 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFINER-SQL: Boosting Small Language Models for Text-to-SQL
May 05, 2026Large language models have driven major advances in Text-to-SQL generation. However, they suffer from high computational cost, long latency, and data privacy concerns, which make them impractical for many real-world applications. A natural alternative is to use small language models (SLMs), which enable efficient and private on-premise deployment. Yet, SLMs often struggle with weak reasoning and poor instruction following. Conventional reinforcement learning methods based on sparse binary rewards (0/1) provide little learning signal when the generated SQLs are incorrect, leading to unstable or collapsed training. To overcome these issues, we propose FINER-SQL, a scalable and reusable reinforcement learning framework that enhances SLMs through fine-grained execution feedback. Built on group relative policy optimization, FINER-SQL replaces sparse supervision with dense and interpretable rewards that offer continuous feedback even for incorrect SQLs. It introduces two key reward functions: a memory reward, which aligns reasoning with verified traces for semantic stability, and an atomic reward, which measures operation-level overlap to grant partial credit for structurally correct but incomplete SQLs. This approach transforms discrete correctness into continuous learning, enabling stable, critic-free optimization. Experiments on the BIRD and Spider benchmarks show that FINER-SQL achieves up to 67.73\% and 85\% execution accuracy with a 3B model -- matching much larger LLMs while reducing inference latency to 5.57~s/sample. These results highlight a cost-efficient and privacy-preserving path toward high-performance Text-to-SQL generation. Our code is available at https://github.com/thanhdath/finer-sql.
A Multi-agent Text2SQL Framework using Small Language Models and Execution Feedback
Dec 21, 2025Text2SQL, the task of generating SQL queries from natural language text, is a critical challenge in data engineering. Recently, Large Language Models (LLMs) have demonstrated superior performance for this task due to their advanced comprehension and generation capabilities. However, privacy and cost considerations prevent companies from using Text2SQL solutions based on external LLMs offered as a service. Rather, small LLMs (SLMs) that are openly available and can hosted in-house are adopted. These SLMs, in turn, lack the generalization capabilities of larger LLMs, which impairs their effectiveness for complex tasks such as Text2SQL. To address these limitations, we propose MATS, a novel Text2SQL framework designed specifically for SLMs. MATS uses a multi-agent mechanism that assigns specialized roles to auxiliary agents, reducing individual workloads and fostering interaction. A training scheme based on reinforcement learning aligns these agents using feedback obtained during execution, thereby maintaining competitive performance despite a limited LLM size. Evaluation results using on benchmark datasets show that MATS, deployed on a single- GPU server, yields accuracy that are on-par with large-scale LLMs when using significantly fewer parameters. Our source code and data are available at https://github.com/thanhdath/mats-sql.
Control-flow Reconstruction Attacks on Business Process Models
Sep 17, 2024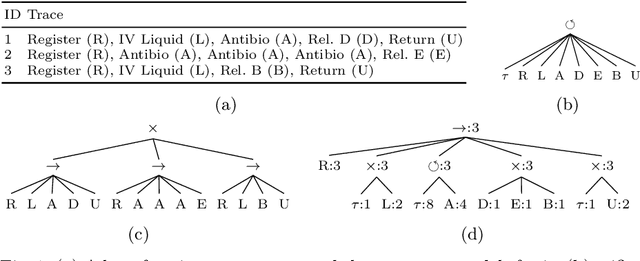
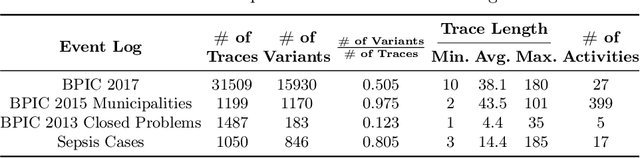
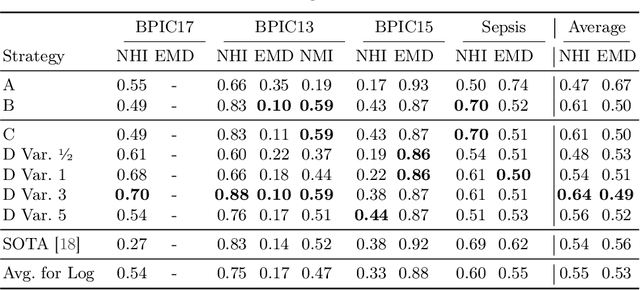
Process models may be automatically generated from event logs that contain as-is data of a business process. While such models generalize over the control-flow of specific, recorded process executions, they are often also annotated with behavioural statistics, such as execution frequencies.Based thereon, once a model is published, certain insights about the original process executions may be reconstructed, so that an external party may extract confidential information about the business process. This work is the first to empirically investigate such reconstruction attempts based on process models. To this end, we propose different play-out strategies that reconstruct the control-flow from process trees, potentially exploiting frequency annotations. To assess the potential success of such reconstruction attacks on process models, and hence the risks imposed by publishing them, we compare the reconstructed process executions with those of the original log for several real-world datasets.
