 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVidi: Large Multimodal Models for Video Understanding and Editing
Apr 22, 2025



Humans naturally share information with those they are connected to, and video has become one of the dominant mediums for communication and expression on the Internet. To support the creation of high-quality large-scale video content, a modern pipeline requires a comprehensive understanding of both the raw input materials (e.g., the unedited footage captured by cameras) and the editing components (e.g., visual effects). In video editing scenarios, models must process multiple modalities (e.g., vision, audio, text) with strong background knowledge and handle flexible input lengths (e.g., hour-long raw videos), which poses significant challenges for traditional models. In this report, we introduce Vidi, a family of Large Multimodal Models (LMMs) for a wide range of video understand editing scenarios. The first release focuses on temporal retrieval, i.e., identifying the time ranges within the input videos corresponding to a given text query, which plays a critical role in intelligent editing. The model is capable of processing hour-long videos with strong temporal understanding capability, e.g., retrieve time ranges for certain queries. To support a comprehensive evaluation in real-world scenarios, we also present the VUE-TR benchmark, which introduces five key advancements. 1) Video duration: significantly longer than existing temporal retrival datasets, 2) Audio support: includes audio-based queries, 3) Query format: diverse query lengths/formats, 4) Annotation quality: ground-truth time ranges are manually annotated. 5) Evaluation metric: a refined IoU metric to support evaluation over multiple time ranges. Remarkably, Vidi significantly outperforms leading proprietary models, e.g., GPT-4o and Gemini, on the temporal retrieval task, indicating its superiority in video editing scenarios.
Sequential Ensemble Learning for Outlier Detection: A Bias-Variance Perspective
Sep 18, 2016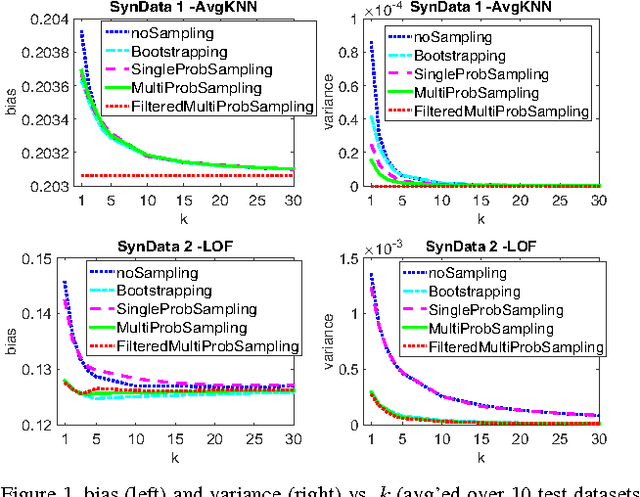


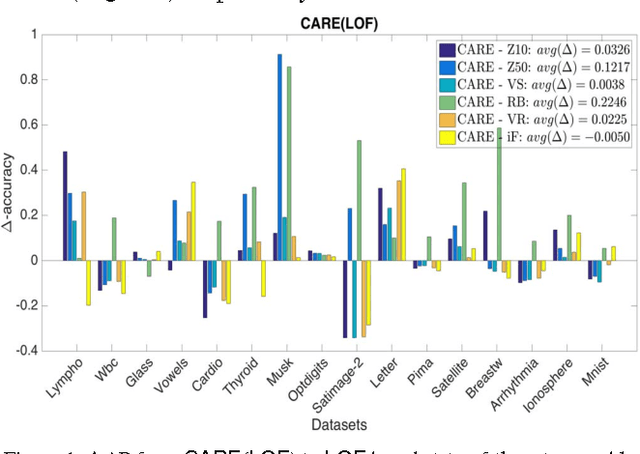
Ensemble methods for classification and clustering have been effectively used for decades, while ensemble learning for outlier detection has only been studied recently. In this work, we design a new ensemble approach for outlier detection in multi-dimensional point data, which provides improved accuracy by reducing error through both bias and variance. Although classification and outlier detection appear as different problems, their theoretical underpinnings are quite similar in terms of the bias-variance trade-off [1], where outlier detection is considered as a binary classification task with unobserved labels but a similar bias-variance decomposition of error. In this paper, we propose a sequential ensemble approach called CARE that employs a two-phase aggregation of the intermediate results in each iteration to reach the final outcome. Unlike existing outlier ensembles which solely incorporate a parallel framework by aggregating the outcomes of independent base detectors to reduce variance, our ensemble incorporates both the parallel and sequential building blocks to reduce bias as well as variance by ($i$) successively eliminating outliers from the original dataset to build a better data model on which outlierness is estimated (sequentially), and ($ii$) combining the results from individual base detectors and across iterations (parallelly). Through extensive experiments on sixteen real-world datasets mainly from the UCI machine learning repository [2], we show that CARE performs significantly better than or at least similar to the individual baselines. We also compare CARE with the state-of-the-art outlier ensembles where it also provides significant improvement when it is the winner and remains close otherwise.