 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePluRel: Synthetic Data unlocks Scaling Laws for Relational Foundation Models
Feb 03, 2026Relational Foundation Models (RFMs) facilitate data-driven decision-making by learning from complex multi-table databases. However, the diverse relational databases needed to train such models are rarely public due to privacy constraints. While there are methods to generate synthetic tabular data of arbitrary size, incorporating schema structure and primary--foreign key connectivity for multi-table generation remains challenging. Here we introduce PluRel, a framework to synthesize multi-tabular relational databases from scratch. In a step-by-step fashion, PluRel models (1) schemas with directed graphs, (2) inter-table primary-foreign key connectivity with bipartite graphs, and, (3) feature distributions in tables via conditional causal mechanisms. The design space across these stages supports the synthesis of a wide range of diverse databases, while being computationally lightweight. Using PluRel, we observe for the first time that (1) RFM pretraining loss exhibits power-law scaling with the number of synthetic databases and total pretraining tokens, (2) scaling the number of synthetic databases improves generalization to real databases, and (3) synthetic pretraining yields strong base models for continued pretraining on real databases. Overall, our framework and results position synthetic data scaling as a promising paradigm for RFMs.
SALT-KG: A Benchmark for Semantics-Aware Learning on Enterprise Tables
Jan 12, 2026Building upon the SALT benchmark for relational prediction (Klein et al., 2024), we introduce SALT-KG, a benchmark for semantics-aware learning on enterprise tables. SALT-KG extends SALT by linking its multi-table transactional data with a structured Operational Business Knowledge represented in a Metadata Knowledge Graph (OBKG) that captures field-level descriptions, relational dependencies, and business object types. This extension enables evaluation of models that jointly reason over tabular evidence and contextual semantics, an increasingly critical capability for foundation models on structured data. Empirical analysis reveals that while metadata-derived features yield modest improvements in classical prediction metrics, these metadata features consistently highlight gaps in the ability of models to leverage semantics in relational context. By reframing tabular prediction as semantics-conditioned reasoning, SALT-KG establishes a benchmark to advance tabular foundation models grounded in declarative knowledge, providing the first empirical step toward semantically linked tables in structured data at enterprise scale.
Foundation Models for Tabular Data within Systemic Contexts Need Grounding
May 26, 2025Current research on tabular foundation models often overlooks the complexities of large-scale, real-world data by treating tables as isolated entities and assuming information completeness, thereby neglecting the vital operational context. To address this, we introduce the concept of Semantically Linked Tables (SLT), recognizing that tables are inherently connected to both declarative and procedural operational knowledge. We propose Foundation Models for Semantically Linked Tables (FMSLT), which integrate these components to ground tabular data within its true operational context. This comprehensive representation unlocks the full potential of machine learning for complex, interconnected tabular data across diverse domains. Realizing FMSLTs requires access to operational knowledge that is often unavailable in public datasets, highlighting the need for close collaboration between domain experts and researchers. Our work exposes the limitations of current tabular foundation models and proposes a new direction centered on FMSLTs, aiming to advance robust, context-aware models for structured data.
