 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline learning of smooth functions on $\mathbb{R}$
Apr 04, 2026We study adversarial online learning of real-valued functions on $\mathbb{R}$. In each round the learner is queried at $x_t\in\mathbb{R}$, predicts $\hat y_t$, and then observes the true value $f(x_t)$; performance is measured by cumulative $p$-loss $\sum_{t\ge 1}|\hat y_t-f(x_t)|^p$. For the class \[ \mathcal{G}_q=\Bigl\{f:\mathbb{R}\to\mathbb{R}\ \text{absolutely continuous}:\ \int_{\mathbb{R}}|f'(x)|^q\,dx\le 1\Bigr\}, \] we show that the standard model becomes ill-posed on $\mathbb{R}$: for every $p\ge 1$ and $q>1$, an adversary can force infinite loss. Motivated by this obstruction, we analyze three modified learning scenarios that limit the influence of queries that are far from previously observed inputs. In Scenario 1 the adversary must choose each new query within distance $1$ of some past query. In Scenario 2 the adversary may query anywhere, but the learner is penalized only on rounds whose query lies within distance $1$ of a past query. In Scenario 3 the loss in round $t$ is multiplied by a weight $g(\min_{j<t}|x_t-x_j|)$. We obtain sharp characterizations for Scenarios 1-2 in several regimes. For Scenario 3 we identify a clean threshold phenomenon: if $g$ decays too slowly, then the adversary can force infinite weighted loss. In contrast, for rapidly decaying weights such as $g(z)=e^{-cz}$ we obtain finite and sharp guarantees in the quadratic case $p=q=2$. Finally, we study a natural multivariable slice generalization $\mathcal{G}_{q,d}$ of $\mathcal{G}_q$ on $\mathbb{R}^d$ and show a sharp dichotomy: while the one-dimensional case admits finite opt-values in certain regimes, for every $d\ge 2$ the slice class $\mathcal{G}_{q,d}$ is too permissive, and even under Scenarios 1-3 an adversary can force infinite loss.
Ethical AI in the Healthcare Sector: Investigating Key Drivers of Adoption through the Multi-Dimensional Ethical AI Adoption Model (MEAAM)
May 04, 2025The adoption of Artificial Intelligence (AI) in the healthcare service industry presents numerous ethical challenges, yet current frameworks often fail to offer a comprehensive, empirical understanding of the multidimensional factors influencing ethical AI integration. Addressing this critical research gap, this study introduces the Multi-Dimensional Ethical AI Adoption Model (MEAAM), a novel theoretical framework that categorizes 13 critical ethical variables across four foundational dimensions of Ethical AI Fair AI, Responsible AI, Explainable AI, and Sustainable AI. These dimensions are further analyzed through three core ethical lenses: epistemic concerns (related to knowledge, transparency, and system trustworthiness), normative concerns (focused on justice, autonomy, dignity, and moral obligations), and overarching concerns (highlighting global, systemic, and long-term ethical implications). This study adopts a quantitative, cross-sectional research design using survey data collected from healthcare professionals and analyzed via Partial Least Squares Structural Equation Modeling (PLS-SEM). Employing PLS-SEM, this study empirically investigates the influence of these ethical constructs on two outcomes Operational AI Adoption and Systemic AI Adoption. Results indicate that normative concerns most significantly drive operational adoption decisions, while overarching concerns predominantly shape systemic adoption strategies and governance frameworks. Epistemic concerns play a facilitative role, enhancing the impact of ethical design principles on trust and transparency in AI systems. By validating the MEAAM framework, this research advances a holistic, actionable approach to ethical AI adoption in healthcare and provides critical insights for policymakers, technologists, and healthcare administrators striving to implement ethically grounded AI solutions.
