 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutodecompose: A generative self-supervised model for semantic decomposition
Feb 13, 2023



We introduce Autodecompose, a novel self-supervised generative model that decomposes data into two semantically independent properties: the desired property, which captures a specific aspect of the data (e.g. the voice in an audio signal), and the context property, which aggregates all other information (e.g. the content of the audio signal), without any labels given. Autodecompose uses two complementary augmentations, one that manipulates the context while preserving the desired property and the other that manipulates the desired property while preserving the context. The augmented variants of the data are encoded by two encoders and reconstructed by a decoder. We prove that one of the encoders embeds the desired property while the other embeds the context property. We apply Autodecompose to audio signals to encode sound source (human voice) and content. We pre-trained the model on YouTube and LibriSpeech datasets and fine-tuned in a self-supervised manner without exposing the labels. Our results showed that, using the sound source encoder of pre-trained Autodecompose, a linear classifier achieves F1 score of 97.6\% in recognizing the voice of 30 speakers using only 10 seconds of labeled samples, compared to 95.7\% for supervised models. Additionally, our experiments showed that Autodecompose is robust against overfitting even when a large model is pre-trained on a small dataset. A large Autodecompose model was pre-trained from scratch on 60 seconds of audio from 3 speakers achieved over 98.5\% F1 score in recognizing those three speakers in other unseen utterances. We finally show that the context encoder embeds information about the content of the speech and ignores the sound source information. Our sample code for training the model, as well as examples for using the pre-trained models are available here: \url{https://github.com/rezabonyadi/autodecompose}
Self Punishment and Reward Backfill for Deep Q-Learning
Apr 10, 2020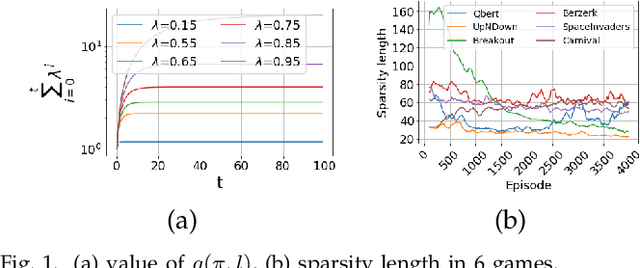

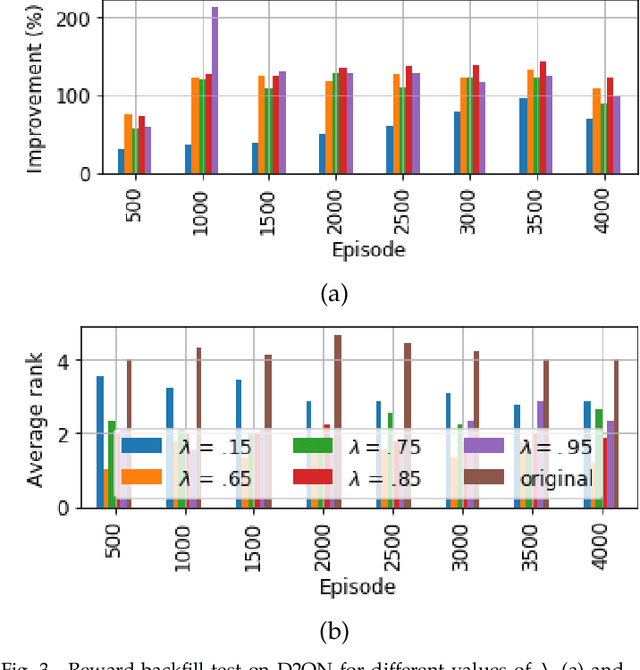

Reinforcement learning agents learn by encouraging behaviours which maximize their total reward, usually provided by the environment. In many environments, however, the reward is provided after a series of actions rather than each single action, causing the agent to experience ambiguity in terms of whether those actions are effective, an issue called the credit assignment problem. In this paper, we propose two strategies, inspired by behavioural psychology, to estimate a more informative reward value for actions with no reward. The first strategy, called self-punishment, discourages the agent to avoid making mistakes, i.e., actions which lead to a terminal state. The second strategy, called the rewards backfill, backpropagates the rewards between two rewarded actions. We prove that, under certain assumptions, these two strategies maintain the order of the policies in the space of all possible policies in terms of their total reward, and, by extension, maintain the optimal policy. We incorporated these two strategies into three popular deep reinforcement learning approaches and evaluated the results on thirty Atari games. After parameter tuning, our results indicate that the proposed strategies improve the tested methods in over 65 percent of tested games by up to over 25 times performance improvement.
