 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobult: Leveraging Redundancy and Modality Specific Features for Robust Multimodal Learning
Sep 03, 2025Addressing missing modalities and limited labeled data is crucial for advancing robust multimodal learning. We propose Robult, a scalable framework designed to mitigate these challenges by preserving modality-specific information and leveraging redundancy through a novel information-theoretic approach. Robult optimizes two core objectives: (1) a soft Positive-Unlabeled (PU) contrastive loss that maximizes task-relevant feature alignment while effectively utilizing limited labeled data in semi-supervised settings, and (2) a latent reconstruction loss that ensures unique modality-specific information is retained. These strategies, embedded within a modular design, enhance performance across various downstream tasks and ensure resilience to incomplete modalities during inference. Experimental results across diverse datasets validate that Robult achieves superior performance over existing approaches in both semi-supervised learning and missing modality contexts. Furthermore, its lightweight design promotes scalability and seamless integration with existing architectures, making it suitable for real-world multimodal applications.
Leveraging Perfect Multimodal Alignment and Gaussian Assumptions for Cross-modal Transfer
Mar 19, 2025Multimodal alignment aims to construct a joint latent vector space where two modalities representing the same concept map to the same vector. We formulate this as an inverse problem and show that under certain conditions perfect alignment can be achieved. We then address a specific application of alignment referred to as cross-modal transfer. Unsupervised cross-modal transfer aims to leverage a model trained with one modality to perform inference on another modality, without any labeled fine-tuning on the new modality. Assuming that semantic classes are represented as a mixture of Gaussians in the latent space, we show how cross-modal transfer can be performed by projecting the data points from the representation space onto different subspaces representing each modality. Our experiments on synthetic multimodal Gaussian data verify the effectiveness of our perfect alignment and cross-modal transfer method. We hope these findings inspire further exploration of the applications of perfect alignment and the use of Gaussian models for cross-modal learning.
Fusion and Cross-Modal Transfer for Zero-Shot Human Action Recognition
Jul 23, 2024Despite living in a multi-sensory world, most AI models are limited to textual and visual interpretations of human motion and behavior. Inertial measurement units (IMUs) provide a salient signal to understand human motion; however, they are challenging to use due to their uninterpretability and scarcity of their data. We investigate a method to transfer knowledge between visual and inertial modalities using the structure of an informative joint representation space designed for human action recognition (HAR). We apply the resulting Fusion and Cross-modal Transfer (FACT) method to a novel setup, where the model does not have access to labeled IMU data during training and is able to perform HAR with only IMU data during testing. Extensive experiments on a wide range of RGB-IMU datasets demonstrate that FACT significantly outperforms existing methods in zero-shot cross-modal transfer.
The Progression of Transformers from Language to Vision to MOT: A Literature Review on Multi-Object Tracking with Transformers
Jun 24, 2024The transformer neural network architecture allows for autoregressive sequence-to-sequence modeling through the use of attention layers. It was originally created with the application of machine translation but has revolutionized natural language processing. Recently, transformers have also been applied across a wide variety of pattern recognition tasks, particularly in computer vision. In this literature review, we describe major advances in computer vision utilizing transformers. We then focus specifically on Multi-Object Tracking (MOT) and discuss how transformers are increasingly becoming competitive in state-of-the-art MOT works, yet still lag behind traditional deep learning methods.
A Brief Survey on Leveraging Large Scale Vision Models for Enhanced Robot Grasping
Jun 17, 2024Robotic grasping presents a difficult motor task in real-world scenarios, constituting a major hurdle to the deployment of capable robots across various industries. Notably, the scarcity of data makes grasping particularly challenging for learned models. Recent advancements in computer vision have witnessed a growth of successful unsupervised training mechanisms predicated on massive amounts of data sourced from the Internet, and now nearly all prominent models leverage pretrained backbone networks. Against this backdrop, we begin to investigate the potential benefits of large-scale visual pretraining in enhancing robot grasping performance. This preliminary literature review sheds light on critical challenges and delineates prospective directions for future research in visual pretraining for robotic manipulation.