Fast-FedUL: A Training-Free Federated Unlearning with Provable Skew Resilience
May 28, 2024Federated learning (FL) has recently emerged as a compelling machine learning paradigm, prioritizing the protection of privacy for training data. The increasing demand to address issues such as ``the right to be forgotten'' and combat data poisoning attacks highlights the importance of techniques, known as \textit{unlearning}, which facilitate the removal of specific training data from trained FL models. Despite numerous unlearning methods proposed for centralized learning, they often prove inapplicable to FL due to fundamental differences in the operation of the two learning paradigms. Consequently, unlearning in FL remains in its early stages, presenting several challenges. Many existing unlearning solutions in FL require a costly retraining process, which can be burdensome for clients. Moreover, these methods are primarily validated through experiments, lacking theoretical assurances. In this study, we introduce Fast-FedUL, a tailored unlearning method for FL, which eliminates the need for retraining entirely. Through meticulous analysis of the target client's influence on the global model in each round, we develop an algorithm to systematically remove the impact of the target client from the trained model. In addition to presenting empirical findings, we offer a theoretical analysis delineating the upper bound of our unlearned model and the exact retrained model (the one obtained through retraining using untargeted clients). Experimental results with backdoor attack scenarios indicate that Fast-FedUL effectively removes almost all traces of the target client, while retaining the knowledge of untargeted clients (obtaining a high accuracy of up to 98\% on the main task). Significantly, Fast-FedUL attains the lowest time complexity, providing a speed that is 1000 times faster than retraining. Our source code is publicly available at \url{https://github.com/thanhtrunghuynh93/fastFedUL}.
Manipulating Recommender Systems: A Survey of Poisoning Attacks and Countermeasures
Apr 23, 2024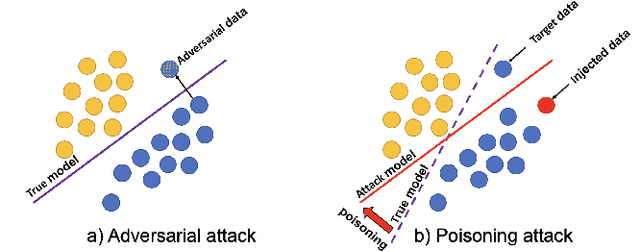
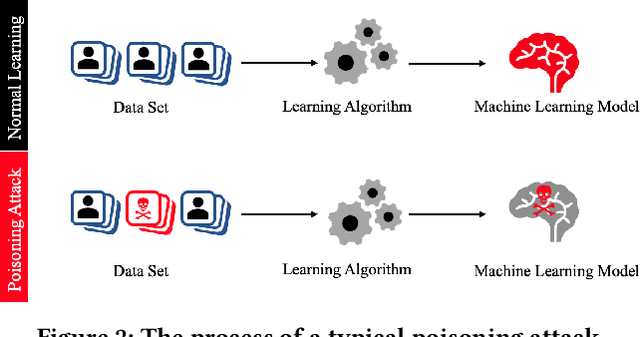
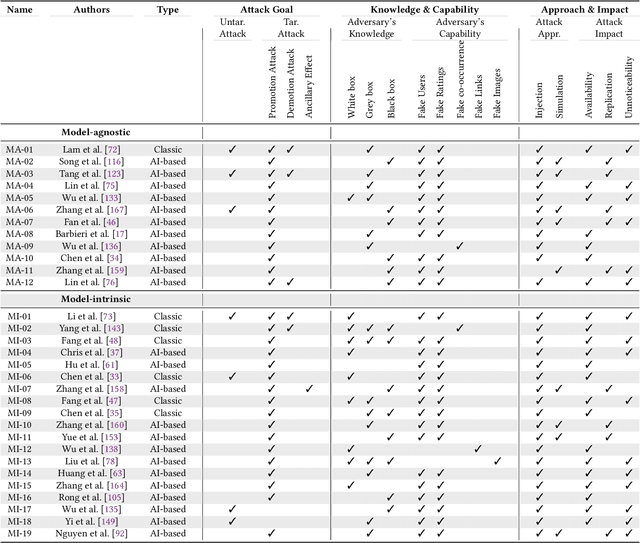
Recommender systems have become an integral part of online services to help users locate specific information in a sea of data. However, existing studies show that some recommender systems are vulnerable to poisoning attacks, particularly those that involve learning schemes. A poisoning attack is where an adversary injects carefully crafted data into the process of training a model, with the goal of manipulating the system's final recommendations. Based on recent advancements in artificial intelligence, such attacks have gained importance recently. While numerous countermeasures to poisoning attacks have been developed, they have not yet been