 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompact Multimodal Language Models as Robust OCR Alternatives for Noisy Textual Clinical Reports
Nov 17, 2025



Digitization of medical records often relies on smartphone photographs of printed reports, producing images degraded by blur, shadows, and other noise. Conventional OCR systems, optimized for clean scans, perform poorly under such real-world conditions. This study evaluates compact multimodal language models as privacy-preserving alternatives for transcribing noisy clinical documents. Using obstetric ultrasound reports written in regionally inflected medical English common to Indian healthcare settings, we compare eight systems in terms of transcription accuracy, noise sensitivity, numeric accuracy, and computational efficiency. Compact multimodal models consistently outperform both classical and neural OCR pipelines. Despite higher computational costs, their robustness and linguistic adaptability position them as viable candidates for on-premises healthcare digitization.
Evaluating Structured Output Robustness of Small Language Models for Open Attribute-Value Extraction from Clinical Notes
Jul 02, 2025We present a comparative analysis of the parseability of structured outputs generated by small language models for open attribute-value extraction from clinical notes. We evaluate three widely used serialization formats: JSON, YAML, and XML, and find that JSON consistently yields the highest parseability. Structural robustness improves with targeted prompting and larger models, but declines for longer documents and certain note types. Our error analysis identifies recurring format-specific failure patterns. These findings offer practical guidance for selecting serialization formats and designing prompts when deploying language models in privacy-sensitive clinical settings.
From Annotation to Adaptation: Metrics, Synthetic Data, and Aspect Extraction for Aspect-Based Sentiment Analysis with Large Language Models
Mar 26, 2025


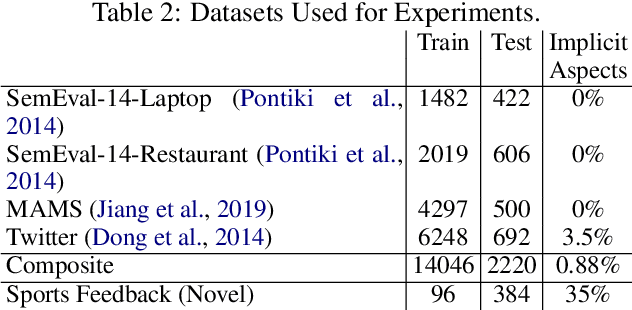
This study examines the performance of Large Language Models (LLMs) in Aspect-Based Sentiment Analysis (ABSA), with a focus on implicit aspect extraction in a novel domain. Using a synthetic sports feedback dataset, we evaluate open-weight LLMs' ability to extract aspect-polarity pairs and propose a metric to facilitate the evaluation of aspect extraction with generative models. Our findings highlight both the potential and limitations of LLMs in the ABSA task.
Clinical Insights: A Comprehensive Review of Language Models in Medicine
Aug 21, 2024


This paper provides a detailed examination of the advancements and applications of large language models in the healthcare sector, with a particular emphasis on clinical applications. The study traces the evolution of LLMs from their foundational technologies to the latest developments in domain-specific models and multimodal integration. It explores the technical progression from encoder-based models requiring fine-tuning to sophisticated approaches that integrate textual, visual, and auditory data, thereby facilitating comprehensive AI solutions in healthcare. The paper discusses both the opportunities these technologies present for enhancing clinical efficiency and the challenges they pose in terms of ethics, data privacy, and implementation. Additionally, it critically evaluates the deployment strategies of LLMs, emphasizing the necessity of open-source models to ensure data privacy and adaptability within healthcare environments. Future research directions are proposed, focusing on empirical studies to evaluate the real-world efficacy of LLMs in healthcare and the development of open datasets for further research. This review aims to provide a comprehensive resource for both newcomers and multidisciplinary researchers interested in the intersection of AI and healthcare.
Augmenting Reddit Posts to Determine Wellness Dimensions impacting Mental Health
Jun 06, 2023Amid ongoing health crisis, there is a growing necessity to discern possible signs of Wellness Dimensions (WD) manifested in self-narrated text. As the distribution of WD on social media data is intrinsically imbalanced, we experiment the generative NLP models for data augmentation to enable further improvement in the pre-screening task of classifying WD. To this end, we propose a simple yet effective data augmentation approach through prompt-based Generative NLP models, and evaluate the ROUGE scores and syntactic/semantic similarity among existing interpretations and augmented data. Our approach with ChatGPT model surpasses all the other methods and achieves improvement over baselines such as Easy-Data Augmentation and Backtranslation. Introducing data augmentation to generate more training samples and balanced dataset, results in the improved F-score and the Matthew's Correlation Coefficient for upto 13.11% and 15.95%, respectively.
