 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Divide-and-Conquer Approach for Modeling Arrival Times in Business Process Simulation
May 28, 2025
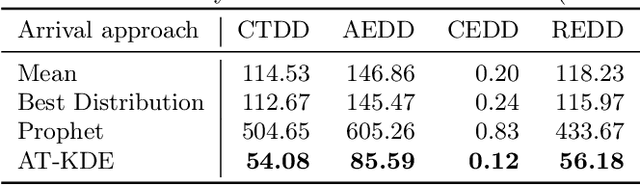


Business Process Simulation (BPS) is a critical tool for analyzing and improving organizational processes by estimating the impact of process changes. A key component of BPS is the case-arrival model, which determines the pattern of new case entries into a process. Although accurate case-arrival modeling is essential for reliable simulations, as it influences waiting and overall cycle times, existing approaches often rely on oversimplified static distributions of inter-arrival times. These approaches fail to capture the dynamic and temporal complexities inherent in organizational environments, leading to less accurate and reliable outcomes. To address this limitation, we propose Auto Time Kernel Density Estimation (AT-KDE), a divide-and-conquer approach that models arrival times of processes by incorporating global dynamics, day-of-week variations, and intraday distributional changes, ensuring both precision and scalability. Experiments conducted across 20 diverse processes demonstrate that AT-KDE is far more accurate and robust than existing approaches while maintaining sensible execution time efficiency.
Rethinking BPS: A Utility-Based Evaluation Framework
May 28, 2025Business process simulation (BPS) is a key tool for analyzing and optimizing organizational workflows, supporting decision-making by estimating the impact of process changes. The reliability of such estimates depends on the ability of a BPS model to accurately mimic the process under analysis, making rigorous accuracy evaluation essential. However, the state-of-the-art approach to evaluating BPS models has two key limitations. First, it treats simulation as a forecasting problem, testing whether models can predict unseen future events. This fails to assess how well a model captures the as-is process, particularly when process behavior changes from train to test period. Thus, it becomes difficult to determine whether poor results stem from an inaccurate model or the inherent complexity of the data, such as unpredictable drift. Second, the evaluation approach strongly relies on Earth Mover's Distance-based metrics, which can obscure temporal patterns and thus yield misleading conclusions about simulation quality. To address these issues, we propose a novel framework that evaluates simulation quality based on its ability to generate representative process behavior. Instead of comparing simulated logs to future real-world executions, we evaluate whether predictive process monitoring models trained on simulated data perform comparably to those trained on real data for downstream analysis tasks. Empirical results show that our framework not only helps identify sources of discrepancies but also distinguishes between model accuracy and data complexity, offering a more meaningful way to assess BPS quality.
On the Potential of Large Language Models to Solve Semantics-Aware Process Mining Tasks
Apr 29, 2025


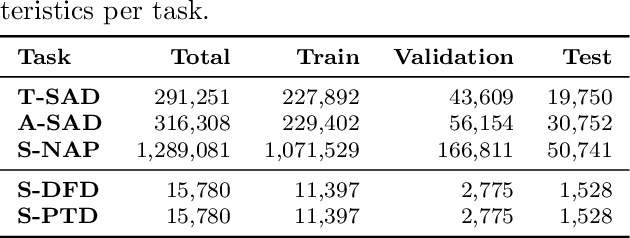
Large language models (LLMs) have shown to be valuable tools for tackling process mining tasks. Existing studies report on their capability to support various data-driven process analyses and even, to some extent, that they are able to reason about how processes work. This reasoning ability suggests that there is potential for LLMs to tackle semantics-aware process mining tasks, which are tasks that rely on an understanding of the meaning of activities and their relationships. Examples of these include process discovery, where the meaning of activities can indicate their dependency, whereas in anomaly detection the meaning can be used to recognize process behavior that is abnormal. In this paper, we systematically explore the capabilities of LLMs for such tasks. Unlike prior work, which largely evaluates LLMs in their default state, we investigate their utility through both in-context learning and supervised fine-tuning. Concretely, we define five process mining tasks requiring semantic understanding and provide extensive benchmarking datasets for evaluation. Our experiments reveal that while LLMs struggle with challenging process mining tasks when used out of the box or with minimal in-context examples, they achieve strong performance when fine-tuned for these tasks across a broad range of process types and industries.
Assisted Data Annotation for Business Process Information Extraction from Textual Documents
Oct 02, 2024



