguish hard samples with identical appearances. Also, most existing pill image datasets only feature single pill images captured in carefully controlled environments under ideal lighting conditions and clean backgrounds. In this work, we are the first to tackle the multi-pill detection problem in real-world settings, aiming at localizing and identifying pills captured by users in a pill intake. Moreover, we also introduce a multi-pill image dataset taken in unconstrained conditions. To handle hard samples, we propose a novel method for constructing heterogeneous a priori graphs incorporating three forms of inter-pill relationships, including co-occurrence likelihood, relative size, and visual semantic correlation. We then offer a framework for integrating a priori with pills' visual features to enhance detection accuracy. Our experimental results have proved the robustness, reliability, and explainability of the proposed framework. Experimentally, it outperforms all detection benchmarks in terms of all evaluation metrics. Specifically, our proposed framework improves COCO mAP metrics by 9.4% over Faster R-CNN and 12.0% compared to vanilla YOLOv5. Our study opens up new opportunities for protecting patients from medication errors using an AI-based pill identification solution.
Image-based Contextual Pill Recognition with Medical Knowledge Graph Assistance
Aug 09, 2022

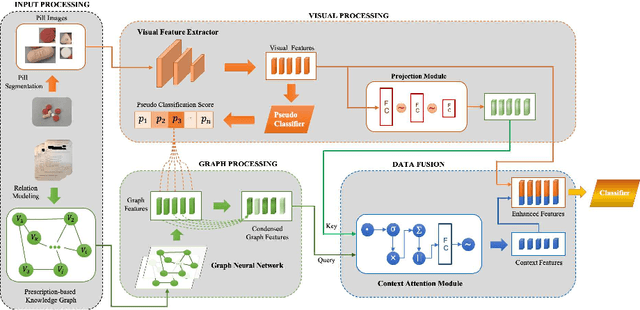
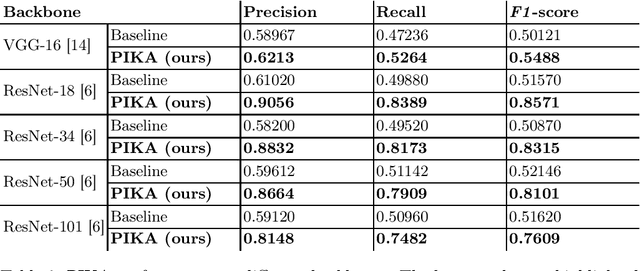
Identifying pills given their captured images under various conditions and backgrounds has been becoming more and more essential. Several efforts have been devoted to utilizing the deep learning-based approach to tackle the pill recognition problem in the literature. However, due to the high similarity between pills' appearance, misrecognition often occurs, leaving pill recognition a challenge. To this end, in this paper, we introduce a novel approach named PIKA that leverages external knowledge to enhance pill recognition accuracy. Specifically, we address a practical scenario (which we call contextual pill recognition), aiming to identify pills in a picture of a patient's pill intake. Firstly, we propose a novel method for modeling the implicit association between pills in the presence of an external data source, in this case, prescriptions. Secondly, we present a walk-based graph embedding model that transforms from the graph space to vector space and extracts condensed relational features of the pills. Thirdly, a final framework is provided that leverages both image-based visual and graph-based relational features to accomplish the pill identification task. Within this framework, the visual representation of each pill is mapped to the graph embedding space, which is then used to execute attention over the graph representation, resulting in a semantically-rich context vector that aids in the final classification. To our knowledge, this is the first study to use external prescription data to establish associations between medicines and to classify them using this aiding information. The architecture of PIKA is lightweight and has the flexibility to incorporate into any recognition backbones. The experimental results show that by leveraging the external knowledge graph, PIKA can improve the recognition accuracy from 4.8% to 34.1% in terms of F1-score, compared to baselines.
