 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Role-Playing Agents Practice What They Preach? Belief-Behavior Consistency in LLM-Based Simulations of Human Trust
Jul 02, 2025As LLMs are increasingly studied as role-playing agents to generate synthetic data for human behavioral research, ensuring that their outputs remain coherent with their assigned roles has become a critical concern. In this paper, we investigate how consistently LLM-based role-playing agents' stated beliefs about the behavior of the people they are asked to role-play ("what they say") correspond to their actual behavior during role-play ("how they act"). Specifically, we establish an evaluation framework to rigorously measure how well beliefs obtained by prompting the model can predict simulation outcomes in advance. Using an augmented version of the GenAgents persona bank and the Trust Game (a standard economic game used to quantify players' trust and reciprocity), we introduce a belief-behavior consistency metric to systematically investigate how it is affected by factors such as: (1) the types of beliefs we elicit from LLMs, like expected outcomes of simulations versus task-relevant attributes of individual characters LLMs are asked to simulate; (2) when and how we present LLMs with relevant information about Trust Game; and (3) how far into the future we ask the model to forecast its actions. We also explore how feasible it is to impose a researcher's own theoretical priors in the event that the originally elicited beliefs are misaligned with research objectives. Our results reveal systematic inconsistencies between LLMs' stated (or imposed) beliefs and the outcomes of their role-playing simulation, at both an individual- and population-level. Specifically, we find that, even when models appear to encode plausible beliefs, they may fail to apply them in a consistent way. These findings highlight the need to identify how and when LLMs' stated beliefs align with their simulated behavior, allowing researchers to use LLM-based agents appropriately in behavioral studies.
NLP as a Lens for Causal Analysis and Perception Mining to Infer Mental Health on Social Media
Feb 01, 2023



Interactions among humans on social media often convey intentions behind their actions, yielding a psychological language resource for Mental Health Analysis (MHA) of online users. The success of Computational Intelligence Techniques (CIT) for inferring mental illness from such social media resources points to NLP as a lens for causal analysis and perception mining. However, we argue that more consequential and explainable research is required for optimal impact on clinical psychology practice and personalized mental healthcare. To bridge this gap, we posit two significant dimensions: (1) Causal analysis to illustrate a cause and effect relationship in the user generated text; (2) Perception mining to infer psychological perspectives of social effects on online users intentions. Within the scope of Natural Language Processing (NLP), we further explore critical areas of inquiry associated with these two dimensions, specifically through recent advancements in discourse analysis. This position paper guides the community to explore solutions in this space and advance the state of practice in developing conversational agents for inferring mental health from social media. We advocate for a more explainable approach toward modeling computational psychology problems through the lens of language as we observe an increased number of research contributions in dataset and problem formulation for causal relation extraction and perception enhancements while inferring mental states.
CAMS: An Annotated Corpus for Causal Analysis of Mental Health Issues in Social Media Posts
Jul 11, 2022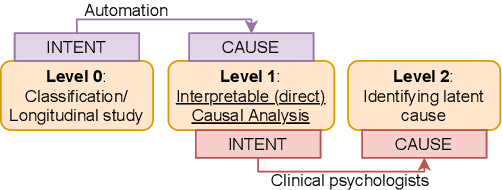
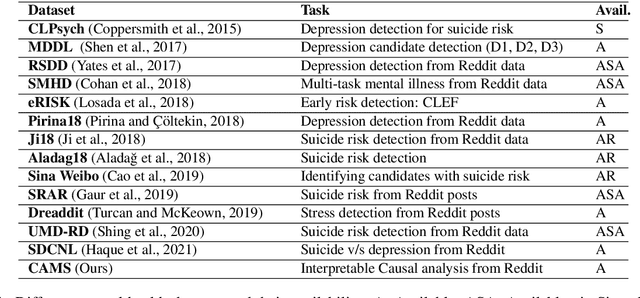
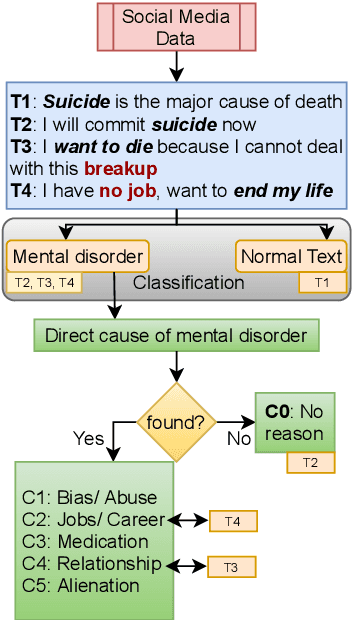

Research community has witnessed substantial growth in the detection of mental health issues and their associated reasons from analysis of social media. We introduce a new dataset for Causal Analysis of Mental health issues in Social media posts (CAMS). Our contributions for causal analysis are two-fold: causal interpretation and causal categorization. We introduce an annotation schema for this task of causal analysis. We demonstrate the efficacy of our schema on two different datasets: (i) crawling and annotating 3155 Reddit posts and (ii) re-annotating the publicly available SDCNL dataset of 1896 instances for interpretable causal analysis. We further combine these into the CAMS dataset and make this resource publicly available along with associated source code: https://github.com/drmuskangarg/CAMS. We present experimental results of models learned from CAMS dataset and demonstrate that a classic Logistic Regression model outperforms the next best (CNN-LSTM) model by 4.9\% accuracy.
* 10 pages
From Stance to Concern: Adaptation of Propositional Analysis to New Tasks and Domains
Mar 20, 2022



We present a generalized paradigm for adaptation of propositional analysis (predicate-argument pairs) to new tasks and domains. We leverage an analogy between stances (belief-driven sentiment) and concerns (topical issues with moral dimensions/endorsements) to produce an explanatory representation. A key contribution is the combination of semi-automatic resource building for extraction of domain-dependent concern types (with 2-4 hours of human labor per domain) and an entirely automatic procedure for extraction of domain-independent moral dimensions and endorsement values. Prudent (automatic) selection of terms from propositional structures for lexical expansion (via semantic similarity) produces new moral dimension lexicons at three levels of granularity beyond a strong baseline lexicon. We develop a ground truth (GT) based on expert annotators and compare our concern detection output to GT, to yield 231% improvement in recall over baseline, with only a 10% loss in precision. F1 yields 66% improvement over baseline and 97.8% of human performance. Our lexically based approach yields large savings over approaches that employ costly human labor and model building. We provide to the community a newly expanded moral dimension/value lexicon, annotation guidelines, and GT.