systematically linked to the properties of the attacks. Consequently, assessing the respective risks and potential success of mitigation strategies is difficult, if not impossible. This survey aims to fill this gap by primarily focusing on poisoning attacks and their countermeasures. This is in contrast to prior surveys that mainly focus on attacks and their detection methods. Through an exhaustive literature review, we provide a novel taxonomy for poisoning attacks, formalise its dimensions, and accordingly organise 30+ attacks described in the literature. Further, we review 40+ countermeasures to detect and/or prevent poisoning attacks, evaluating their effectiveness against specific types of attacks. This comprehensive survey should serve as a point of reference for protecting recommender systems against poisoning attacks. The article concludes with a discussion on open issues in the field and impactful directions for future research. A rich repository of resources associated with poisoning attacks is available at https://github.com/tamlhp/awesome-recsys-poisoning.
Mining a Minimal Set of Behavioral Patterns using Incremental Evaluation
Feb 05, 2024Process mining provides methods to analyse event logs generated by information systems during the execution of processes. It thereby supports the design, validation, and execution of processes in domains ranging from healthcare, through manufacturing, to e-commerce. To explore the regularities of flexible processes that show a large behavioral variability, it was suggested to mine recurrent behavioral patterns that jointly describe the underlying process. Existing approaches to behavioral pattern mining, however, suffer from two limitations. First, they show limited scalability as incremental computation is incorporated only in the generation of pattern candidates, but not in the evaluation of their quality. Second, process analysis based on mined patterns shows limited effectiveness due to an overwhelmingly large number of patterns obtained in practical application scenarios, many of which are redundant. In this paper, we address these limitations to facilitate the analysis of complex, flexible processes based on behavioral patterns. Specifically, we improve COBPAM, our initial behavioral pattern mining algorithm, by an incremental procedure to evaluate the quality of pattern candidates, optimizing thereby its efficiency. Targeting a more effective use of the resulting patterns, we further propose pruning strategies for redundant patterns and show how relations between the remaining patterns are extracted and visualized to provide process insights. Our experiments with diverse real-world datasets indicate a considerable reduction of the runtime needed for pattern mining, while a qualitative assessment highlights how relations between patterns guide the analysis of the underlying process.
