 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollision Detection: An Improved Deep Learning Approach Using SENet and ResNext
Jan 13, 2022
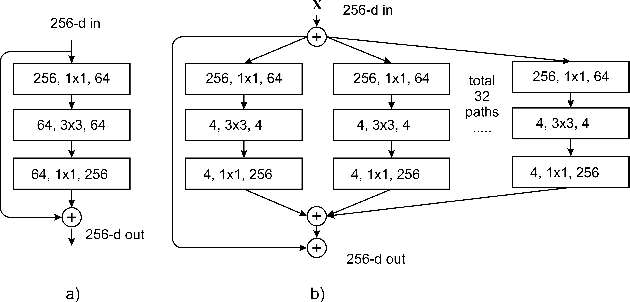
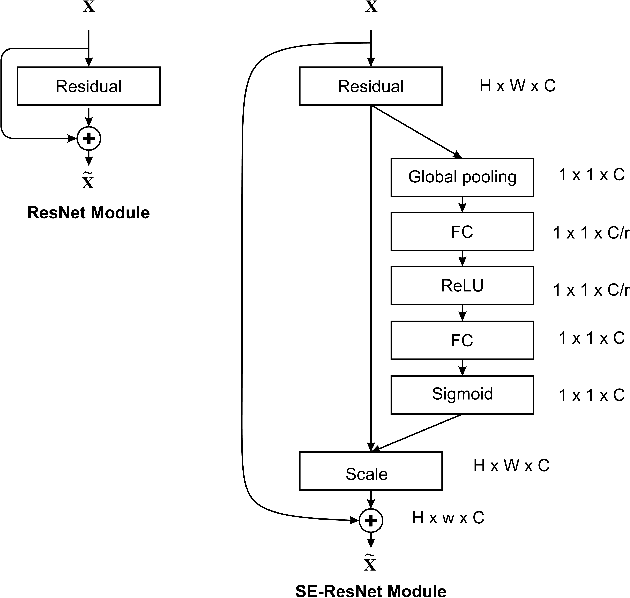
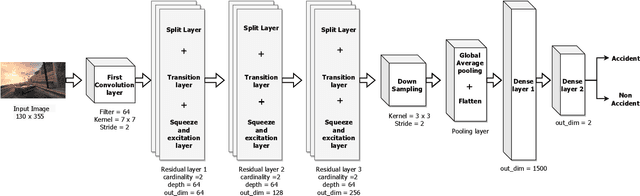
In recent days, with increased population and traffic on roadways, vehicle collision is one of the leading causes of death worldwide. The automotive industry is motivated on developing techniques to use sensors and advancements in the field of computer vision to build collision detection and collision prevention systems to assist drivers. In this article, a deep-learning-based model comprising of ResNext architecture with SENet blocks is proposed. The performance of the model is compared to popular deep learning models like VGG16, VGG19, Resnet50, and stand-alone ResNext. The proposed model outperforms the existing baseline models achieving a ROC-AUC of 0.91 using a significantly less proportion of the GTACrash synthetic data for training, thus reducing the computational overhead.
Automating Transfer Credit Assessment in Student Mobility -- A Natural Language Processing-based Approach
Apr 05, 2021
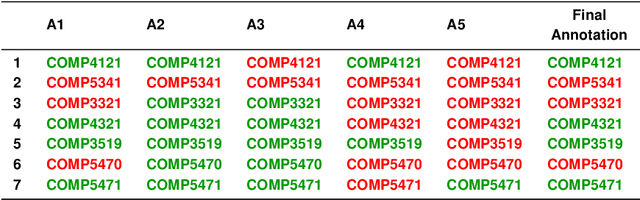
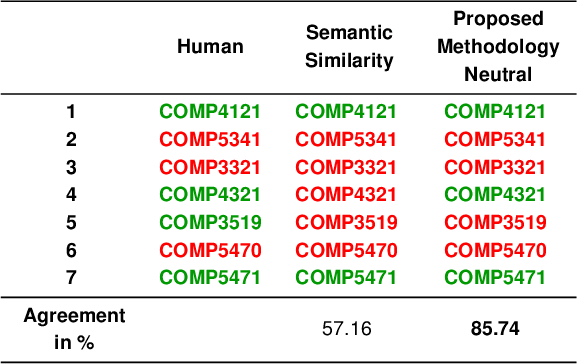
Student mobility or academic mobility involves students moving between institutions during their post-secondary education, and one of the challenging tasks in this process is to assess the transfer credits to be offered to the incoming student. In general, this process involves domain experts comparing the learning outcomes of the courses, to decide on offering transfer credits to the incoming students. This manual implementation is not only labor-intensive but also influenced by undue bias and administrative complexity. The proposed research article focuses on identifying a model that exploits the advancements in the field of Natural Language Processing (NLP) to effectively automate this process. Given the unique structure, domain specificity, and complexity of learning outcomes (LOs), a need for designing a tailor-made model arises. The proposed model uses a clustering-inspired methodology based on knowledge-based semantic similarity measures to assess the taxonomic similarity of LOs and a transformer-based semantic similarity model to assess the semantic similarity of the LOs. The similarity between LOs is further aggregated to form course to course similarity. Due to the lack of quality benchmark datasets, a new benchmark dataset containing seven course-to-course similarity measures is proposed. Understanding the inherent need for flexibility in the decision-making process the aggregation part of the model offers tunable parameters to accommodate different scenarios. While providing an efficient model to assess the similarity between courses with existing resources, this research work steers future research attempts to apply NLP in the field of articulation in an ideal direction by highlighting the persisting research gaps.
Domain Specific Complex Sentence (DCSC) Semantic Similarity Dataset
Oct 23, 2020