User-Aware Multilingual Abusive Content Detection in Social Media
Oct 26, 2024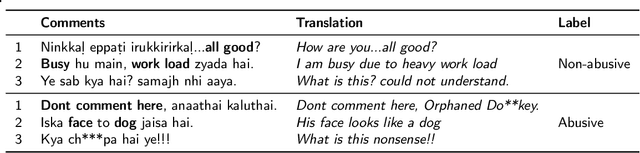
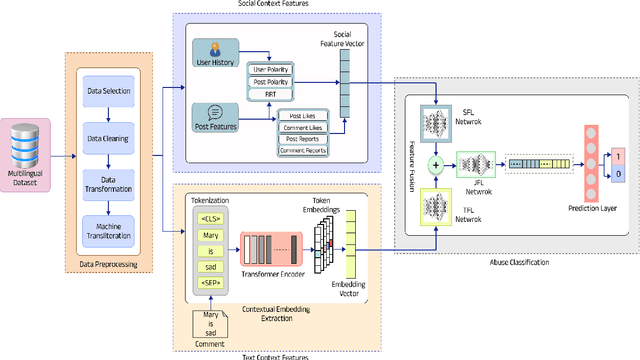
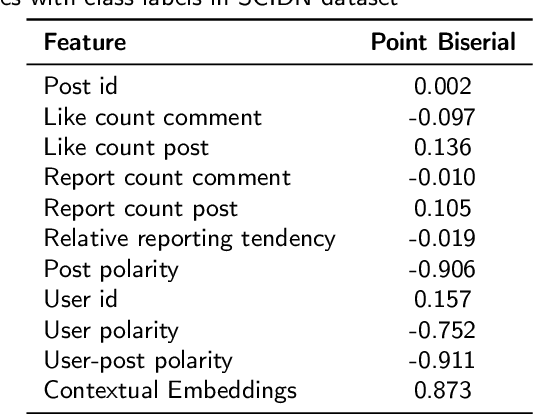
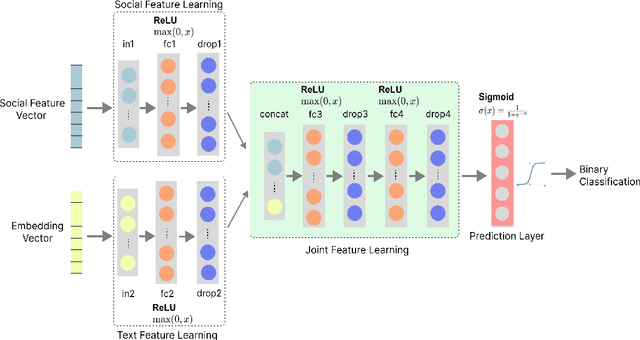
Despite growing efforts to halt distasteful content on social media, multilingualism has added a new dimension to this problem. The scarcity of resources makes the challenge even greater when it comes to low-resource languages. This work focuses on providing a novel method for abusive content detection in multiple low-resource Indic languages. Our observation indicates that a post's tendency to attract abusive comments, as well as features such as user history and social context, significantly aid in the detection of abusive content. The proposed method first learns social and text context features in two separate modules. The integrated representation from these modules is learned and used for the final prediction. To evaluate the performance of our method against different classical and state-of-the-art methods, we have performed extensive experiments on SCIDN and MACI datasets consisting of 1.5M and 665K multilingual comments, respectively. Our proposed method outperforms state-of-the-art baseline methods with an average increase of 4.08% and 9.52% in F1-scores on SCIDN and MACI datasets, respectively.
FinQAPT: Empowering Financial Decisions with End-to-End LLM-driven Question Answering Pipeline
Oct 17, 2024Financial decision-making hinges on the analysis of relevant information embedded in the enormous volume of documents in the financial domain. To address this challenge, we developed FinQAPT, an end-to-end pipeline that streamlines the identification of relevant financial reports based on a query, extracts pertinent context, and leverages Large Language Models (LLMs) to perform downstream tasks. To evaluate the pipeline, we experimented with various techniques to optimize the performance of each module using the FinQA dataset. We introduced a novel clustering-based negative sampling technique to enhance context extraction and a novel prompting method called Dynamic N-shot Prompting to boost the numerical question-answering capabilities of LLMs. At the module level, we achieved state-of-the-art accuracy on FinQA, attaining an accuracy of 80.6\%. However, at the pipeline level, we observed decreased performance due to challenges in extracting relevant context from financial reports. We conducted a detailed error analysis of each module and the end-to-end pipeline, pinpointing specific challenges that must be addressed to develop a robust solution for handling complex financial tasks.
Soft Measures for Extracting Causal Collective Intelligence
Sep 27, 2024



Understanding and modeling collective intelligence is essential for addressing complex social systems. Directed graphs called fuzzy cognitive maps (FCMs) offer a powerful tool for encoding causal mental models, but extracting high-integrity FCMs from text is challenging. This study presents an approach using large language models (LLMs) to automate FCM extraction. We introduce novel graph-based similarity measures and evaluate them by correlating their outputs with human judgments through the Elo rating system. Results show positive correlations with human evaluations, but even the best-performing measure exhibits limitations in capturing FCM nuances. Fine-tuning LLMs improves performance, but existing measures still fall short. This study highlights the need for soft similarity measures tailored to FCM extraction, advancing collective intelligence modeling with NLP.
