 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExamining Audio Communication Mechanisms for Supervising Fleets of Agricultural Robots
Aug 22, 2022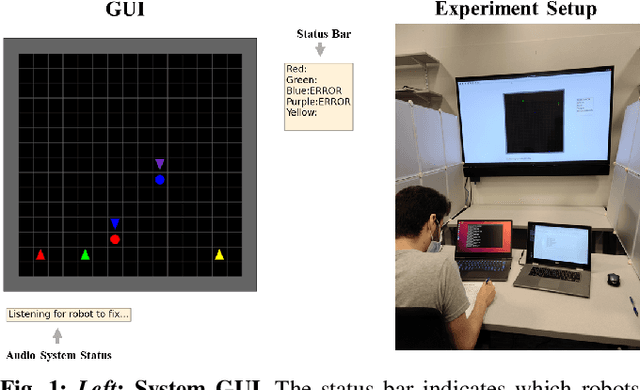
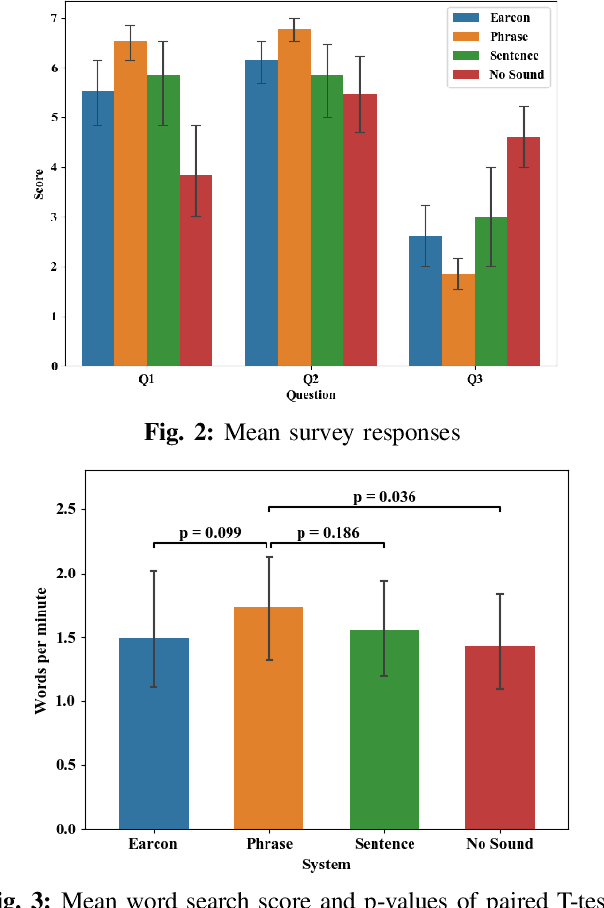

Agriculture is facing a labor crisis, leading to increased interest in fleets of small, under-canopy robots (agbots) that can perform precise, targeted actions (e.g., crop scouting, weeding, fertilization), while being supervised by human operators remotely. However, farmers are not necessarily experts in robotics technology and will not adopt technologies that add to their workload or do not provide an immediate payoff. In this work, we explore methods for communication between a remote human operator and multiple agbots and examine the impact of audio communication on the operator's preferences and productivity. We develop a simulation platform where agbots are deployed across a field, randomly encounter failures, and call for help from the operator. As the agbots report errors, various audio communication mechanisms are tested to convey which robot failed and what type of failure occurs. The human is tasked with verbally diagnosing the failure while completing a secondary task. A user study was conducted to test three audio communication methods: earcons, single-phrase commands, and full sentence communication. Each participant completed a survey to determine their preferences and each method's overall effectiveness. Our results suggest that the system using single phrases is the most positively perceived by participants and may allow for the human to complete the secondary task more efficiently. The code is available at: https://github.com/akamboj2/Agbot-Sim.
CoCAtt: A Cognitive-Conditioned Driver Attention Dataset
Nov 23, 2021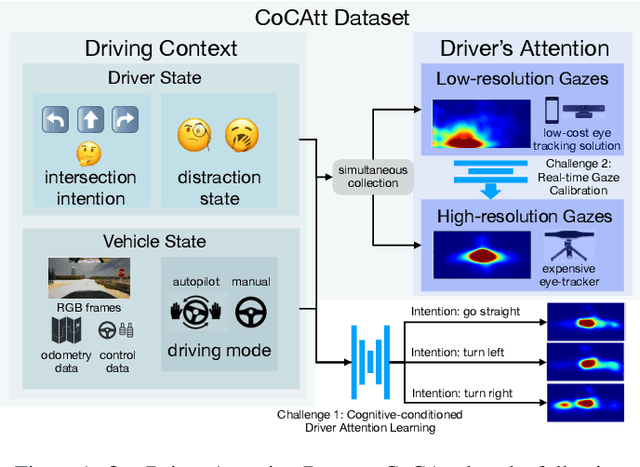



The task of driver attention prediction has drawn considerable interest among researchers in robotics and the autonomous vehicle industry. Driver attention prediction can play an instrumental role in mitigating and preventing high-risk events, like collisions and casualties. However, existing driver attention prediction models neglect the distraction state and intention of the driver, which can significantly influence how they observe their surroundings. To address these issues, we present a new driver attention dataset, CoCAtt (Cognitive-Conditioned Attention). Unlike previous driver attention datasets, CoCAtt includes per-frame annotations that describe the distraction state and intention of the driver. In addition, the attention data in our dataset is captured in both manual and autopilot modes using eye-tracking devices of different resolutions. Our results demonstrate that incorporating the above two driver states into attention modeling can improve the performance of driver attention prediction. To the best of our knowledge, this work is the first to provide autopilot attention data. Furthermore, CoCAtt is currently the largest and the most diverse driver attention dataset in terms of autonomy levels, eye tracker resolutions, and driving scenarios.