An Annotated Dataset for Explainable Interpersonal Risk Factors of Mental Disturbance in Social Media Posts
May 30, 2023With a surge in identifying suicidal risk and its severity in social media posts, we argue that a more consequential and explainable research is required for optimal impact on clinical psychology practice and personalized mental healthcare. The success of computational intelligence techniques for inferring mental illness from social media resources, points to natural language processing as a lens for determining Interpersonal Risk Factors (IRF) in human writings. Motivated with limited availability of datasets for social NLP research community, we construct and release a new annotated dataset with human-labelled explanations and classification of IRF affecting mental disturbance on social media: (i) Thwarted Belongingness (TBe), and (ii) Perceived Burdensomeness (PBu). We establish baseline models on our dataset facilitating future research directions to develop real-time personalized AI models by detecting patterns of TBe and PBu in emotional spectrum of user's historical social media profile.
NODDLE: Node2vec based deep learning model for link prediction
May 25, 2023Computing the probability of an edge's existence in a graph network is known as link prediction. While traditional methods calculate the similarity between two given nodes in a static network, recent research has focused on evaluating networks that evolve dynamically. Although deep learning techniques and network representation learning algorithms, such as node2vec, show remarkable improvements in prediction accuracy, the Stochastic Gradient Descent (SGD) method of node2vec tends to fall into a mediocre local optimum value due to a shortage of prior network information, resulting in failure to capture the global structure of the network. To tackle this problem, we propose NODDLE (integration of NOde2vec anD Deep Learning mEthod), a deep learning model which incorporates the features extracted by node2vec and feeds them into a four layer hidden neural network. NODDLE takes advantage of adaptive learning optimizers such as Adam, Adamax, Adadelta, and Adagrad to improve the performance of link prediction. Experimental results show that this method yields better results than the traditional methods on various social network datasets.
CAMS: An Annotated Corpus for Causal Analysis of Mental Health Issues in Social Media Posts
Jul 11, 2022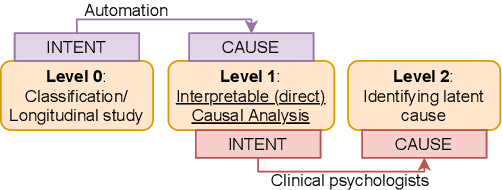
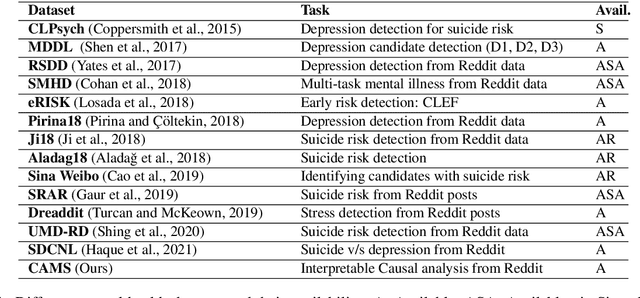
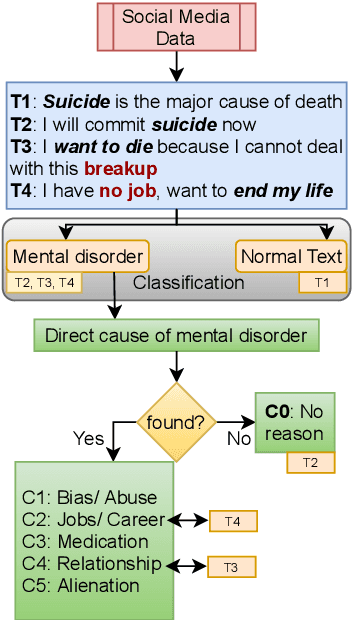

Research community has witnessed substantial growth in the detection of mental health issues and their associated reasons from analysis of social media. We introduce a new dataset for Causal Analysis of Mental health issues in Social media posts (CAMS). Our contributions for causal analysis are two-fold: causal interpretation and causal categorization. We introduce an annotation schema for this task of causal analysis. We demonstrate the efficacy of our schema on two different datasets: (i) crawling and annotating 3155 Reddit posts and (ii) re-annotating the publicly available SDCNL dataset of 1896 instances for interpretable causal analysis. We further combine these into the CAMS dataset and make this resource publicly available along with associated source code: https://github.com/drmuskangarg/CAMS. We present experimental results of models learned from CAMS dataset and demonstrate that a classic Logistic Regression model outperforms the next best (CNN-LSTM) model by 4.9\% accuracy.
* 10 pages
A Survey on Automated Sarcasm Detection on Twitter
Feb 05, 2022Automatic sarcasm detection is a growing field in computer science. Short text messages are increasingly used for communication, especially over social media platforms such as Twitter. Due to insufficient or missing context, unidentified sarcasm in these messages can invert the meaning of a statement, leading to confusion and communication failures. This paper covers a variety of current methods used for sarcasm detection, including detection by context, posting history and machine learning models. Additionally, a shift towards deep learning methods is observable, likely due to the benefit of using a model with induced instead of discrete features combined with the innovation of transformers.