A Survey of IMU Based Cross-Modal Transfer Learning in Human Activity Recognition
Mar 17, 2024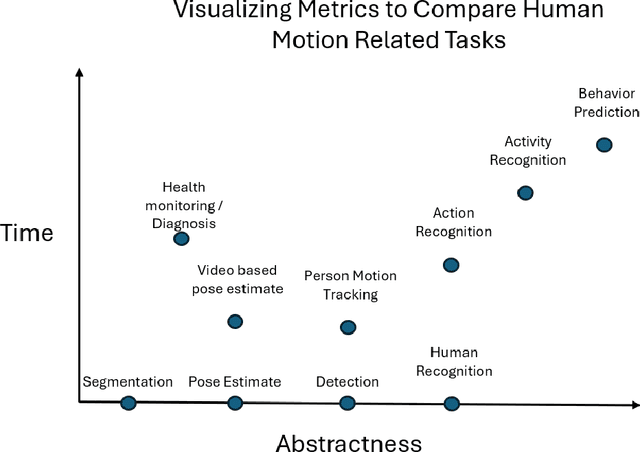
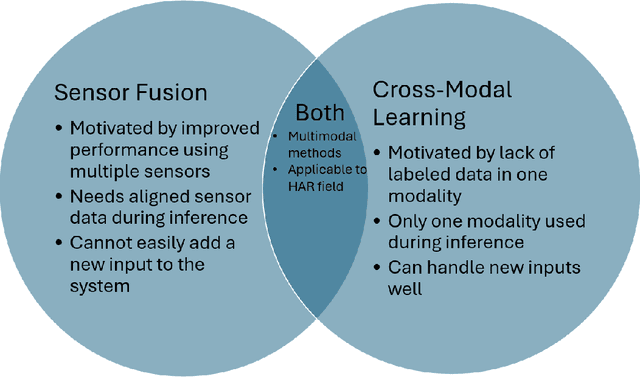

Despite living in a multi-sensory world, most AI models are limited to textual and visual understanding of human motion and behavior. In fact, full situational awareness of human motion could best be understood through a combination of sensors. In this survey we investigate how knowledge can be transferred and utilized amongst modalities for Human Activity/Action Recognition (HAR), i.e. cross-modality transfer learning. We motivate the importance and potential of IMU data and its applicability in cross-modality learning as well as the importance of studying the HAR problem. We categorize HAR related tasks by time and abstractness and then compare various types of multimodal HAR datasets. We also distinguish and expound on many related but inconsistently used terms in the literature, such as transfer learning, domain adaptation, representation learning, sensor fusion, and multimodal learning, and describe how cross-modal learning fits with all these concepts. We then review the literature in IMU-based cross-modal transfer for HAR. The two main approaches for cross-modal transfer are instance-based transfer, where instances of one modality are mapped to another (e.g. knowledge is transferred in the input space), or feature-based transfer, where the model relates the modalities in an intermediate latent space (e.g. knowledge is transferred in the feature space). Finally, we discuss future research directions and applications in cross-modal HAR.