Knowledge-Driven Modulation of Neural Networks with Attention Mechanism for Next Activity Prediction
Dec 14, 2023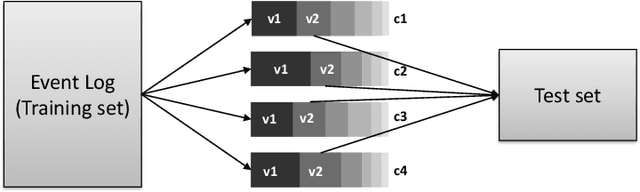
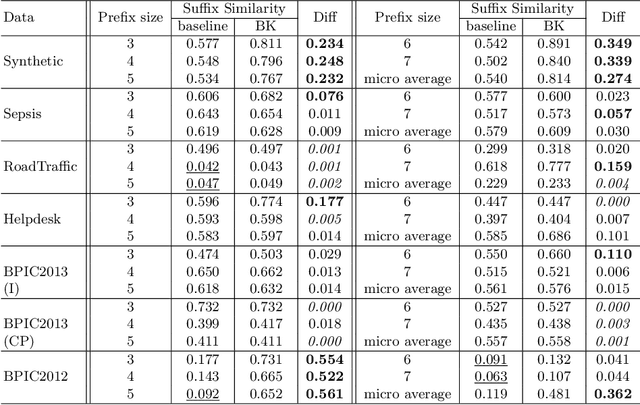
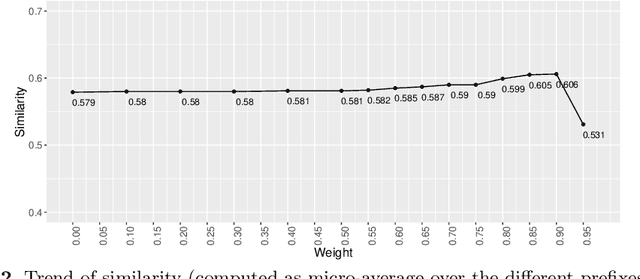
Predictive Process Monitoring (PPM) aims at leveraging historic process execution data to predict how ongoing executions will continue up to their completion. In recent years, PPM techniques for the prediction of the next activities have matured significantly, mainly thanks to the use of Neural Networks (NNs) as a predictor. While their performance is difficult to beat in the general case, there are specific situations where background process knowledge can be helpful. Such knowledge can be leveraged for improving the quality of predictions for exceptional process executions or when the process changes due to a concept drift. In this paper, we present a Symbolic[Neuro] system that leverages background knowledge expressed in terms of a procedural process model to offset the under-sampling in the training data. More specifically, we make predictions using NNs with attention mechanism, an emerging technology in the NN field. The system has been tested on several real-life logs showing an improvement in the performance of the prediction task.
Large Process Models: Business Process Management in the Age of Generative AI
Sep 11, 2023
The continued success of Large Language Models (LLMs) and other generative artificial intelligence approaches highlights the advantages that large information corpora can have over rigidly defined symbolic models, but also serves as a proof-point of the challenges that purely statistics-based approaches have in terms of safety and trustworthiness. As a framework for contextualizing the potential, as well as the limitations of LLMs and other foundation model-based technologies, we propose the concept of a Large Process Model (LPM) that combines the correlation power of LLMs with the analytical precision and reliability of knowledge-based systems and automated reasoning approaches. LPMs are envisioned to directly utilize the wealth of process management experience that experts have accumulated, as well as process performance data of organizations with diverse characteristics, e.g., regarding size, region, or industry. In this vision, the proposed LPM would allow organizations to receive context-specific (tailored) process and other business models, analytical deep-dives, and improvement recommendations. As such, they would allow to substantially decrease the time and effort required for business transformation, while also allowing for deeper, more impactful, and more actionable insights than previously possible. We argue that implementing an LPM is feasible, but also highlight limitations and research challenges that need to be solved to implement particular aspects of the LPM vision.
