 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Undesired Process Behavior by Means of Retrieval Augmented Generation
May 28, 2025Conformance checking techniques detect undesired process behavior by comparing process executions that are recorded in event logs to desired behavior that is captured in a dedicated process model. If such models are not available, conformance checking techniques are not applicable, but organizations might still be interested in detecting undesired behavior in their processes. To enable this, existing approaches use Large Language Models (LLMs), assuming that they can learn to distinguish desired from undesired behavior through fine-tuning. However, fine-tuning is highly resource-intensive and the fine-tuned LLMs often do not generalize well. To address these limitations, we propose an approach that requires neither a dedicated process model nor resource-intensive fine-tuning to detect undesired process behavior. Instead, we use Retrieval Augmented Generation (RAG) to provide an LLM with direct access to a knowledge base that contains both desired and undesired process behavior from other processes, assuming that the LLM can transfer this knowledge to the process at hand. Our evaluation shows that our approach outperforms fine-tuned LLMs in detecting undesired behavior, demonstrating that RAG is a viable alternative to resource-intensive fine-tuning, particularly when enriched with relevant context from the event log, such as frequent traces and activities.
On the Potential of Large Language Models to Solve Semantics-Aware Process Mining Tasks
Apr 29, 2025


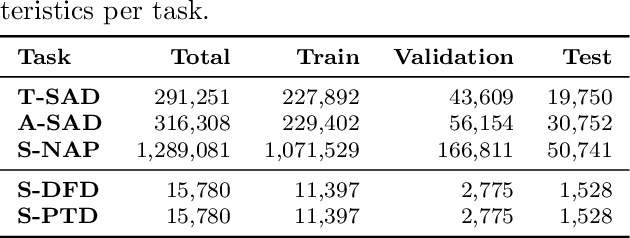
Large language models (LLMs) have shown to be valuable tools for tackling process mining tasks. Existing studies report on their capability to support various data-driven process analyses and even, to some extent, that they are able to reason about how processes work. This reasoning ability suggests that there is potential for LLMs to tackle semantics-aware process mining tasks, which are tasks that rely on an understanding of the meaning of activities and their relationships. Examples of these include process discovery, where the meaning of activities can indicate their dependency, whereas in anomaly detection the meaning can be used to recognize process behavior that is abnormal. In this paper, we systematically explore the capabilities of LLMs for such tasks. Unlike prior work, which largely evaluates LLMs in their default state, we investigate their utility through both in-context learning and supervised fine-tuning. Concretely, we define five process mining tasks requiring semantic understanding and provide extensive benchmarking datasets for evaluation. Our experiments reveal that while LLMs struggle with challenging process mining tasks when used out of the box or with minimal in-context examples, they achieve strong performance when fine-tuned for these tasks across a broad range of process types and industries.
Evaluating the Ability of LLMs to Solve Semantics-Aware Process Mining Tasks
Jul 02, 2024



The process mining community has recently recognized the potential of large language models (LLMs) for tackling various process mining tasks. Initial studies report the capability of LLMs to support process analysis and even, to some extent, that they are able to reason about how processes work. This latter property suggests that LLMs could also be used to tackle process mining tasks that benefit from an understanding of process behavior. Examples of such tasks include (semantic) anomaly detection and next activity prediction, which both involve considerations of the meaning of activities and their inter-relations. In this paper, we investigate the capabilities of LLMs to tackle such semantics-aware process mining tasks. Furthermore, whereas most works on the intersection of LLMs and process mining only focus on testing these models out of the box, we provide a more principled investigation of the utility of LLMs for process mining, including their ability to obtain process mining knowledge post-hoc by means of in-context learning and supervised fine-tuning. Concretely, we define three process mining tasks that benefit from an understanding of process semantics and provide extensive benchmarking datasets for each of them. Our evaluation experiments reveal that (1) LLMs fail to solve challenging process mining tasks out of the box and when provided only a handful of in-context examples, (2) but they yield strong performance when fine-tuned for these tasks, consistently surpassing smaller, encoder-based language models.
Large Process Models: Business Process Management in the Age of Generative AI
Sep 11, 2023
The continued success of Large Language Models (LLMs) and other generative artificial intelligence approaches highlights the advantages that large information corpora can have over rigidly defined symbolic models, but also serves as a proof-point of the challenges that purely statistics-based approaches have in terms of safety and trustworthiness. As a framework for contextualizing the potential, as well as the limitations of LLMs and other foundation model-based technologies, we propose the concept of a Large Process Model (LPM) that combines the correlation power of LLMs with the analytical precision and reliability of knowledge-based systems and automated reasoning approaches. LPMs are envisioned to directly utilize the wealth of process management experience that experts have accumulated, as well as process performance data of organizations with diverse characteristics, e.g., regarding size, region, or industry. In this vision, the proposed LPM would allow organizations to receive context-specific (tailored) process and other business models, analytical deep-dives, and improvement recommendations. As such, they would allow to substantially decrease the time and effort required for business transformation, while also allowing for deeper, more impactful, and more actionable insights than previously possible. We argue that implementing an LPM is feasible, but also highlight limitations and research challenges that need to be solved to implement particular aspects of the LPM vision.
Extracting Semantic Process Information from the Natural Language in Event Logs
Mar 06, 2021

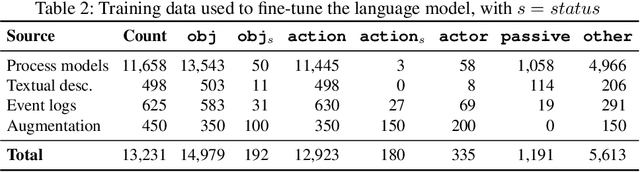

Process mining focuses on the analysis of recorded event data in order to gain insights about the true execution of business processes. While foundational process mining techniques treat such data as sequences of abstract events, more advanced techniques depend on the availability of specific kinds of information, such as resources in organizational mining and business objects in artifact-centric analysis. However, this information is generally not readily available, but rather associated with events in an ad hoc manner, often even as part of unstructured textual attributes. Given the size and complexity of event logs, this calls for automated support to extract such process information and, thereby, enable advanced process mining techniques. In this paper, we present an approach that achieves this through so-called semantic role labeling of event data. We combine the analysis of textual attribute values, based on a state-of-the-art language model, with a novel attribute classification technique. In this manner, our approach extracts information about up to eight semantic roles per event. We demonstrate the approach's efficacy through a quantitative evaluation using a broad range of event logs and demonstrate the usefulness of the extracted information in a case study.