SALT: Sales Autocompletion Linked Business Tables Dataset
Jan 06, 2025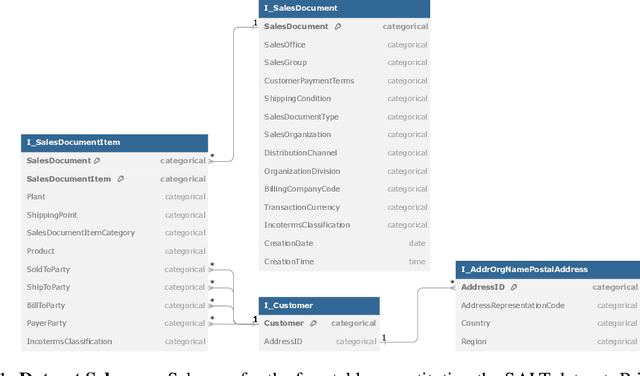

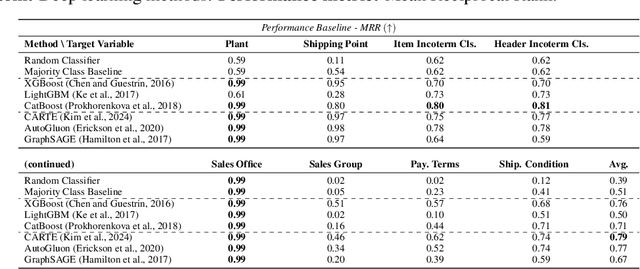
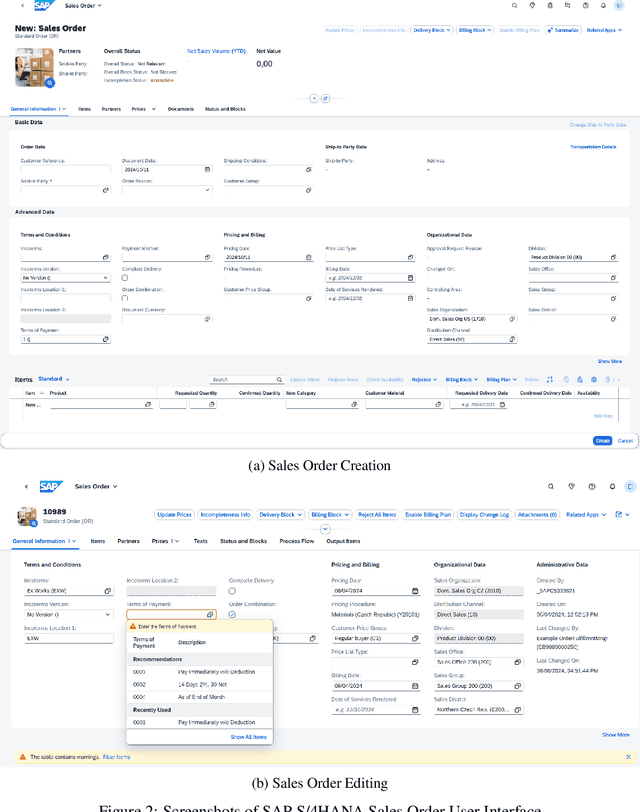
Foundation models, particularly those that incorporate Transformer architectures, have demonstrated exceptional performance in domains such as natural language processing and image processing. Adapting these models to structured data, like tables, however, introduces significant challenges. These difficulties are even more pronounced when addressing multi-table data linked via foreign key, which is prevalent in the enterprise realm and crucial for empowering business use cases. Despite its substantial impact, research focusing on such linked business tables within enterprise settings remains a significantly important yet underexplored domain. To address this, we introduce a curated dataset sourced from an Enterprise Resource Planning (ERP) system, featuring extensive linked tables. This dataset is specifically designed to support research endeavors in table representation learning. By providing access to authentic enterprise data, our goal is to potentially enhance the effectiveness and applicability of models for real-world business contexts.
PORTAL: Scalable Tabular Foundation Models via Content-Specific Tokenization
Oct 17, 2024



Self-supervised learning on tabular data seeks to apply advances from natural language and image domains to the diverse domain of tables. However, current techniques often struggle with integrating multi-domain data and require data cleaning or specific structural requirements, limiting the scalability of pre-training datasets. We introduce PORTAL (Pretraining One-Row-at-a-Time for All tabLes), a framework that handles various data modalities without the need for cleaning or preprocessing. This simple yet powerful approach can be effectively pre-trained on online-collected datasets and fine-tuned to match state-of-the-art methods on complex classification and regression tasks. This work offers a practical advancement in self-supervised learning for large-scale tabular data.