Collision Detection: An Improved Deep Learning Approach Using SENet and ResNext
Jan 13, 2022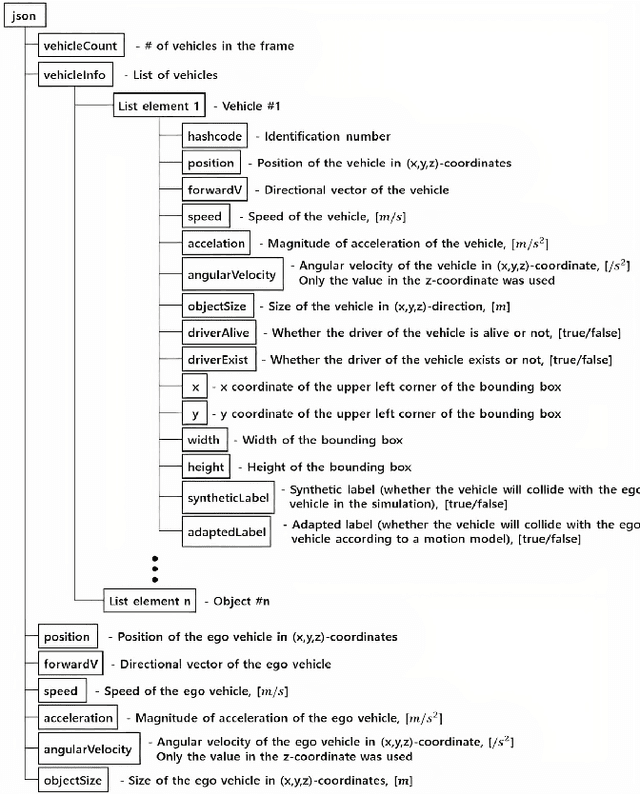
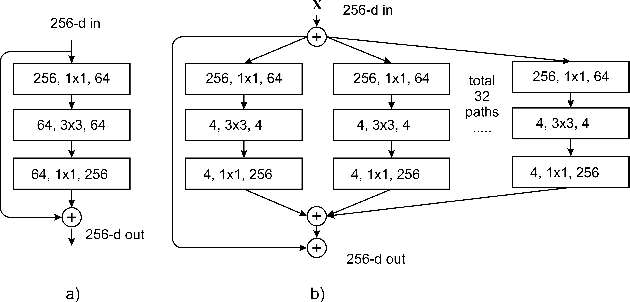
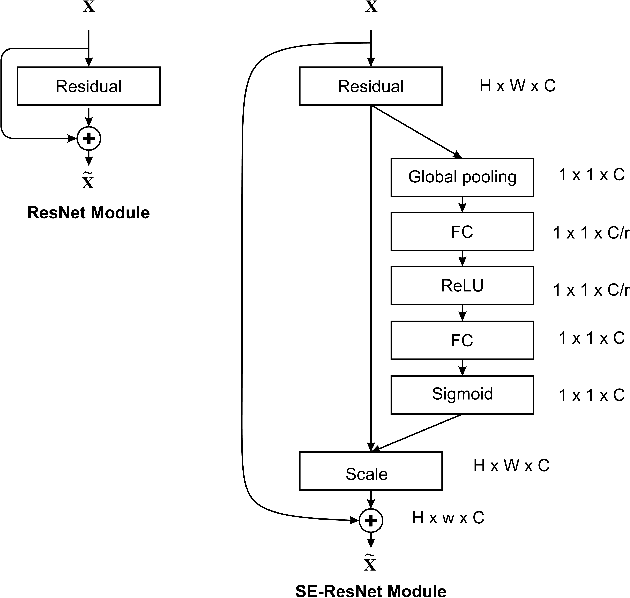
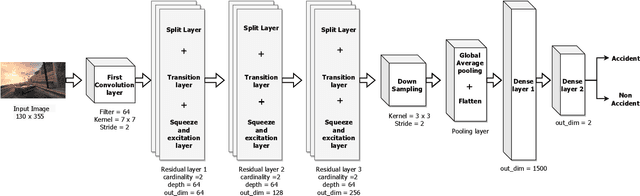
In recent days, with increased population and traffic on roadways, vehicle collision is one of the leading causes of death worldwide. The automotive industry is motivated on developing techniques to use sensors and advancements in the field of computer vision to build collision detection and collision prevention systems to assist drivers. In this article, a deep-learning-based model comprising of ResNext architecture with SENet blocks is proposed. The performance of the model is compared to popular deep learning models like VGG16, VGG19, Resnet50, and stand-alone ResNext. The proposed model outperforms the existing baseline models achieving a ROC-AUC of 0.91 using a significantly less proportion of the GTACrash synthetic data for training, thus reducing the computational overhead.