Efficient Integration of Multi-Order Dynamics and Internal Dynamics in Stock Movement Prediction
Nov 11, 2022

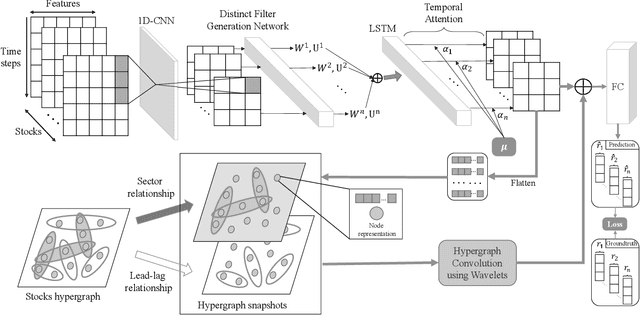
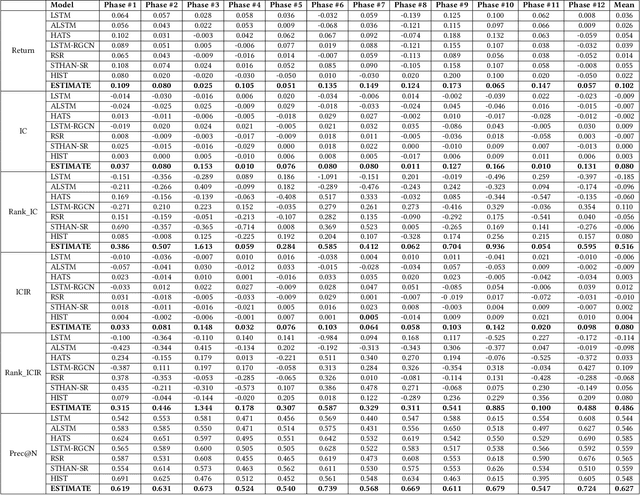
Advances in deep neural network (DNN) architectures have enabled new prediction techniques for stock market data. Unlike other multivariate time-series data, stock markets show two unique characteristics: (i) \emph{multi-order dynamics}, as stock prices are affected by strong non-pairwise correlations (e.g., within the same industry); and (ii) \emph{internal dynamics}, as each individual stock shows some particular behaviour. Recent DNN-based methods capture multi-order dynamics using hypergraphs, but rely on the Fourier basis in the convolution, which is both inefficient and ineffective. In addition, they largely ignore internal dynamics by adopting the same model for each stock, which implies a severe information loss. In this paper, we propose a framework for stock movement prediction to overcome the above issues. Specifically, the framework includes temporal generative filters that implement a memory-based mechanism onto an LSTM network in an attempt to learn individual patterns per stock. Moreover, we employ hypergraph attentions to capture the non-pairwise correlations. Here, using the wavelet basis instead of the Fourier basis, enables us to simplify the message passing and focus on the localized convolution. Experiments with US market data over six years show that our framework outperforms state-of-the-art methods in terms of profit and stability. Our source code and data are available at \url{https://github.com/thanhtrunghuynh93/estimate}.
Model-Agnostic and Diverse Explanations for Streaming Rumour Graphs
Jul 17, 2022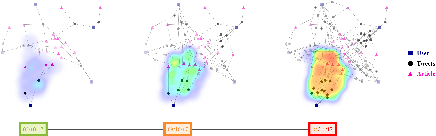

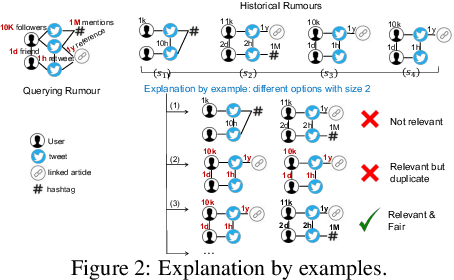
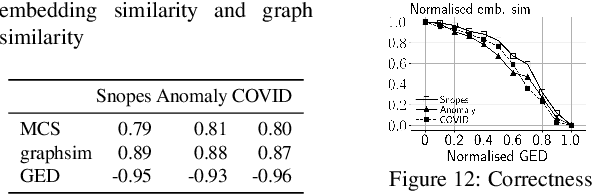
The propagation of rumours on social media poses an important threat to societies, so that various techniques for rumour detection have been proposed recently. Yet, existing work focuses on \emph{what} entities constitute a rumour, but provides little support to understand \emph{why} the entities have been classified as such. This prevents an effective evaluation of the detected rumours as well as the design of countermeasures. In this work, we argue that explanations for detected rumours may be given in terms of examples of related rumours detected in the past. A diverse set of similar rumours helps users to generalize, i.e., to understand the properties that govern the detection of rumours. Since the spread of rumours in social media is commonly modelled using feature-annotated graphs, we propose a query-by-example approach that, given a rumour graph, extracts the $k$ most similar and diverse subgraphs from past rumours. The challenge is that all of the computations require fast assessment of similarities between graphs. To achieve an efficient and adaptive realization of the approach in a streaming setting, we present a novel graph representation learning technique and report on implementation considerations. Our evaluation experiments show that our approach outperforms baseline techniques in delivering meaningful explanations for various rumour propagation behaviours.