Large Process Models: Business Process Management in the Age of Generative AI
Sep 11, 2023
The continued success of Large Language Models (LLMs) and other generative artificial intelligence approaches highlights the advantages that large information corpora can have over rigidly defined symbolic models, but also serves as a proof-point of the challenges that purely statistics-based approaches have in terms of safety and trustworthiness. As a framework for contextualizing the potential, as well as the limitations of LLMs and other foundation model-based technologies, we propose the concept of a Large Process Model (LPM) that combines the correlation power of LLMs with the analytical precision and reliability of knowledge-based systems and automated reasoning approaches. LPMs are envisioned to directly utilize the wealth of process management experience that experts have accumulated, as well as process performance data of organizations with diverse characteristics, e.g., regarding size, region, or industry. In this vision, the proposed LPM would allow organizations to receive context-specific (tailored) process and other business models, analytical deep-dives, and improvement recommendations. As such, they would allow to substantially decrease the time and effort required for business transformation, while also allowing for deeper, more impactful, and more actionable insights than previously possible. We argue that implementing an LPM is feasible, but also highlight limitations and research challenges that need to be solved to implement particular aspects of the LPM vision.
Can Persistent Homology provide an efficient alternative for Evaluation of Knowledge Graph Completion Methods?
Jan 31, 2023In this paper we present a novel method, $\textit{Knowledge Persistence}$ ($\mathcal{KP}$), for faster evaluation of Knowledge Graph (KG) completion approaches. Current ranking-based evaluation is quadratic in the size of the KG, leading to long evaluation times and consequently a high carbon footprint. $\mathcal{KP}$ addresses this by representing the topology of the KG completion methods through the lens of topological data analysis, concretely using persistent homology. The characteristics of persistent homology allow $\mathcal{KP}$ to evaluate the quality of the KG completion looking only at a fraction of the data. Experimental results on standard datasets show that the proposed metric is highly correlated with ranking metrics (Hits@N, MR, MRR). Performance evaluation shows that $\mathcal{KP}$ is computationally efficient: In some cases, the evaluation time (validation+test) of a KG completion method has been reduced from 18 hours (using Hits@10) to 27 seconds (using $\mathcal{KP}$), and on average (across methods & data) reduces the evaluation time (validation+test) by $\approx$ $\textbf{99.96}\%$.
HopfE: Knowledge Graph Representation Learning using Inverse Hopf Fibrations
Aug 12, 2021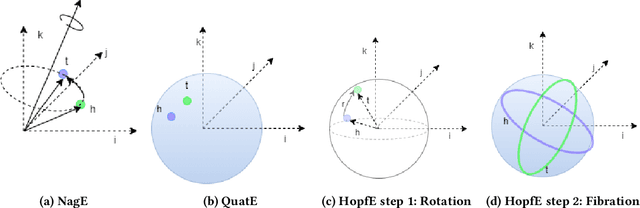

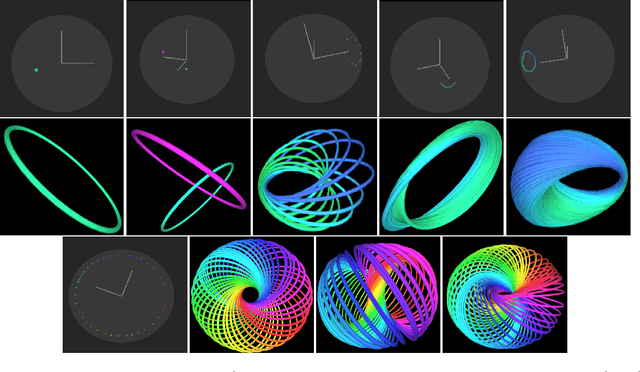
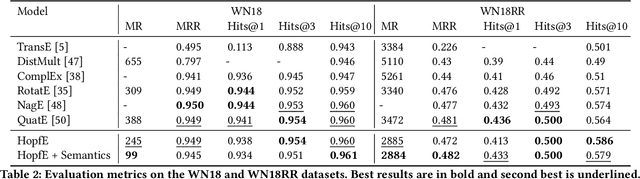
Recently, several Knowledge Graph Embedding (KGE) approaches have been devised to represent entities and relations in dense vector space and employed in downstream tasks such as link prediction. A few KGE techniques address interpretability, i.e., mapping the connectivity patterns of the relations (i.e., symmetric/asymmetric, inverse, and composition) to a geometric interpretation such as rotations. Other approaches model the representations in higher dimensional space such as four-dimensional space (4D) to enhance the ability to infer the connectivity patterns (i.e., expressiveness). However, modeling relation and entity in a 4D space often comes at the cost of interpretability. This paper proposes HopfE, a novel KGE approach aiming to achieve the interpretability of inferred relations in the four-dimensional space. We first model the structural embeddings in 3D Euclidean space and view the relation operator as an SO(3) rotation. Next, we map the entity embedding vector from a 3D space to a 4D hypersphere using the inverse Hopf Fibration, in which we embed the semantic information from the KG ontology. Thus, HopfE considers the structural and semantic properties of the entities without losing expressivity and interpretability. Our empirical results on four well-known benchmarks achieve state-of-the-art performance for the KG completion task.
