 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Rise of Small Language Models in Healthcare: A Comprehensive Survey
Apr 23, 2025



Despite substantial progress in healthcare applications driven by large language models (LLMs), growing concerns around data privacy, and limited resources; the small language models (SLMs) offer a scalable and clinically viable solution for efficient performance in resource-constrained environments for next-generation healthcare informatics. Our comprehensive survey presents a taxonomic framework to identify and categorize them for healthcare professionals and informaticians. The timeline of healthcare SLM contributions establishes a foundational framework for analyzing models across three dimensions: NLP tasks, stakeholder roles, and the continuum of care. We present a taxonomic framework to identify the architectural foundations for building models from scratch; adapting SLMs to clinical precision through prompting, instruction fine-tuning, and reasoning; and accessibility and sustainability through compression techniques. Our primary objective is to offer a comprehensive survey for healthcare professionals, introducing recent innovations in model optimization and equipping them with curated resources to support future research and development in the field. Aiming to showcase the groundbreaking advancements in SLMs for healthcare, we present a comprehensive compilation of experimental results across widely studied NLP tasks in healthcare to highlight the transformative potential of SLMs in healthcare. The updated repository is available at Github
Reliability Analysis of Psychological Concept Extraction and Classification in User-penned Text
Jan 12, 2024



The social NLP research community witness a recent surge in the computational advancements of mental health analysis to build responsible AI models for a complex interplay between language use and self-perception. Such responsible AI models aid in quantifying the psychological concepts from user-penned texts on social media. On thinking beyond the low-level (classification) task, we advance the existing binary classification dataset, towards a higher-level task of reliability analysis through the lens of explanations, posing it as one of the safety measures. We annotate the LoST dataset to capture nuanced textual cues that suggest the presence of low self-esteem in the posts of Reddit users. We further state that the NLP models developed for determining the presence of low self-esteem, focus more on three types of textual cues: (i) Trigger: words that triggers mental disturbance, (ii) LoST indicators: text indicators emphasizing low self-esteem, and (iii) Consequences: words describing the consequences of mental disturbance. We implement existing classifiers to examine the attention mechanism in pre-trained language models (PLMs) for a domain-specific psychology-grounded task. Our findings suggest the need of shifting the focus of PLMs from Trigger and Consequences to a more comprehensive explanation, emphasizing LoST indicators while determining low self-esteem in Reddit posts.
InterPrompt: Interpretable Prompting for Interrelated Interpersonal Risk Factors in Reddit Posts
Nov 21, 2023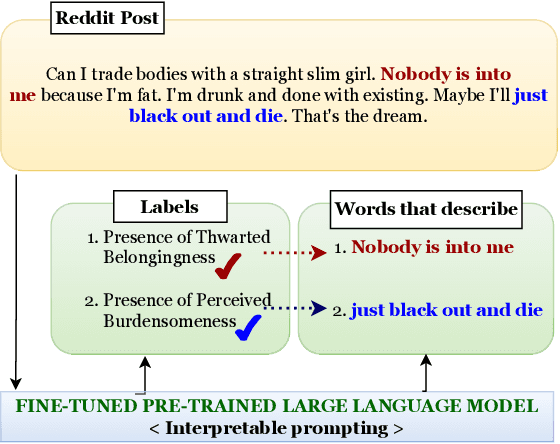

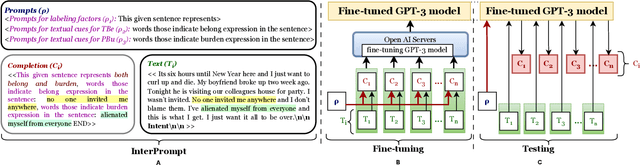

Mental health professionals and clinicians have observed the upsurge of mental disorders due to Interpersonal Risk Factors (IRFs). To simulate the human-in-the-loop triaging scenario for early detection of mental health disorders, we recognized textual indications to ascertain these IRFs : Thwarted Belongingness (TBe) and Perceived Burdensomeness (PBu) within personal narratives. In light of this, we use N-shot learning with GPT-3 model on the IRF dataset, and underscored the importance of fine-tuning GPT-3 model to incorporate the context-specific sensitivity and the interconnectedness of textual cues that represent both IRFs. In this paper, we introduce an Interpretable Prompting (InterPrompt)} method to boost the attention mechanism by fine-tuning the GPT-3 model. This allows a more sophisticated level of language modification by adjusting the pre-trained weights. Our model learns to detect usual patterns and underlying connections across both the IRFs, which leads to better system-level explainability and trustworthiness. The results of our research demonstrate that all four variants of GPT-3 model, when fine-tuned with InterPrompt, perform considerably better as compared to the baseline methods, both in terms of classification and explanation generation.
LOST: A Mental Health Dataset of Low Self-esteem in Reddit Posts
Jun 08, 2023