Semi-supervised Seizure Prediction with Generative Adversarial Networks
Jun 20, 2018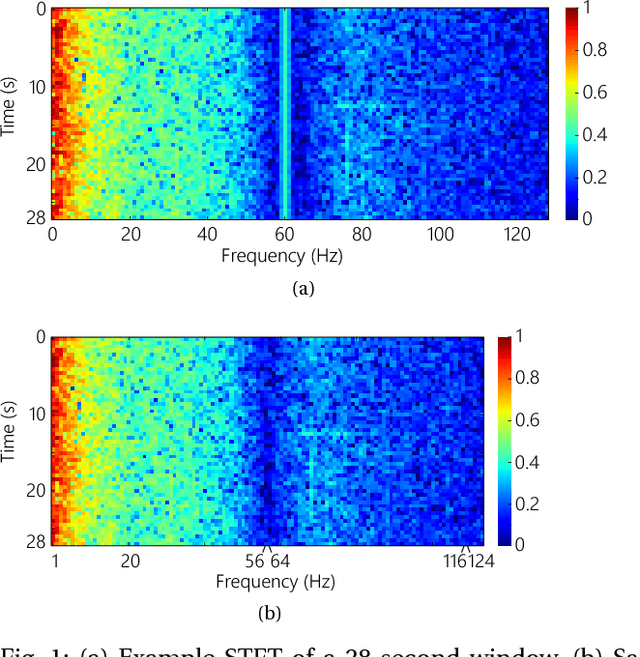
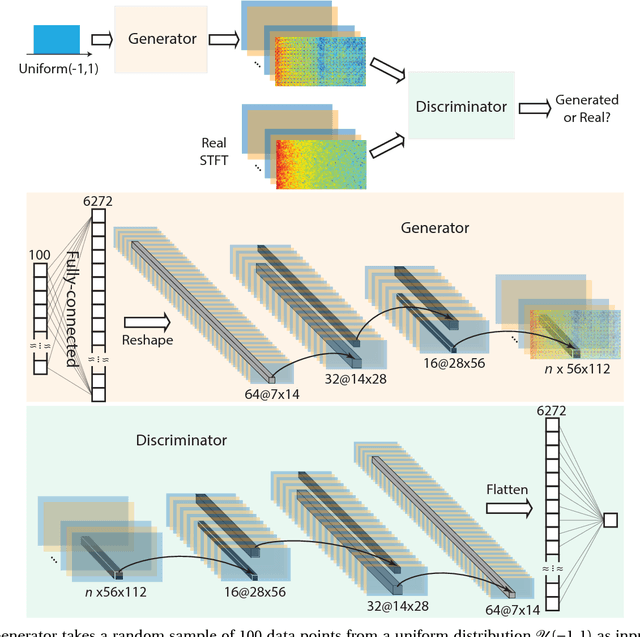
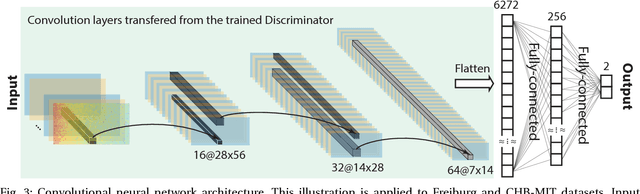
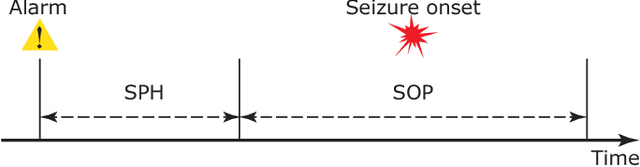
In this article, we propose an approach that can make use of not only labeled EEG signals but also the unlabeled ones which is more accessible. We also suggest the use of data fusion to further improve the seizure prediction accuracy. Data fusion in our vision includes EEG signals, cardiogram signals, body temperature and time. We use the short-time Fourier transform on 28-s EEG windows as a pre-processing step. A generative adversarial network (GAN) is trained in an unsupervised manner where information of seizure onset is disregarded. The trained Discriminator of the GAN is then used as feature extractor. Features generated by the feature extractor are classified by two fully-connected layers (can be replaced by any classifier) for the labeled EEG signals. This semi-supervised seizure prediction method achieves area under the operating characteristic curve (AUC) of 77.68% and 75.47% for the CHBMIT scalp EEG dataset and the Freiburg Hospital intracranial EEG dataset, respectively. Unsupervised training without the need of labeling is important because not only it can be performed in real-time during EEG signal recording, but also it does not require feature engineering effort for each patient.