KGPool: Dynamic Knowledge Graph Context Selection for Relation Extraction
Jun 06, 2021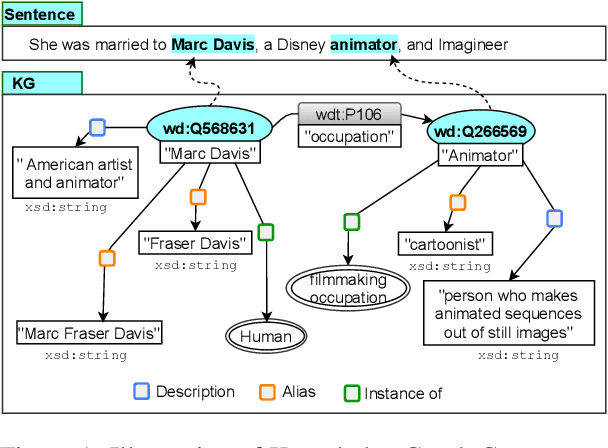
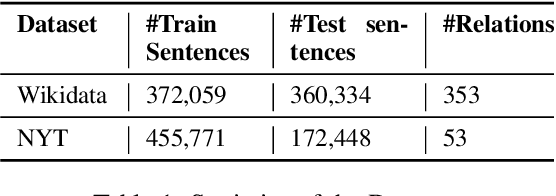
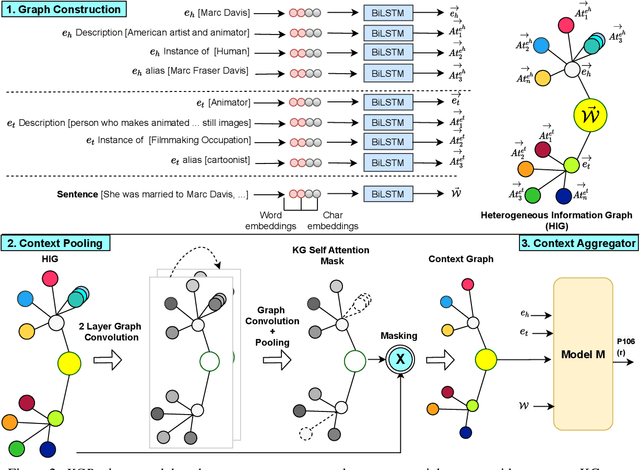
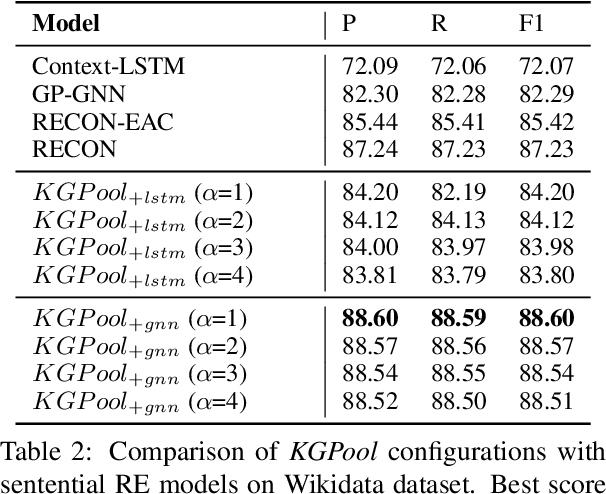
We present a novel method for relation extraction (RE) from a single sentence, mapping the sentence and two given entities to a canonical fact in a knowledge graph (KG). Especially in this presumed sentential RE setting, the context of a single sentence is often sparse. This paper introduces the KGPool method to address this sparsity, dynamically expanding the context with additional facts from the KG. It learns the representation of these facts (entity alias, entity descriptions, etc.) using neural methods, supplementing the sentential context. Unlike existing methods that statically use all expanded facts, KGPool conditions this expansion on the sentence. We study the efficacy of KGPool by evaluating it with different neural models and KGs (Wikidata and NYT Freebase). Our experimental evaluation on standard datasets shows that by feeding the KGPool representation into a Graph Neural Network, the overall method is significantly more accurate than state-of-the-art methods.
