 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoCAtt: A Cognitive-Conditioned Driver Attention Dataset (Supplementary Material)
Jul 08, 2022
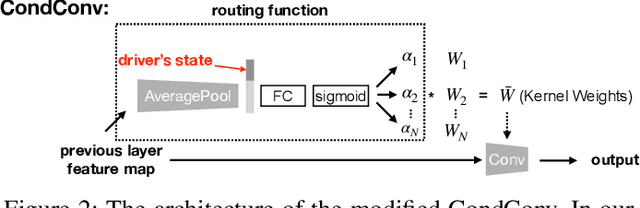
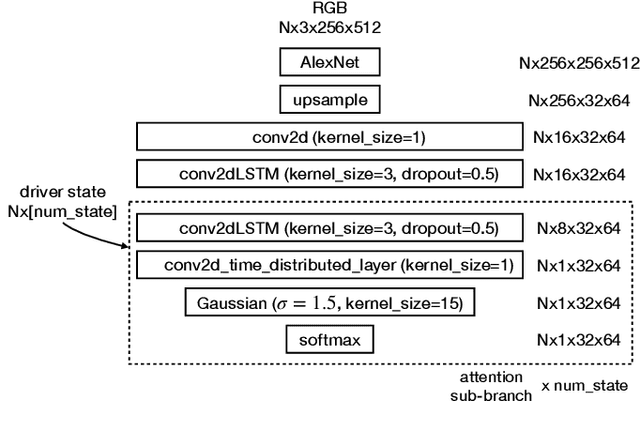

The task of driver attention prediction has drawn considerable interest among researchers in robotics and the autonomous vehicle industry. Driver attention prediction can play an instrumental role in mitigating and preventing high-risk events, like collisions and casualties. However, existing driver attention prediction models neglect the distraction state and intention of the driver, which can significantly influence how they observe their surroundings. To address these issues, we present a new driver attention dataset, CoCAtt (Cognitive-Conditioned Attention). Unlike previous driver attention datasets, CoCAtt includes per-frame annotations that describe the distraction state and intention of the driver. In addition, the attention data in our dataset is captured in both manual and autopilot modes using eye-tracking devices of different resolutions. Our results demonstrate that incorporating the above two driver states into attention modeling can improve the performance of driver attention prediction. To the best of our knowledge, this work is the first to provide autopilot attention data. Furthermore, CoCAtt is currently the largest and the most diverse driver attention dataset in terms of autonomy levels, eye tracker resolutions, and driving scenarios. CoCAtt is available for download at https://cocatt-dataset.github.io.
Meta-path Analysis on Spatio-Temporal Graphs for Pedestrian Trajectory Prediction
Feb 27, 2022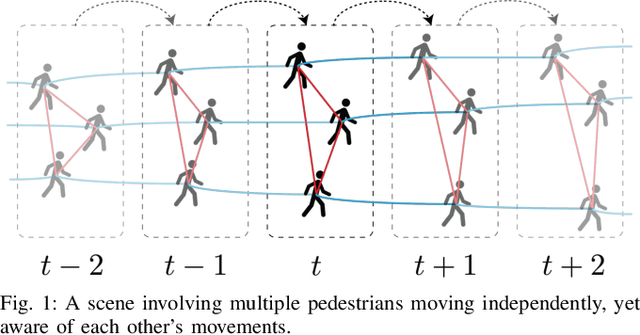
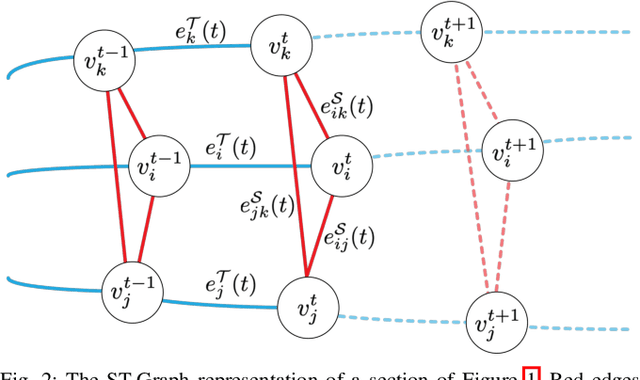
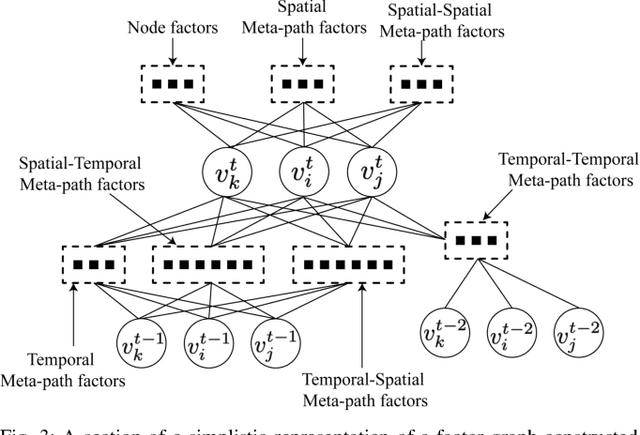
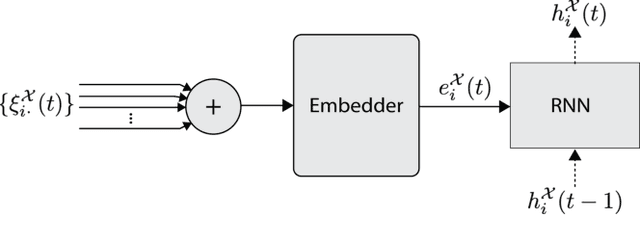
Spatio-temporal graphs (ST-graphs) have been used to model time series tasks such as traffic forecasting, human motion modeling, and action recognition. The high-level structure and corresponding features from ST-graphs have led to improved performance over traditional architectures. However, current methods tend to be limited by simple features, despite the rich information provided by the full graph structure, which leads to inefficiencies and suboptimal performance in downstream tasks. We propose the use of features derived