A Generalised Seizure Prediction with Convolutional Neural Networks for Intracranial and Scalp Electroencephalogram Data Analysis
Dec 06, 2017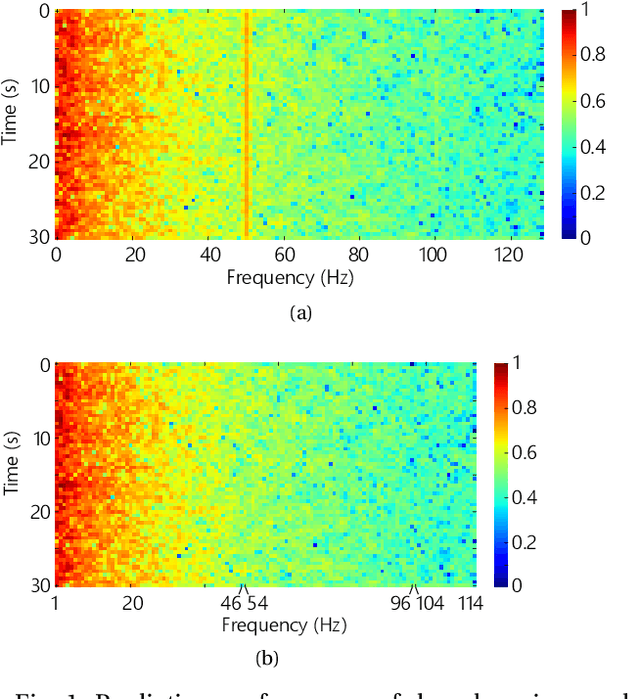
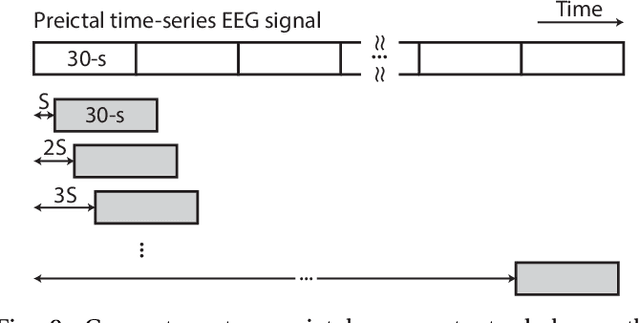
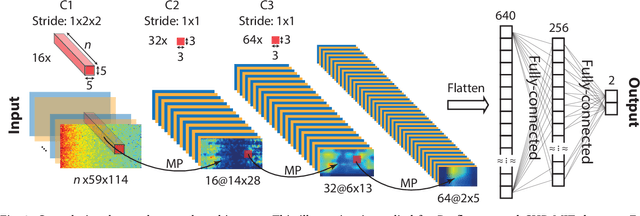

Seizure prediction has attracted a growing attention as one of the most challenging predictive data analysis efforts in order to improve the life of patients living with drug-resistant epilepsy and tonic seizures. Many outstanding works have been reporting great results in providing a sensible indirect (warning systems) or direct (interactive neural-stimulation) control over refractory seizures, some of which achieved high performance. However, many works put heavily handcraft feature extraction and/or carefully tailored feature engineering to each patient to achieve very high sensitivity and low false prediction rate for a particular dataset. This limits the benefit of their approaches if a different dataset is used. In this paper we apply Convolutional Neural Networks (CNNs) on different intracranial and scalp electroencephalogram (EEG) datasets and proposed a generalized retrospective and patient-specific seizure prediction method. We use Short-Time Fourier Transform (STFT) on 30-second EEG windows with 50% overlapping to extract information in both frequency and time domains. A standardization step is then applied on STFT components across the whole frequency range to prevent high frequencies features being influenced by those at lower frequencies. A convolutional neural network model is used for both feature extraction and classification to separate preictal segments from interictal ones. The proposed approach achieves sensitivity of 81.4%, 81.2%, 82.3% and false prediction rate (FPR) of 0.06/h, 0.16/h, 0.22/h on Freiburg Hospital intracranial EEG (iEEG) dataset, Children's Hospital of Boston-MIT scalp EEG (sEEG) dataset, and Kaggle American Epilepsy Society Seizure Prediction Challenge's dataset, respectively. Our prediction method is also statistically better than an unspecific random predictor for most of patients in all three datasets.