Low self-esteem and interpersonal needs (i.e., thwarted belongingness (TB) and perceived burdensomeness (PB)) have a major impact on depression and suicide attempts. Individuals seek social connectedness on social media to boost and alleviate their loneliness. Social media platforms allow people to express their thoughts, experiences, beliefs, and emotions. Prior studies on mental health from social media have focused on symptoms, causes, and disorders. Whereas an initial screening of social media content for interpersonal risk factors and low self-esteem may raise early alerts and assign therapists to at-risk users of mental disturbance. Standardized scales measure self-esteem and interpersonal needs from questions created using psychological theories. In the current research, we introduce a psychology-grounded and expertly annotated dataset, LoST: Low Self esTeem, to study and detect low self-esteem on Reddit. Through an annotation approach involving checks on coherence, correctness, consistency, and reliability, we ensure gold-standard for supervised learning. We present results from different deep language models tested using two data augmentation techniques. Our findings suggest developing a class of language models that infuses psychological and clinical knowledge.
Augmenting Reddit Posts to Determine Wellness Dimensions impacting Mental Health
Jun 06, 2023Amid ongoing health crisis, there is a growing necessity to discern possible signs of Wellness Dimensions (WD) manifested in self-narrated text. As the distribution of WD on social media data is intrinsically imbalanced, we experiment the generative NLP models for data augmentation to enable further improvement in the pre-screening task of classifying WD. To this end, we propose a simple yet effective data augmentation approach through prompt-based Generative NLP models, and evaluate the ROUGE scores and syntactic/semantic similarity among existing interpretations and augmented data. Our approach with ChatGPT model surpasses all the other methods and achieves improvement over baselines such as Easy-Data Augmentation and Backtranslation. Introducing data augmentation to generate more training samples and balanced dataset, results in the improved F-score and the Matthew's Correlation Coefficient for upto 13.11% and 15.95%, respectively.
Development of Clinical Concept Extraction Applications: A Methodology Review
Oct 28, 2019
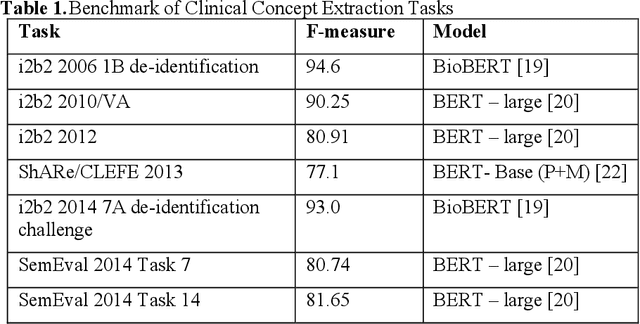
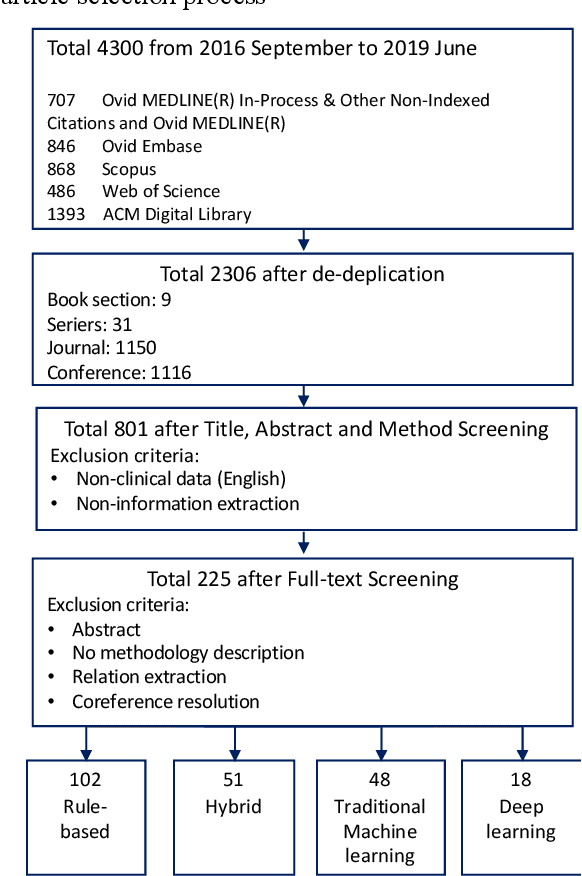
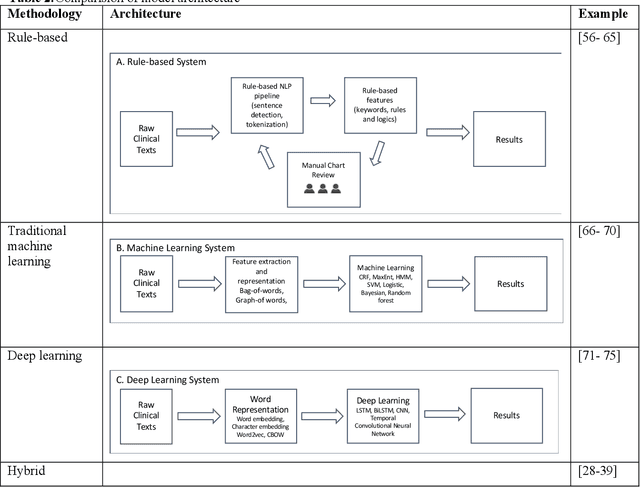
Our study provided a review of the development of clinical concept extraction applications from January 2009 to June 2019. We hope, through the studying of different approaches with variant clinical context, can enhance the decision making for the development of clinical concept extraction.