Optimal-margin evolutionary classifier
Apr 26, 2018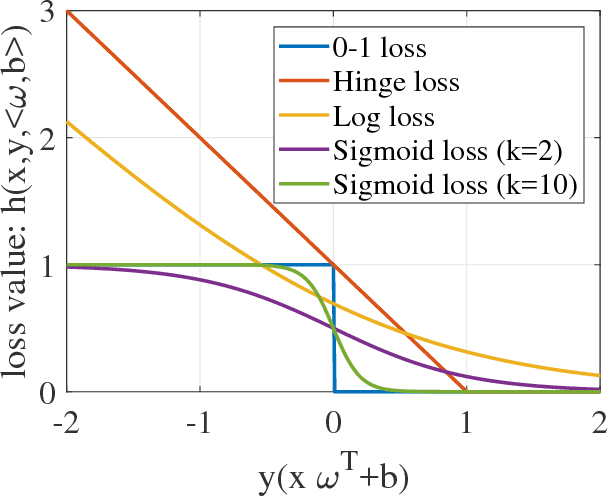

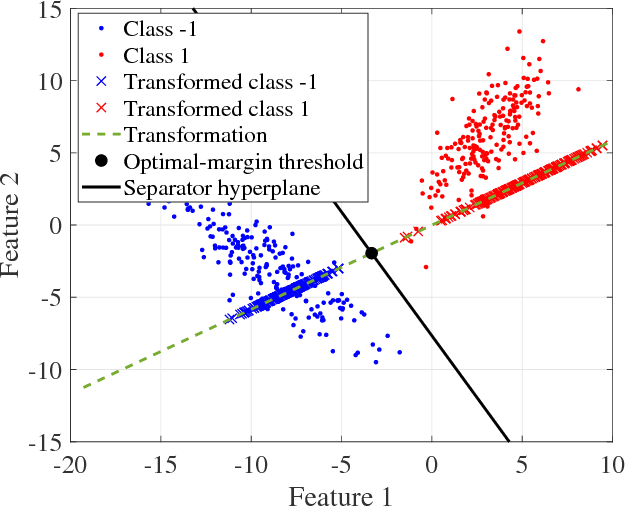
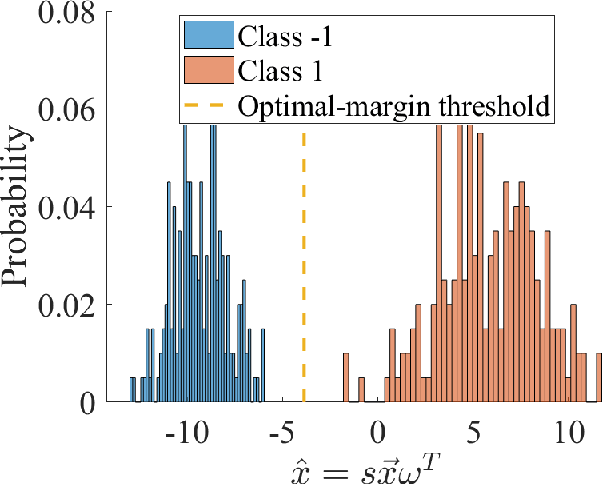
We introduce a novel approach for discriminative classification using evolutionary algorithms. We first propose an algorithm to optimize the total loss value using a modified 0-1 loss function in a one-dimensional space for classification. We then extend this algorithm for multi-dimensional classification using an evolutionary algorithm. The proposed evolutionary algorithm aims to find a hyperplane which best classifies instances while minimizes the classification risk. We test particle swarm optimization, evolutionary strategy, and covariance matrix adaptation evolutionary strategy for optimization purpose. Finally, we compare our results with well-established and state-of-the-art classification algorithms, for both binary and multi-class classification, on 19 benchmark classification problems, with and without noise and outliers. Results show that the performance of the proposed algorithm is significantly (t-test) better than all other methods in almost all problems tested. We also show that the proposed algorithm is significantly more robust against noise and outliers comparing to other methods. The running time of the algorithm is within a reasonable range for the solution of real-world classification problems.