Machine-learning based generation of process models from natural language text process descriptions provides a solution for the time-intensive and expensive process discovery phase. Many organizations have to carry out this phase, before they can utilize business process management and its benefits. Yet, research towards this is severely restrained by an apparent lack of large and high-quality datasets. This lack of data can be attributed to, among other things, an absence of proper tool assistance for dataset creation, resulting in high workloads and inferior data quality. We explore two assistance features to support dataset creation, a recommendation system for identifying process information in the text and visualization of the current state of already identified process information as a graphical business process model. A controlled user study with 31 participants shows that assisting dataset creators with recommendations lowers all aspects of workload, up to $-51.0\%$, and significantly improves annotation quality, up to $+38.9\%$. We make all data and code available to encourage further research on additional novel assistance strategies.
AgentSimulator: An Agent-based Approach for Data-driven Business Process Simulation
Aug 16, 2024



Business process simulation (BPS) is a versatile technique for estimating process performance across various scenarios. Traditionally, BPS approaches employ a control-flow-first perspective by enriching a process model with simulation parameters. Although such approaches can mimic the behavior of centrally orchestrated processes, such as those supported by workflow systems, current control-flow-first approaches cannot faithfully capture the dynamics of real-world processes that involve distinct resource behavior and decentralized decision-making. Recognizing this issue, this paper introduces AgentSimulator, a resource-first BPS approach that discovers a multi-agent system from an event log, modeling distinct resource behaviors and interaction patterns to simulate the underlying process. Our experiments show that AgentSimulator achieves state-of-the-art simulation accuracy with significantly lower computation times than existing approaches while providing high interpretability and adaptability to different types of process-execution scenarios.
A Universal Prompting Strategy for Extracting Process Model Information from Natural Language Text using Large Language Models
Jul 26, 2024Over the past decade, extensive research efforts have been dedicated to the extraction of information from textual process descriptions. Despite the remarkable progress witnessed in natural language processing (NLP), information extraction within the Business Process Management domain remains predominantly reliant on rule-based systems and machine learning methodologies. Data scarcity has so far prevented the successful application of deep learning techniques. However, the rapid progress in generative large language models (LLMs) makes it possible to solve many NLP tasks with very high quality without the need for extensive data. Therefore, we systematically investigate the potential of LLMs for extracting information from textual process descriptions, targeting the detection of process elements such as activities and actors, and relations between them. Using a heuristic algorithm, we demonstrate the suitability of the extracted information for process model generation. Based on a novel prompting strategy, we show that LLMs are able to outperform state-of-the-art machine learning approaches with absolute performance improvements of up to 8\% $F_1$ score across three different datasets. We evaluate our prompting strategy on eight different LLMs, showing it is universally applicable, while also analyzing the impact of certain prompt parts on extraction quality. The number of example texts, the specificity of definitions, and the rigour of format instructions are identified as key for improving the accuracy of extracted information. Our code, prompts, and data are publicly available.
Evaluating the Ability of LLMs to Solve Semantics-Aware Process Mining Tasks
Jul 02, 2024



