 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBottom-Up and Top-Down Analysis of Values, Agendas, and Observations in Corpora and LLMs
Nov 06, 2024Large language models (LLMs) generate diverse, situated, persuasive texts from a plurality of potential perspectives, influenced heavily by their prompts and training data. As part of LLM adoption, we seek to characterize - and ideally, manage - the socio-cultural values that they express, for reasons of safety, accuracy, inclusion, and cultural fidelity. We present a validated approach to automatically (1) extracting heterogeneous latent value propositions from texts, (2) assessing resonance and conflict of values with texts, and (3) combining these operations to characterize the pluralistic value alignment of human-sourced and LLM-sourced textual data.
Soft Measures for Extracting Causal Collective Intelligence
Sep 27, 2024



Understanding and modeling collective intelligence is essential for addressing complex social systems. Directed graphs called fuzzy cognitive maps (FCMs) offer a powerful tool for encoding causal mental models, but extracting high-integrity FCMs from text is challenging. This study presents an approach using large language models (LLMs) to automate FCM extraction. We introduce novel graph-based similarity measures and evaluate them by correlating their outputs with human judgments through the Elo rating system. Results show positive correlations with human evaluations, but even the best-performing measure exhibits limitations in capturing FCM nuances. Fine-tuning LLMs improves performance, but existing measures still fall short. This study highlights the need for soft similarity measures tailored to FCM extraction, advancing collective intelligence modeling with NLP.
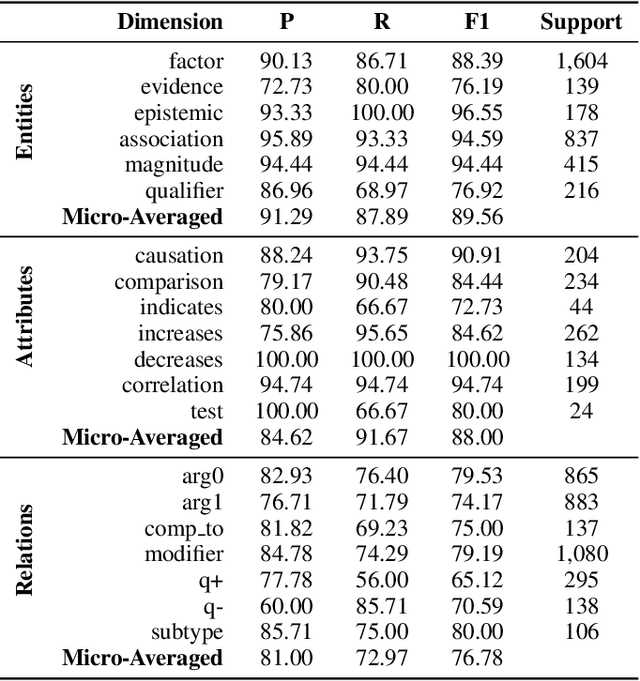
Extracting Fine-Grained Knowledge Graphs of Scientific Claims: Dataset and Transformer-Based Results
Sep 21, 2021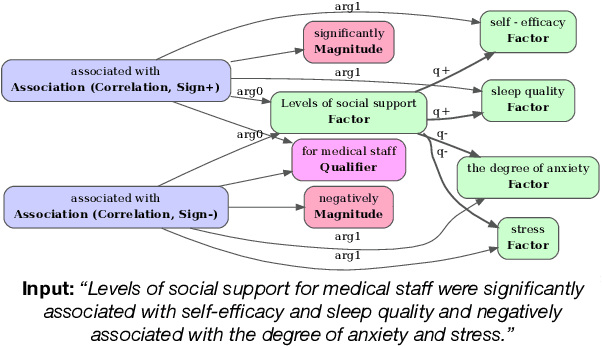
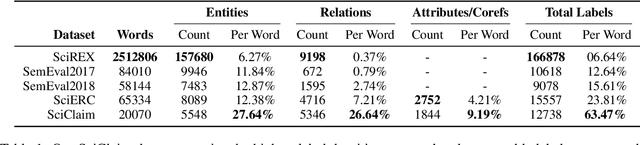
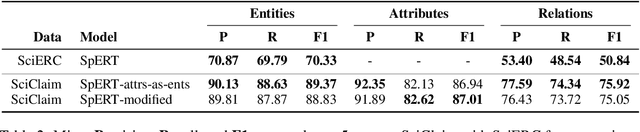
Recent transformer-based approaches demonstrate promising results on relational scientific information extraction. Existing datasets focus on high-level description of how research is carried out. Instead we focus on the subtleties of how experimental associations are presented by building SciClaim, a dataset of scientific claims drawn from Social and Behavior Science (SBS), PubMed, and CORD-19 papers. Our novel graph annotation schema incorporates not only coarse-grained entity spans as nodes and relations as edges between them, but also fine-grained attributes that modify entities and their relations, for a total of 12,738 labels in the corpus. By including more label types and more than twice the label density of previous datasets, SciClaim captures causal, comparative, predictive, statistical, and proportional associations over experimental variables along with their qualifications, subtypes, and evidence. We extend work in transformer-based joint entity and relation extraction to effectively infer our schema, showing the promise of fine-grained knowledge graphs in scientific claims and beyond.
