 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Specific Complex Sentence (DCSC) Semantic Similarity Dataset
Paper and Code
Oct 23, 2020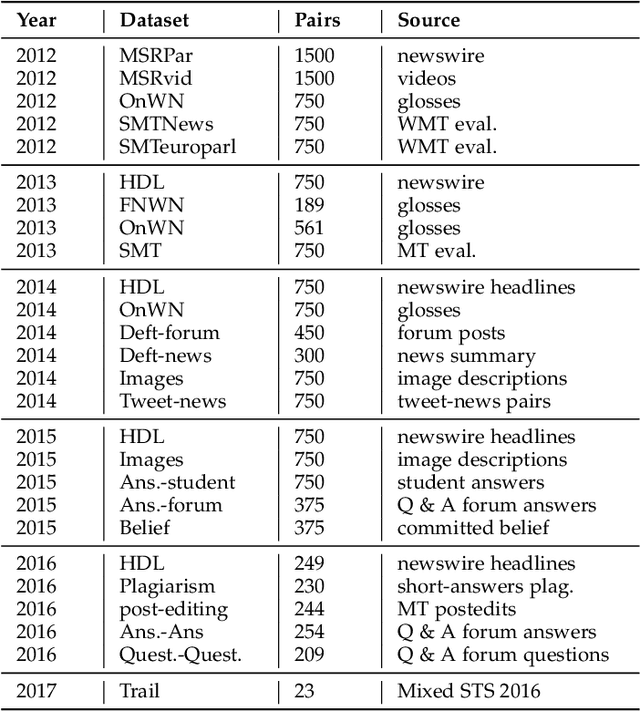

Semantic textual similarity is one of the open research challenges in the field of Natural Language Processing. Extensive research has been carried out in this field and near-perfect results are achieved by recent transformed based models in existing benchmark datasets like STS dataset and SICK dataset. In this paper, we study the sentences in these datasets and analyze the sensitivity of various word embeddings with respect to the complexity of the sentences. We propose a new benchmark dataset -- the Domain Specific Complex Sentences (DSCS) dataset comprising of 50 sentence pairs with associated semantic similarity values provided by 15 human annotators. Readability analysis is performed to highlight the increase in complexity of the sentences in the existing benchmark datasets and those in the proposed dataset. Further, we perform a comparative analysis of the performance of various word embeddings and the results justify the hypothesis that the performance of the word embeddings decrease with an increase in complexity of the sentences.