Examining Audio Communication Mechanisms for Supervising Fleets of Agricultural Robots
Aug 22, 2022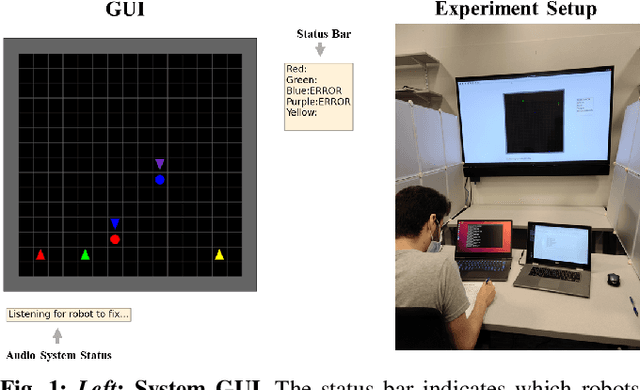
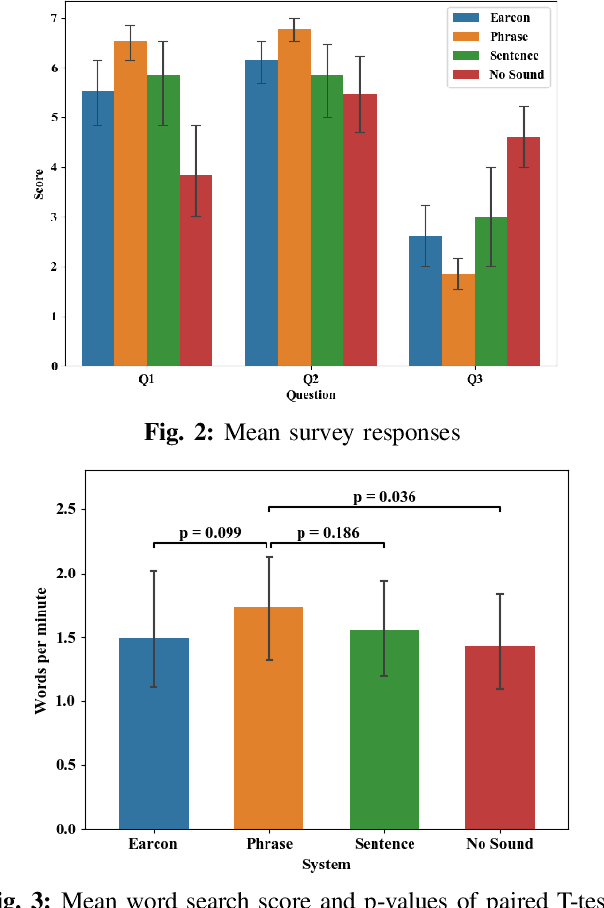

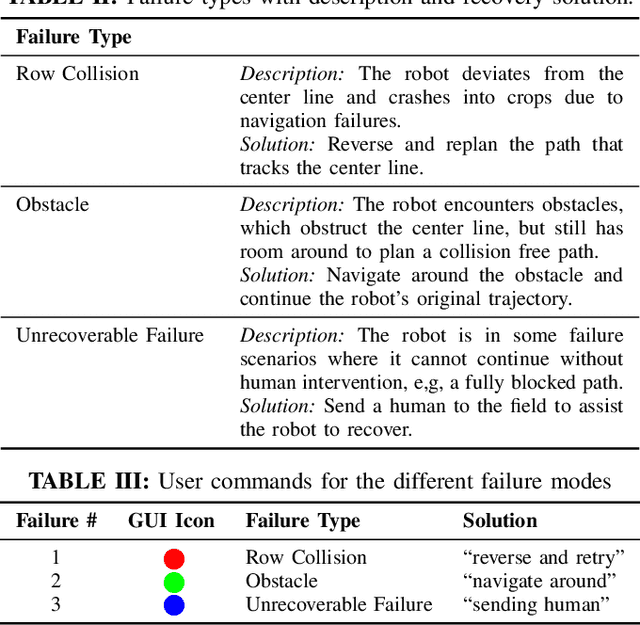
Agriculture is facing a labor crisis, leading to increased interest in fleets of small, under-canopy robots (agbots) that can perform precise, targeted actions (e.g., crop scouting, weeding, fertilization), while being supervised by human operators remotely. However, farmers are not necessarily experts in robotics technology and will not adopt technologies that add to their workload or do not provide an immediate payoff. In this work, we explore methods for communication between a remote human operator and multiple agbots and examine the impact of audio communication on the operator's preferences and productivity. We develop a simulation platform where agbots are deployed across a field, randomly encounter failures, and call for help from the operator. As the agbots report errors, various audio communication mechanisms are tested to convey which robot failed and what type of failure occurs. The human is tasked with verbally diagnosing the failure while completing a secondary task. A user study was conducted to test three audio communication methods: earcons, single-phrase commands, and full sentence communication. Each participant completed a survey to determine their preferences and each method's overall effectiveness. Our results suggest that the system using single phrases is the most positively perceived by participants and may allow for the human to complete the secondary task more efficiently. The code is available at: https://github.com/akamboj2/Agbot-Sim.