A theoretical guideline for designing an effective adaptive particle swarm
Feb 13, 2018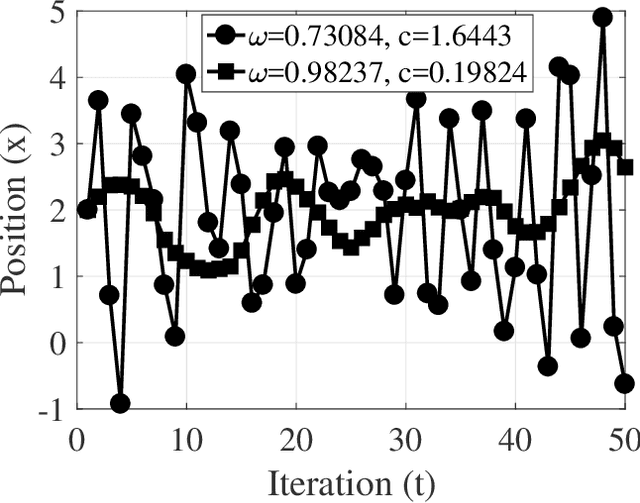


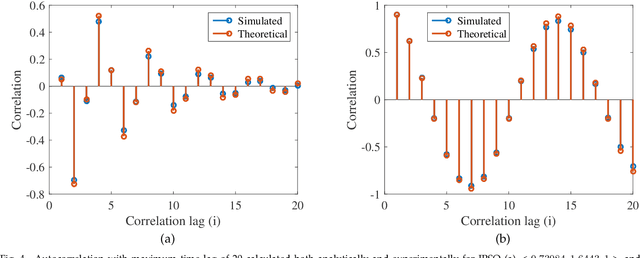
In this paper we theoretically investigate underlying assumptions that have been used for designing adaptive particle swarm optimization algorithms in the past years. We relate these assumptions to the movement patterns of particles controlled by coefficient values (inertia weight and acceleration coefficient) and introduce three factors, namely the autocorrelation of the particle positions, the average movement distance of the particle in each iteration, and the focus of the search, that describe these movement patterns. We show how these factors represent movement patterns of a particle within a swarm and how they are affected by particle coefficients (i.e., inertia weight and acceleration coefficients). We derive equations that provide exact coefficient values to guarantee achieving a desired movement pattern defined by these three factors within a swarm. We then relate these movements to the searching capability of particles and provide guideline for designing potentially successful adaptive methods to control coefficients in particle swarm. Finally, we propose a new simple time adaptive particle swarm and compare its results with previous adaptive particle swarm approaches. Our experiments show that the theoretical findings indeed provide a beneficial guideline for successful adaptation of the coefficients in the particle swarm optimization algorithm.
