 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBottom-Up and Top-Down Analysis of Values, Agendas, and Observations in Corpora and LLMs
Nov 06, 2024Large language models (LLMs) generate diverse, situated, persuasive texts from a plurality of potential perspectives, influenced heavily by their prompts and training data. As part of LLM adoption, we seek to characterize - and ideally, manage - the socio-cultural values that they express, for reasons of safety, accuracy, inclusion, and cultural fidelity. We present a validated approach to automatically (1) extracting heterogeneous latent value propositions from texts, (2) assessing resonance and conflict of values with texts, and (3) combining these operations to characterize the pluralistic value alignment of human-sourced and LLM-sourced textual data.
From Stance to Concern: Adaptation of Propositional Analysis to New Tasks and Domains
Mar 20, 2022



We present a generalized paradigm for adaptation of propositional analysis (predicate-argument pairs) to new tasks and domains. We leverage an analogy between stances (belief-driven sentiment) and concerns (topical issues with moral dimensions/endorsements) to produce an explanatory representation. A key contribution is the combination of semi-automatic resource building for extraction of domain-dependent concern types (with 2-4 hours of human labor per domain) and an entirely automatic procedure for extraction of domain-independent moral dimensions and endorsement values. Prudent (automatic) selection of terms from propositional structures for lexical expansion (via semantic similarity) produces new moral dimension lexicons at three levels of granularity beyond a strong baseline lexicon. We develop a ground truth (GT) based on expert annotators and compare our concern detection output to GT, to yield 231% improvement in recall over baseline, with only a 10% loss in precision. F1 yields 66% improvement over baseline and 97.8% of human performance. Our lexically based approach yields large savings over approaches that employ costly human labor and model building. We provide to the community a newly expanded moral dimension/value lexicon, annotation guidelines, and GT.
Extracting Qualitative Causal Structure with Transformer-Based NLP
Aug 20, 2021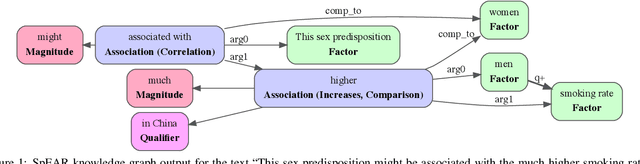
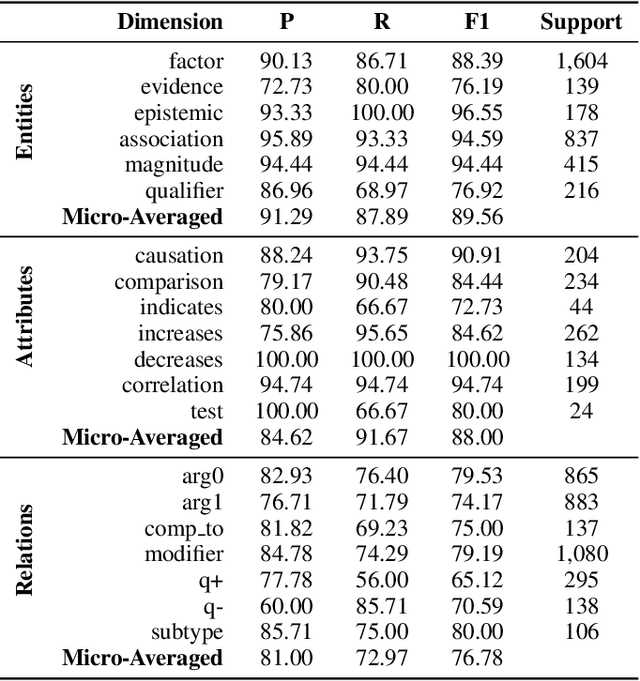


Qualitative causal relationships compactly express the direction, dependency, temporal constraints, and monotonicity constraints of discrete or continuous interactions in the world. In everyday or academic language, we may express interactions between quantities (e.g., sleep decreases stress), between discrete events or entities (e.g., a protein inhibits another protein's transcription), or between intentional or functional factors (e.g., hospital patients pray to relieve their pain). This paper presents a transformer-based NLP architecture that jointly identifies and extracts (1) variables or factors described in language, (2) qualitative causal relationships over these variables, and (3) qualifiers and magnitudes that constrain these causal relationships. We demonstrate this approach and include promising results from in two use cases, processing textual inputs from academic publications, news articles, and social media.