Extracting Qualitative Causal Structure with Transformer-Based NLP
Aug 20, 2021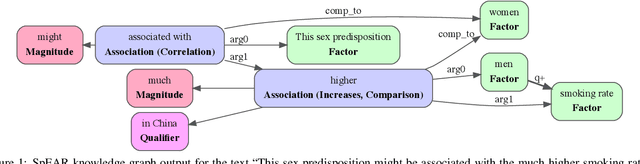


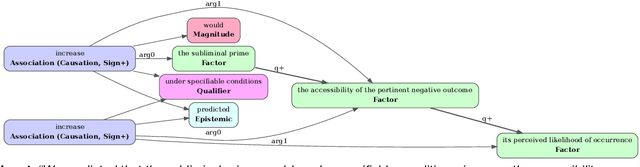
Qualitative causal relationships compactly express the direction, dependency, temporal constraints, and monotonicity constraints of discrete or continuous interactions in the world. In everyday or academic language, we may express interactions between quantities (e.g., sleep decreases stress), between discrete events or entities (e.g., a protein inhibits another protein's transcription), or between intentional or functional factors (e.g., hospital patients pray to relieve their pain). This paper presents a transformer-based NLP architecture that jointly identifies and extracts (1) variables or factors described in language, (2) qualitative causal relationships over these variables, and (3) qualifiers and magnitudes that constrain these causal relationships. We demonstrate this approach and include promising results from in two use cases, processing textual inputs from academic publications, news articles, and social media.
Provenance-Based Assessment of Plans in Context
Nov 03, 2020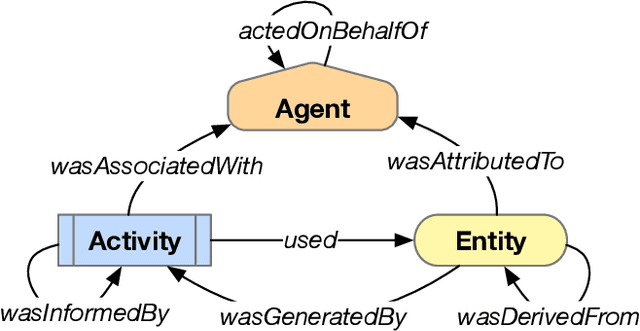
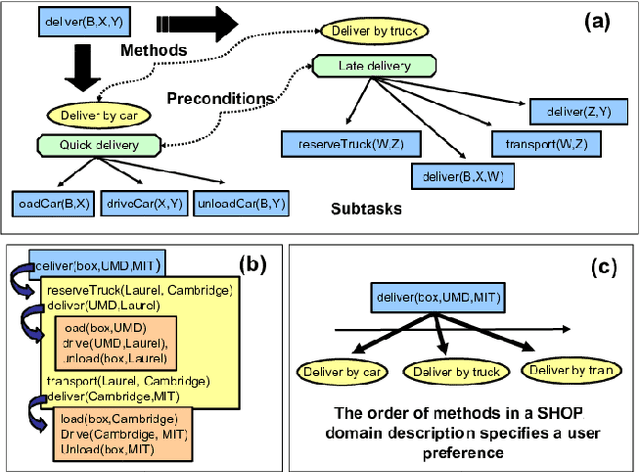
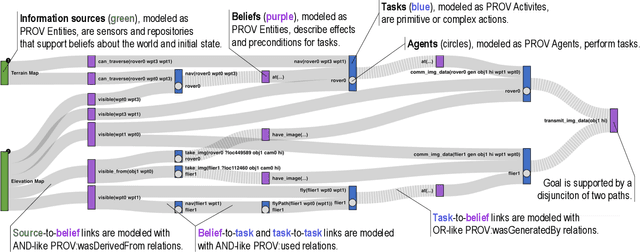
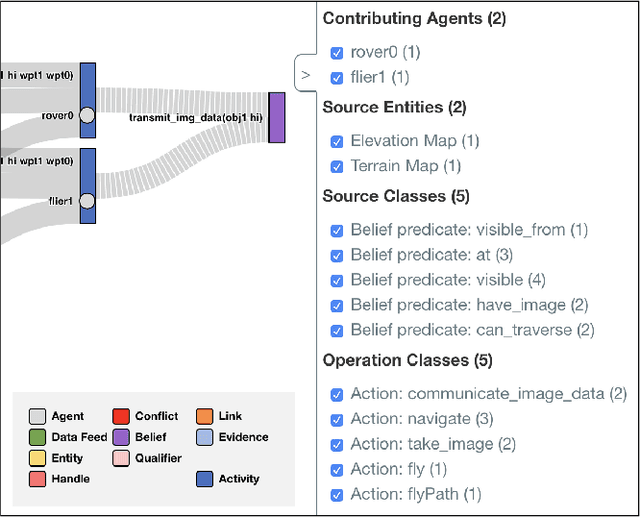
Many real-world planning domains involve diverse information sources, external entities, and variable-reliability agents, all of which may impact the confidence, risk, and sensitivity of plans. Humans reviewing a plan may lack context about these factors; however, this information is available during the domain generation, which means it can also be interwoven into the planner and its resulting plans. This paper presents a provenance-based approach to explaining automated plans. Our approach (1) extends the SHOP3 HTN planner to generate dependency information, (2) transforms the dependency information into an established PROV-O representation, and (3) uses graph propagation and TMS-inspired algorithms to support dynamic and counter-factual assessment of information flow, confidence, and support. We qualified our approach's explanatory scope with respect to explanation targets from the automated planning literature and the information analysis literature, and we demonstrate its ability to assess a plan's pertinence, sensitivity, risk, assumption support, diversity, and relative confidence.
* 9 pages, 7 figures, including in Proceedings of the 2020 ICAPS Workshop on Explainable AI Planning (XAIP)