 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Rise of Small Language Models in Healthcare: A Comprehensive Survey
Apr 23, 2025Despite substantial progress in healthcare applications driven by large language models (LLMs), growing concerns around data privacy, and limited resources; the small language models (SLMs) offer a scalable and clinically viable solution for efficient performance in resource-constrained environments for next-generation healthcare informatics. Our comprehensive survey presents a taxonomic framework to identify and categorize them for healthcare professionals and informaticians. The timeline of healthcare SLM contributions establishes a foundational framework for analyzing models across three dimensions: NLP tasks, stakeholder roles, and the continuum of care. We present a taxonomic framework to identify the architectural foundations for building models from scratch; adapting SLMs to clinical precision through prompting, instruction fine-tuning, and reasoning; and accessibility and sustainability through compression techniques. Our primary objective is to offer a comprehensive survey for healthcare professionals, introducing recent innovations in model optimization and equipping them with curated resources to support future research and development in the field. Aiming to showcase the groundbreaking advancements in SLMs for healthcare, we present a comprehensive compilation of experimental results across widely studied NLP tasks in healthcare to highlight the transformative potential of SLMs in healthcare. The updated repository is available at Github
State-of-the-Art Translation of Text-to-Gloss using mBART : A case study of Bangla
Apr 03, 2025Despite a large deaf and dumb population of 1.7 million, Bangla Sign Language (BdSL) remains a understudied domain. Specifically, there are no works on Bangla text-to-gloss translation task. To address this gap, we begin by addressing the dataset problem. We take inspiration from grammatical rule based gloss generation used in Germany and American sign langauage (ASL) and adapt it for BdSL. We also leverage LLM to generate synthetic data and use back-translation, text generation for data augmentation. With dataset prepared, we started experimentation. We fine-tuned pretrained mBART-50 and mBERT-multiclass-uncased model on our dataset. We also trained GRU, RNN and a novel seq-to-seq model with multi-head attention. We observe significant high performance (ScareBLEU=79.53) with fine-tuning pretrained mBART-50 multilingual model from Facebook. We then explored why we observe such high performance with mBART. We soon notice an interesting property of mBART -- it was trained on shuffled and masked text data. And as we know, gloss form has shuffling property. So we hypothesize that mBART is inherently good at text-to-gloss tasks. To find support against this hypothesis, we trained mBART-50 on PHOENIX-14T benchmark and evaluated it with existing literature. Our mBART-50 finetune demonstrated State-of-the-Art performance on PHOENIX-14T benchmark, far outperforming existing models in all 6 metrics (ScareBLEU = 63.89, BLEU-1 = 55.14, BLEU-2 = 38.07, BLEU-3 = 27.13, BLEU-4 = 20.68, COMET = 0.624). Based on the results, this study proposes a new paradigm for text-to-gloss task using mBART models. Additionally, our results show that BdSL text-to-gloss task can greatly benefit from rule-based synthetic dataset.
Sequential Ensemble Learning for Outlier Detection: A Bias-Variance Perspective
Sep 18, 2016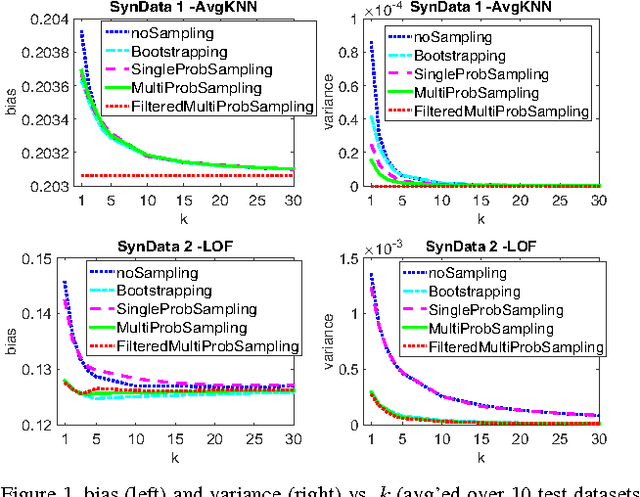