Linear centralization classifier
Dec 22, 2017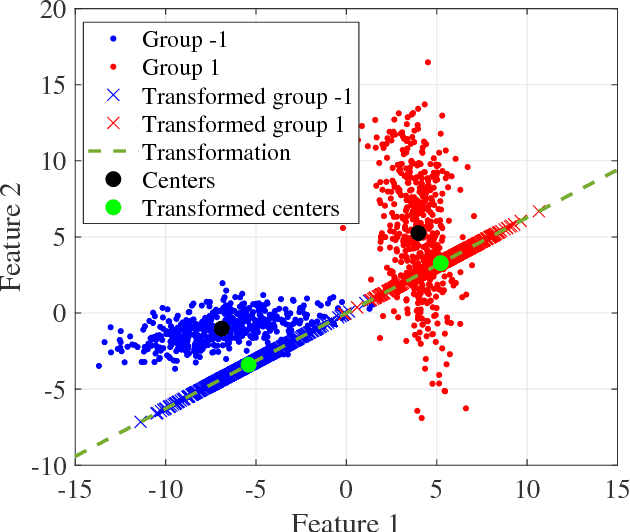
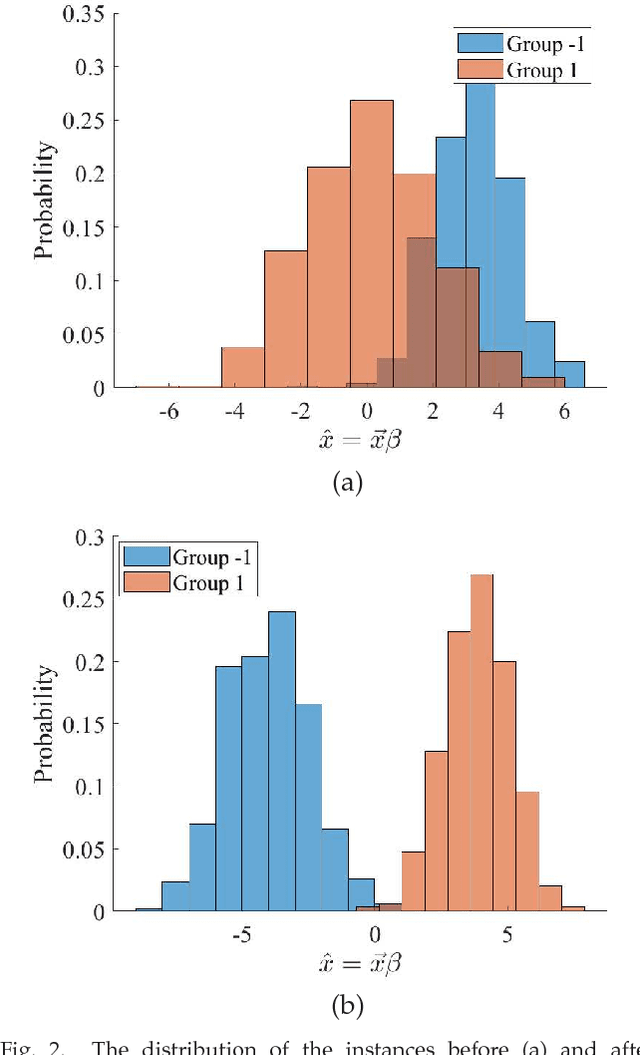
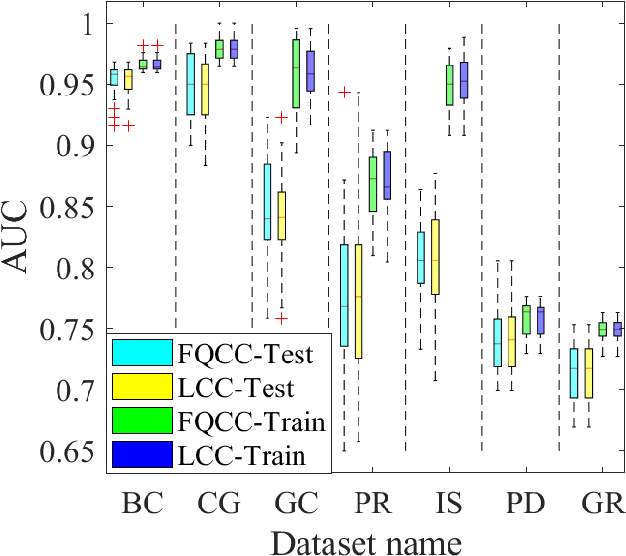
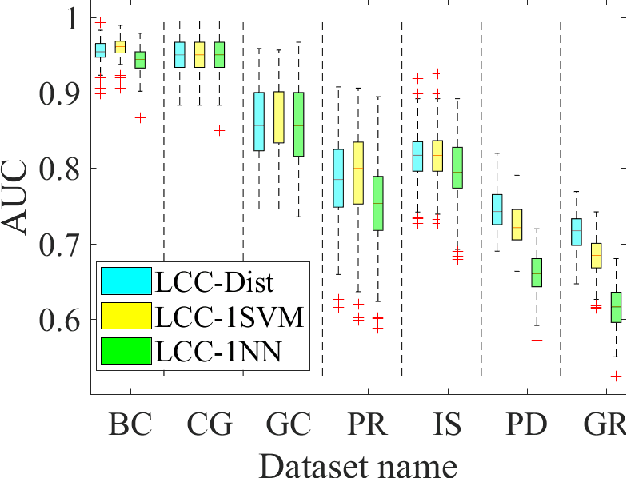
A classification algorithm, called the Linear Centralization Classifier (LCC), is introduced. The algorithm seeks to find a transformation that best maps instances from the feature space to a space where they concentrate towards the center of their own classes, while maximimizing the distance between class centers. We formulate the classifier as a quadratic program with quadratic constraints. We then simplify this formulation to a linear program that can be solved effectively using a linear programming solver (e.g., simplex-dual). We extend the formulation for LCC to enable the use of kernel functions for non-linear classification applications. We compare our method with two standard classification methods (support vector machine and linear discriminant analysis) and four state-of-the-art classification methods when they are applied to eight standard classification datasets. Our experimental results show that LCC is able to classify instances more accurately (based on the area under the receiver operating characteristic) in comparison to other tested methods on the chosen datasets. We also report the results for LCC with a particular kernel to solve for synthetic non-linear classification problems.