from meta-paths, walks across different types of edges, in ST-graphs to improve the performance of Structural Recurrent Neural Network. In this paper, we present the Meta-path Enhanced Structural Recurrent Neural Network (MESRNN), a generic framework that can be applied to any spatio-temporal task in a simple and scalable manner. We employ MESRNN for pedestrian trajectory prediction, utilizing these meta-path based features to capture the relationships between the trajectories of pedestrians at different points in time and space. We compare our MESRNN against state-of-the-art ST-graph methods on standard datasets to show the performance boost provided by meta-path information. The proposed model consistently outperforms the baselines in trajectory prediction over long time horizons by over 32\%, and produces more socially compliant trajectories in dense crowds. For more information please refer to the project website at https://sites.google.com/illinois.edu/mesrnn/home.
CoCAtt: A Cognitive-Conditioned Driver Attention Dataset
Nov 23, 2021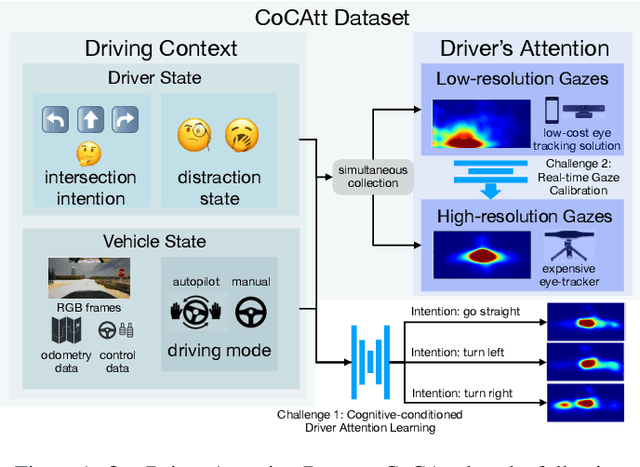



The task of driver attention prediction has drawn considerable interest among researchers in robotics and the autonomous vehicle industry. Driver attention prediction can play an instrumental role in mitigating and preventing high-risk events, like collisions and casualties. However, existing driver attention prediction models neglect the distraction state and intention of the driver, which can significantly influence how they observe their surroundings. To address these issues, we present a new driver attention dataset, CoCAtt (Cognitive-Conditioned Attention). Unlike previous driver attention datasets, CoCAtt includes per-frame annotations that describe the distraction state and intention of the driver. In addition, the attention data in our dataset is captured in both manual and autopilot modes using eye-tracking devices of different resolutions. Our results demonstrate that incorporating the above two driver states into attention modeling can improve the performance of driver attention prediction. To the best of our knowledge, this work is the first to provide autopilot attention data. Furthermore, CoCAtt is currently the largest and the most diverse driver attention dataset in terms of autonomy levels, eye tracker resolutions, and driving scenarios.