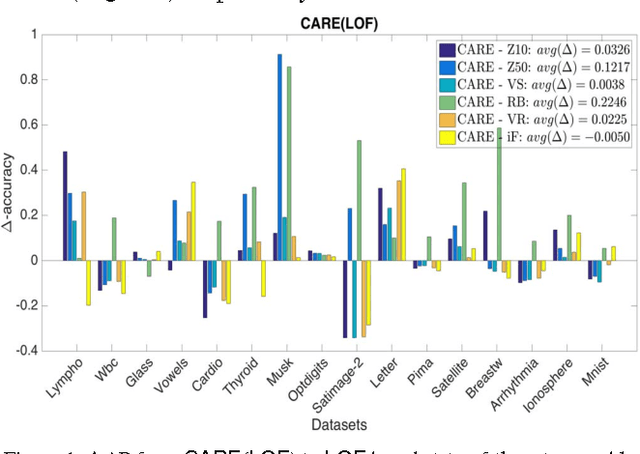
Ensemble methods for classification and clustering have been effectively used for decades, while ensemble learning for outlier detection has only been studied recently. In this work, we design a new ensemble approach for outlier detection in multi-dimensional point data, which provides improved accuracy by reducing error through both bias and variance. Although classification and outlier detection appear as different problems, their theoretical underpinnings are quite similar in terms of the bias-variance trade-off [1], where outlier detection is considered as a binary classification task with unobserved labels but a similar bias-variance decomposition of error. In this paper, we propose a sequential ensemble approach called CARE that employs a two-phase aggregation of the intermediate results in each iteration to reach the final outcome. Unlike existing outlier ensembles which solely incorporate a parallel framework by aggregating the outcomes of independent base detectors to reduce variance, our ensemble incorporates both the parallel and sequential building blocks to reduce bias as well as variance by ($i$) successively eliminating outliers from the original dataset to build a better data model on which outlierness is estimated (sequentially), and ($ii$) combining the results from individual base detectors and across iterations (parallelly). Through extensive experiments on sixteen real-world datasets mainly from the UCI machine learning repository [2], we show that CARE performs significantly better than or at least similar to the individual baselines. We also compare CARE with the state-of-the-art outlier ensembles where it also provides significant improvement when it is the winner and remains close otherwise.
Less is More: Building Selective Anomaly Ensembles
Jan 08, 2015

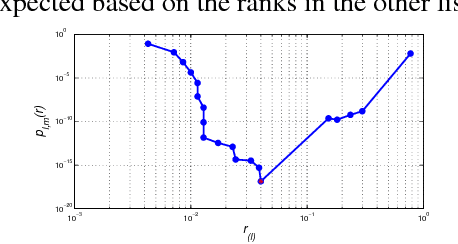

Ensemble techniques for classification and clustering have long proven effective, yet anomaly ensembles have been barely studied. In this work, we tap into this gap and propose a new ensemble approach for anomaly mining, with application to event detection in temporal graphs. Our method aims to combine results from heterogeneous detectors with varying outputs, and leverage the evidence from multiple sources to yield better performance. However, trusting all the results may deteriorate the overall ensemble accuracy, as some detectors may fall short and provide inaccurate results depending on the nature of the data in hand. This suggests that being selective in which results to combine is vital in building effective ensembles---hence "less is more". In this paper we propose SELECT; an ensemble approach for anomaly mining that employs novel techniques to automatically and systematically select the results to assemble in a fully unsupervised fashion. We apply our method to event detection in temporal graphs, where SELECT successfully utilizes five base detectors and seven consensus methods under a unified ensemble framework. We provide extensive quantitative evaluation of our approach on five real-world datasets (four with ground truth), including Enron email communications, New York Times news corpus, and World Cup 2014 Twitter news feed. Thanks to its selection mechanism, SELECT yields superior performance compared to individual detectors alone, the full ensemble (naively combining all results), and an existing diversity-based ensemble.