A Generalised Seizure Prediction with Convolutional Neural Networks for Intracranial and Scalp Electroencephalogram Data Analysis
Dec 06, 2017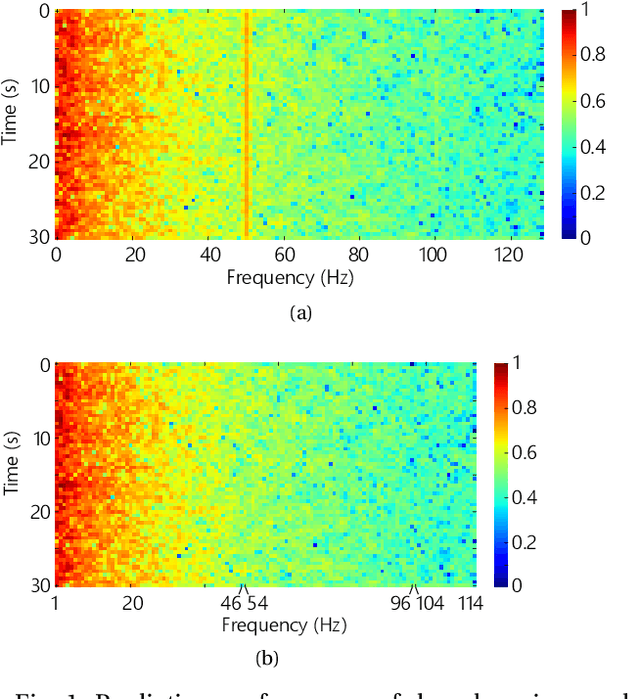
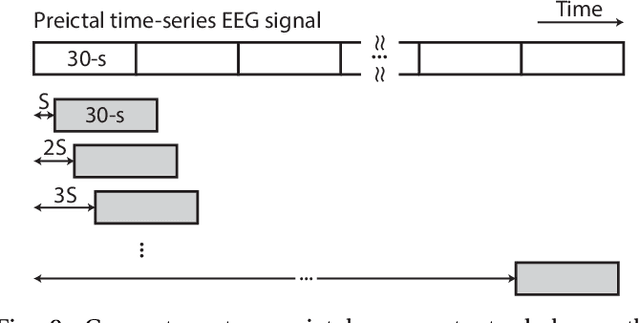
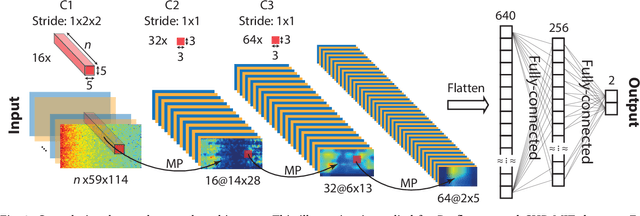

Seizure prediction has attracted a growing attention as one of the most challenging predictive data analysis efforts in order to improve the life of patients living with drug-resistant epilepsy and tonic seizures. Many outstanding works have been reporting great results in providing a sensible indirect (warning systems) or direct (interactive neural-stimulation) control over refractory seizures, some of which achieved high performance. However, many works put heavily handcraft feature extraction and/or carefully tailored feature engineering to each patient to achieve very high sensitivity and low false prediction rate for a particular dataset. This limits the benefit of their approaches if a different dataset is used. In this paper we apply Convolutional Neural Networks (CNNs) on different intracranial and scalp electroencephalogram (EEG) datasets and proposed a generalized retrospective and patient-specific seizure prediction method. We use Short-Time Fourier Transform (STFT) on 30-second EEG windows with 50% overlapping to extract information in both frequency and time domains. A standardization step is then applied on STFT components across the whole frequency range to prevent high frequencies features being influenced by those at lower frequencies. A convolutional neural network model is used for both feature extraction and classification to separate preictal segments from interictal ones. The proposed approach achieves sensitivity of 81.4%, 81.2%, 82.3% and false