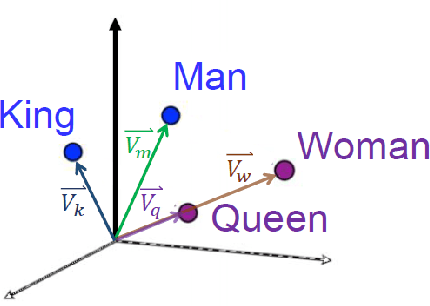
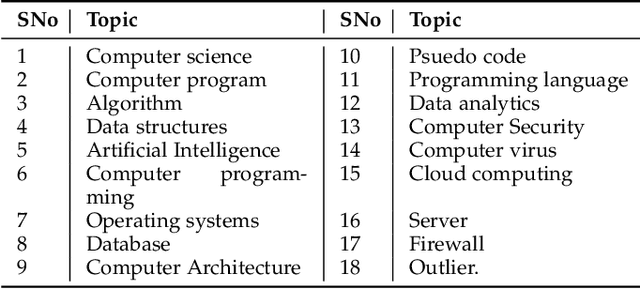
Semantic textual similarity is one of the open research challenges in the field of Natural Language Processing. Extensive research has been carried out in this field and near-perfect results are achieved by recent transformed based models in existing benchmark datasets like STS dataset and SICK dataset. In this paper, we study the sentences in these datasets and analyze the sensitivity of various word embeddings with respect to the complexity of the sentences. We propose a new benchmark dataset -- the Domain Specific Complex Sentences (DSCS) dataset comprising of 50 sentence pairs with associated semantic similarity values provided by 15 human annotators. Readability analysis is performed to highlight the increase in complexity of the sentences in the existing benchmark datasets and those in the proposed dataset. Further, we perform a comparative analysis of the performance of various word embeddings and the results justify the hypothesis that the performance of the word embeddings decrease with an increase in complexity of the sentences.
Evolution of Semantic Similarity -- A Survey
Apr 19, 2020

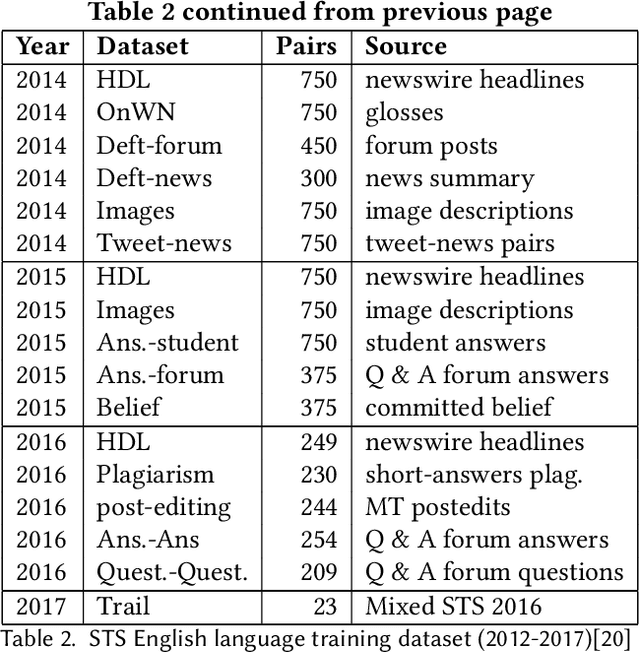

Estimating the semantic similarity between text data is one of the challenging and open research problems in the field of Natural Language Processing (NLP). The versatility of natural language makes it difficult to define rule-based methods for determining semantic similarity measures. In order to address this issue, various semantic similarity methods have been proposed over the years. This survey article traces the evolution of such methods, categorizing them based on their underlying principles as knowledge-based, corpus-based, deep neural network-based methods, and hybrid methods. Discussing the strengths and weaknesses of each method, this survey provides a comprehensive view of existing systems in place, for new researchers to experiment and develop innovative ideas to address the issue of semantic similarity.