MASSFormer: Mobility-Aware Spectrum Sensing using Transformer-Driven Tiered Structure
Sep 26, 2024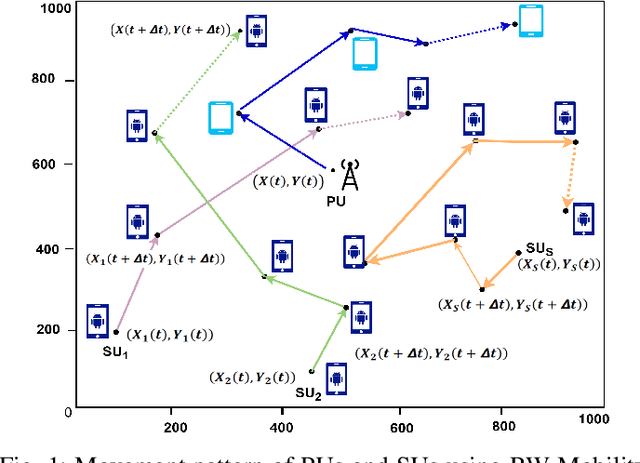


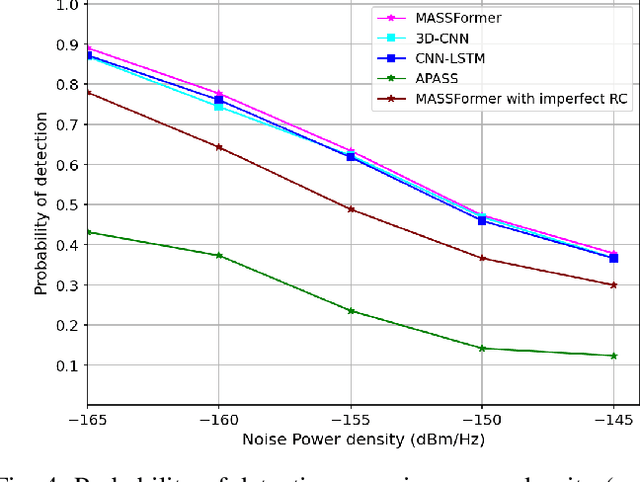
In this paper, we develop a novel mobility-aware transformer-driven tiered structure (MASSFormer) based cooperative spectrum sensing method that effectively models the spatio-temporal dynamics of user movements. Unlike existing methods, our method considers a dynamic scenario involving mobile primary users (PUs) and secondary users (SUs)and addresses the complexities introduced by user mobility. The transformer architecture utilizes an attention mechanism, enabling the proposed method to adeptly model the temporal dynamics of user mobility by effectively capturing long-range dependencies within the input data. The proposed method first computes tokens from the sequence of covariance matrices (CMs) for each SU and processes them in parallel using the SUtransformer network to learn the spatio-temporal features at SUlevel. Subsequently, the collaborative transformer network learns the group-level PU state from all SU-level feature representations. The attention-based sequence pooling method followed by the transformer encoder adjusts the contributions of all tokens. The main goal of predicting the PU states at each SU-level and group-level is to improve detection performance even more. We conducted a sufficient amount of simulations and compared the detection performance of different SS methods. The proposed method is tested under imperfect reporting channel scenarios to show robustness. The efficacy of our method is validated with the simulation results demonstrating its higher performance compared with existing methods in terms of detection probability, sensing error, and classification accuracy.
Knowledge-Driven Cross-Document Relation Extraction
May 22, 2024Relation extraction (RE) is a well-known NLP application often treated as a sentence- or document-level task. However, a handful of recent efforts explore it across documents or in the cross-document setting (CrossDocRE). This is distinct from the single document case because different documents often focus on disparate themes, while text within a document tends to have a single goal. Linking findings from disparate documents to identify new relationships is at the core of the popular literature-based knowledge discovery paradigm in biomedicine and other domains. Current CrossDocRE efforts do not consider domain knowledge, which are often assumed to be known to the reader when documents are authored. Here, we propose a novel approach, KXDocRE, that embed domain knowledge of entities with input text for cross-document RE. Our proposed framework has three main benefits over baselines: 1) it incorporates domain knowledge of entities along with documents' text; 2) it offers interpretability by producing explanatory text for predicted relations between entities 3) it improves performance over the prior methods.