prediction rate (FPR) of 0.06/h, 0.16/h, 0.22/h on Freiburg Hospital intracranial EEG (iEEG) dataset, Children's Hospital of Boston-MIT scalp EEG (sEEG) dataset, and Kaggle American Epilepsy Society Seizure Prediction Challenge's dataset, respectively. Our prediction method is also statistically better than an unspecific random predictor for most of patients in all three datasets.
Optimization of distributions differences for classification
Mar 02, 2017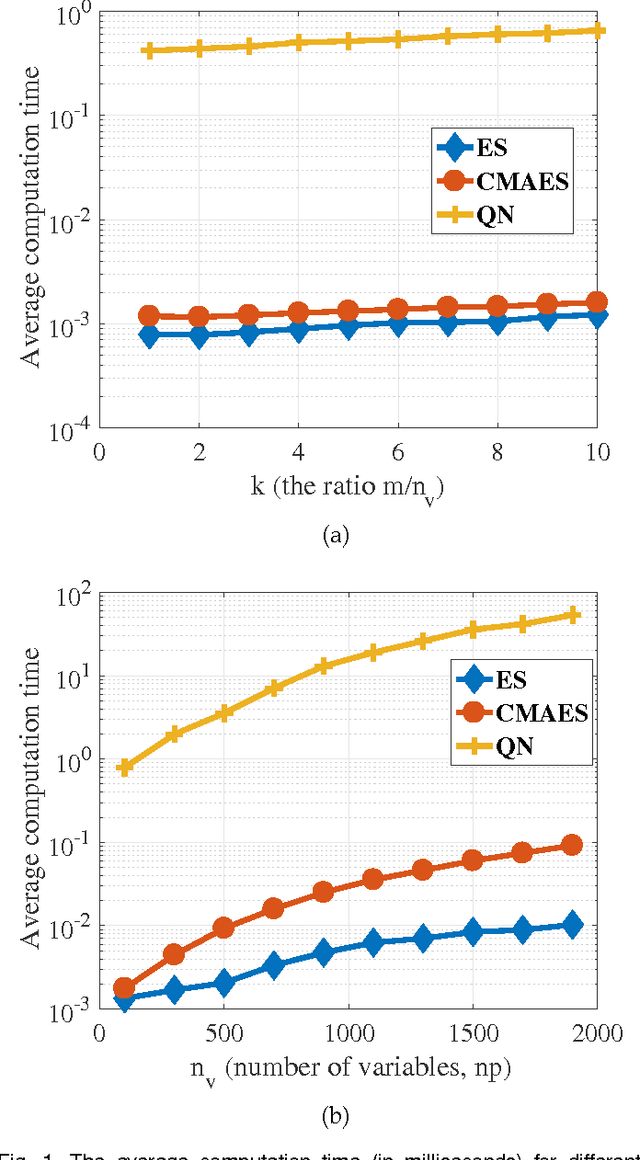
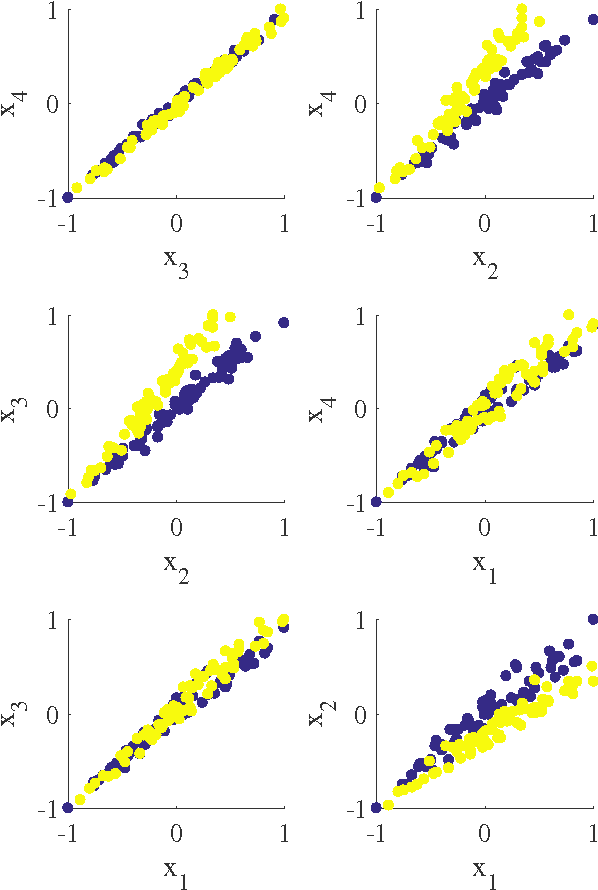
In this paper we introduce a new classification algorithm called Optimization of Distributions Differences (ODD). The algorithm aims to find a transformation from the feature space to a new space where the instances in the same class are as close as possible to one another while the gravity centers of these classes are as far as possible from one another. This aim is formulated as a multiobjective optimization problem that is solved by a hybrid of an evolutionary strategy and the Quasi-Newton method. The choice of the transformation function is flexible and could be any continuous space function. We experiment with a linear and a non-linear transformation in this paper. We show that the algorithm can outperform 6 other state-of-the-art classification methods, namely naive Bayes, support vector machines, linear discriminant analysis, multi-layer perceptrons, decision trees, and k-nearest neighbors, in 12 standard classification datasets. Our results show that the method is less sensitive to the imbalanced number of instances comparing to these methods. We also show that ODD maintains its performance better than other classification methods in these datasets, hence, offers a better generalization ability.