The process mining community has recently recognized the potential of large language models (LLMs) for tackling various process mining tasks. Initial studies report the capability of LLMs to support process analysis and even, to some extent, that they are able to reason about how processes work. This latter property suggests that LLMs could also be used to tackle process mining tasks that benefit from an understanding of process behavior. Examples of such tasks include (semantic) anomaly detection and next activity prediction, which both involve considerations of the meaning of activities and their inter-relations. In this paper, we investigate the capabilities of LLMs to tackle such semantics-aware process mining tasks. Furthermore, whereas most works on the intersection of LLMs and process mining only focus on testing these models out of the box, we provide a more principled investigation of the utility of LLMs for process mining, including their ability to obtain process mining knowledge post-hoc by means of in-context learning and supervised fine-tuning. Concretely, we define three process mining tasks that benefit from an understanding of process semantics and provide extensive benchmarking datasets for each of them. Our evaluation experiments reveal that (1) LLMs fail to solve challenging process mining tasks out of the box and when provided only a handful of in-context examples, (2) but they yield strong performance when fine-tuned for these tasks, consistently surpassing smaller, encoder-based language models.
PGTNet: A Process Graph Transformer Network for Remaining Time Prediction of Business Process Instances
Apr 09, 2024We present PGTNet, an approach that transforms event logs into graph datasets and leverages graph-oriented data for training Process Graph Transformer Networks to predict the remaining time of business process instances. PGTNet consistently outperforms state-of-the-art deep learning approaches across a diverse range of 20 publicly available real-world event logs. Notably, our approach is most promising for highly complex processes, where existing deep learning approaches encounter difficulties stemming from their limited ability to learn control-flow relationships among process activities and capture long-range dependencies. PGTNet addresses these challenges, while also being able to consider multiple process perspectives during the learning process.
Large Process Models: Business Process Management in the Age of Generative AI
Sep 11, 2023
The continued success of Large Language Models (LLMs) and other generative artificial intelligence approaches highlights the advantages that large information corpora can have over rigidly defined symbolic models, but also serves as a proof-point of the challenges that purely statistics-based approaches have in terms of safety and trustworthiness. As a framework for contextualizing the potential, as well as the limitations of LLMs and other foundation model-based technologies, we propose the concept of a Large Process Model (LPM) that combines the correlation power of LLMs with the analytical precision and reliability of knowledge-based systems and automated reasoning approaches. LPMs are envisioned to directly utilize the wealth of process management experience that experts have accumulated, as well as process performance data of organizations with diverse characteristics, e.g., regarding size, region, or industry. In this vision, the proposed LPM would allow organizations to receive context-specific (tailored) process and other business models, analytical deep-dives, and improvement recommendations. As such, they would allow to substantially decrease the time and effort required for business transformation, while also allowing for deeper, more impactful, and more actionable insights than previously possible. We argue that implementing an LPM is feasible, but also highlight limitations and research challenges that need to be solved to implement particular aspects of the LPM vision.
PET: A new Dataset for Process Extraction from Natural Language Text
Mar 09, 2022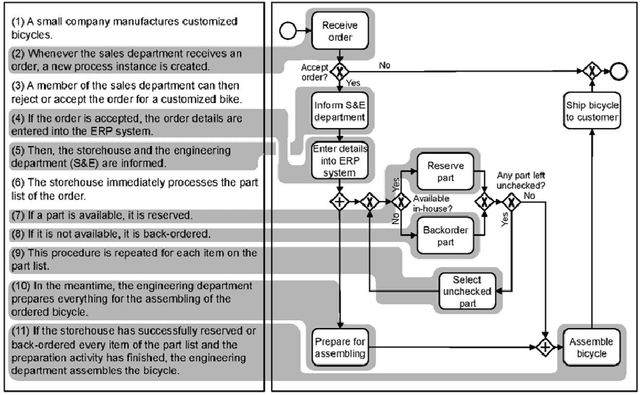
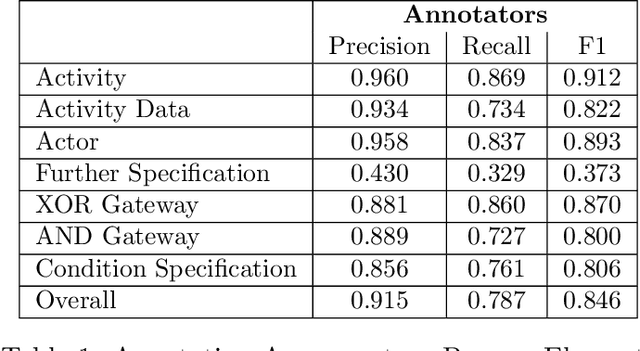

Although there is a long tradition of work in NLP on extracting entities and relations from text, to date there exists little work on the acquisition of business processes from unstructured data such as textual corpora of process descriptions. With this work we aim at filling this gap and establishing the first steps towards bridging data-driven information extraction methodologies from Natural Language Processing and the model-based formalization that is aimed from Business Process Management. For this, we develop the first corpus of business process descriptions annotated with activities, gateways, actors and flow information. We present our new resource, including a detailed overview of the annotation schema and guidelines, as well as a variety of baselines to benchmark the difficulty and challenges of business process extraction from text.