Beyond Spatio-Temporal Representations: Evolving Fourier Transform for Temporal Graphs
Feb 25, 2024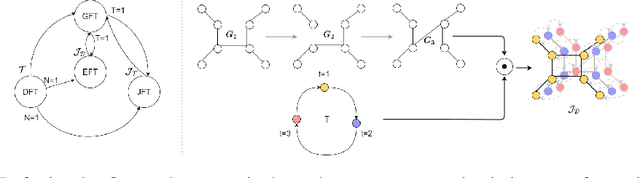
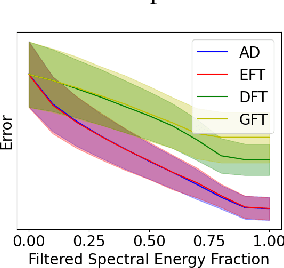
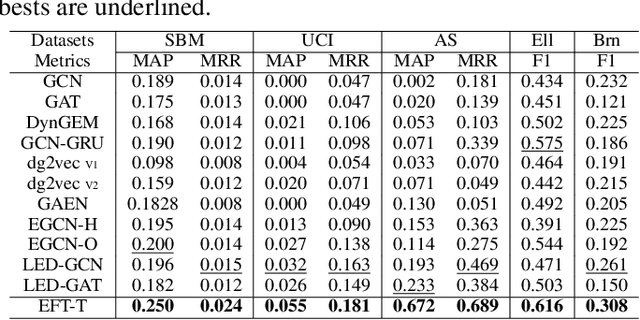
We present the Evolving Graph Fourier Transform (EFT), the first invertible spectral transform that captures evolving representations on temporal graphs. We motivate our work by the inadequacy of existing methods for capturing the evolving graph spectra, which are also computationally expensive due to the temporal aspect along with the graph vertex domain. We view the problem as an optimization over the Laplacian of the continuous time dynamic graph. Additionally, we propose pseudo-spectrum relaxations that decompose the transformation process, making it highly computationally efficient. The EFT method adeptly captures the evolving graph's structural and positional properties, making it effective for downstream tasks on evolving graphs. Hence, as a reference implementation, we develop a simple neural model induced with EFT for capturing evolving graph spectra. We empirically validate our theoretical findings on a number of large-scale and standard temporal graph benchmarks and demonstrate that our model achieves state-of-the-art performance.
Revisiting Document-Level Relation Extraction with Context-Guided Link Prediction
Jan 22, 2024Document-level relation extraction (DocRE) poses the challenge of identifying relationships between entities within a document as opposed to the traditional RE setting where a single sentence is input. Existing approaches rely on logical reasoning or contextual cues from entities. This paper reframes document-level RE as link prediction over a knowledge graph with distinct benefits: 1) Our approach combines entity context with document-derived logical reasoning, enhancing link prediction quality. 2) Predicted links between entities offer interpretability, elucidating employed reasoning. We evaluate our approach on three benchmark datasets: DocRED, ReDocRED, and DWIE. The results indicate that our proposed method outperforms the state-of-the-art models and suggests that incorporating context-based link prediction techniques can enhance the performance of document-level relation extraction models.
ReOnto: A Neuro-Symbolic Approach for Biomedical Relation Extraction
Sep 04, 2023Relation Extraction (RE) is the task of extracting semantic relationships between entities in a sentence and aligning them to relations defined in a vocabulary, which is generally in the form of a Knowledge Graph (KG) or an ontology. Various approaches have been proposed so far to address this task. However, applying these techniques to biomedical text often yields unsatisfactory results because it is hard to infer relations directly from sentences due to the nature of the biomedical relations. To address these issues, we present a novel technique called ReOnto, that makes use of neuro symbolic knowledge for the RE task. ReOnto employs a graph neural network to acquire the sentence representation and leverages publicly accessible ontologies as prior knowledge to identify the sentential relation between two entities. The approach involves extracting the relation path between the two entities from the ontology. We evaluate the effect of using symbolic knowledge from ontologies with graph neural networks. Experimental results on two public biomedical datasets, BioRel and ADE, show that our method outperforms all the baselines (approximately by 3\%).