Supervised Learning in Automatic Channel Selection for Epileptic Seizure Detection
Jan 31, 2017
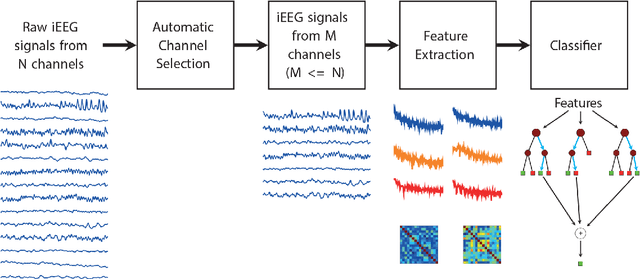

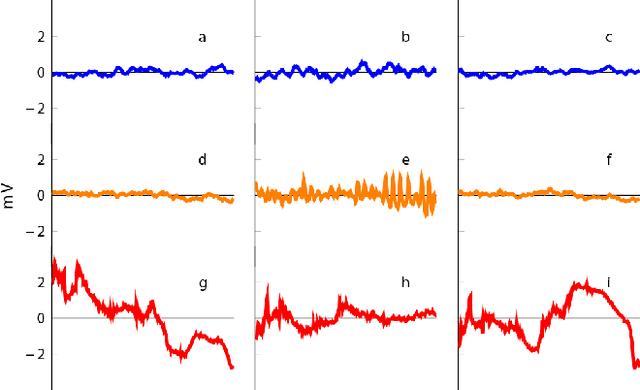
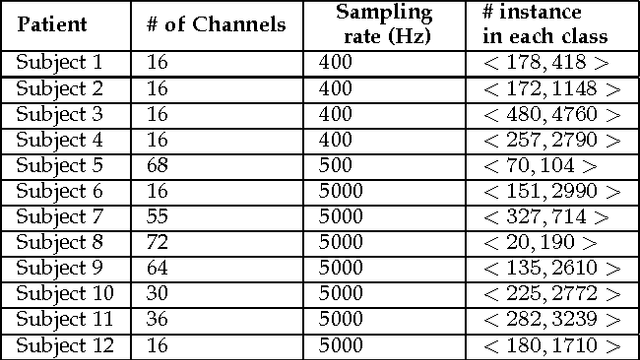
Detecting seizure using brain neuroactivations recorded by intracranial electroencephalogram (iEEG) has been widely used for monitoring, diagnosing, and closed-loop therapy of epileptic patients, however, computational efficiency gains are needed if state-of-the-art methods are to be implemented in implanted devices. We present a novel method for automatic seizure detection based on iEEG data that outperforms current state-of-the-art seizure detection methods in terms of computational efficiency while maintaining the accuracy. The proposed algorithm incorporates an automatic channel selection (ACS) engine as a pre-processing stage to the seizure detection procedure. The ACS engine consists of supervised classifiers which aim to find iEEGchannelswhich contribute the most to a seizure. Seizure detection stage involves feature extraction and classification. Feature extraction is performed in both frequency and time domains where spectral power and correlation between channel pairs are calculated. Random Forest is used in classification of interictal, ictal and early ictal periods of iEEG signals. Seizure detection in this paper is retrospective and patient-specific. iEEG data is accessed via Kaggle, provided by International Epilepsy Electro-physiology Portal. The dataset includes a training set of 6.5 hours of interictal data and 41 minin ictal data and a test set of 9.14 hours. Compared to the state-of-the-art on the same dataset, we achieve 49.4% increase in computational efficiency and 400 mins better in average for detection delay. The proposed model is able to detect a seizure onset at 91.95% sensitivity and 94.05% specificity with a mean detection delay of 2.77 s. The area under the curve (AUC) is 96.44%, that is comparable to the current state-of-the-art with AUC of 96.29%.
Evolutionary computation for multicomponent problems: opportunities and future directions
Jun 22, 2016
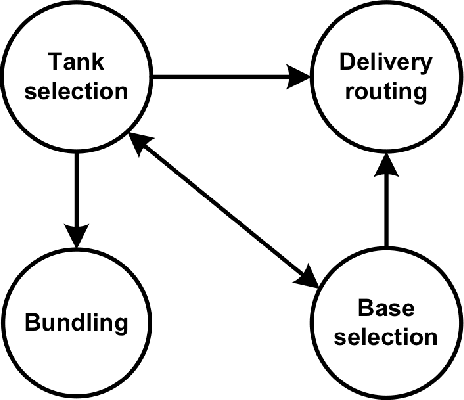
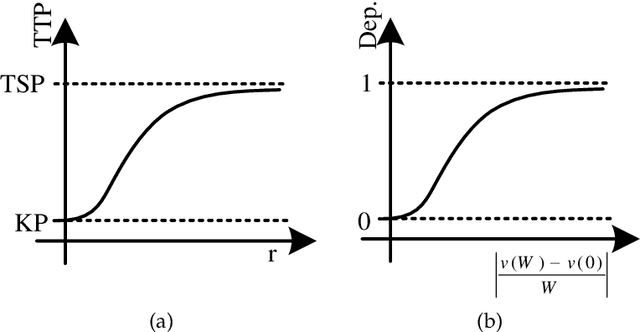
Over the past 30 years many researchers in the field of evolutionary computation have put a lot of effort to introduce various approaches for solving hard problems. Most of these problems have been inspired by major industries so that solving them, by providing either optimal or near optimal solution, was of major significance. Indeed, this was a very promising trajectory as advances in these problem-solving approaches could result in adding values to major industries. In this paper we revisit this trajectory to find out whether the attempts that started three decades ago are still aligned with the same goal, as complexities of real-world problems increased significantly. We present some examples of modern real-world problems, discuss why they might be difficult to solve, and whether there is any mismatch between these examples and the problems that are investigated in the evolutionary computation area.