CHOLAN: A Modular Approach for Neural Entity Linking on Wikipedia and Wikidata
Feb 08, 2021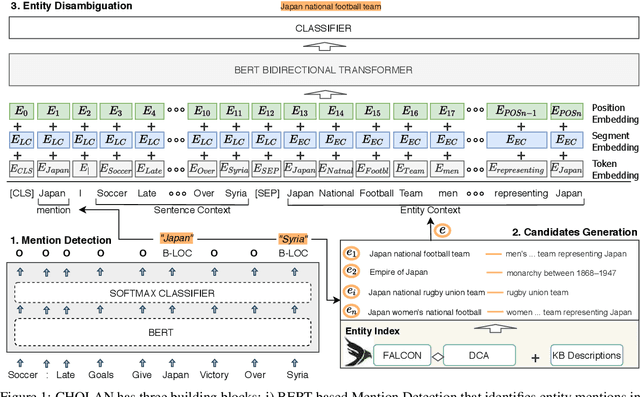
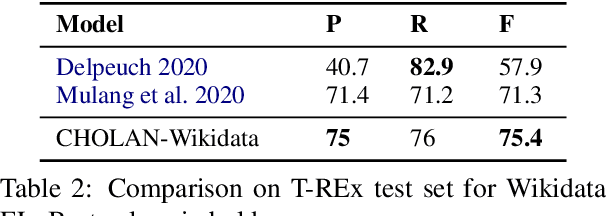
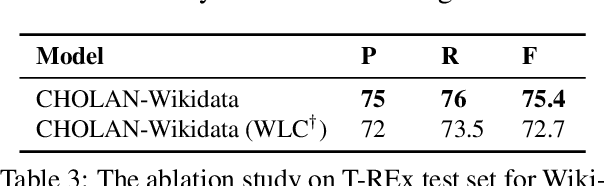
In this paper, we propose CHOLAN, a modular approach to target end-to-end entity linking (EL) over knowledge bases. CHOLAN consists of a pipeline of two transformer-based models integrated sequentially to accomplish the EL task. The first transformer model identifies surface forms (entity mentions) in a given text. For each mention, a second transformer model is employed to classify the target entity among a predefined candidates list. The latter transformer is fed by an enriched context captured from the sentence (i.e. local context), and entity description gained from Wikipedia. Such external contexts have not been used in the state of the art EL approaches. Our empirical study was conducted on two well-known knowledge bases (i.e., Wikidata and Wikipedia). The empirical results suggest that CHOLAN outperforms state-of-the-art approaches on standard datasets such as CoNLL-AIDA, MSNBC, AQUAINT, ACE2004, and T-REx.