 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterPrompt: Interpretable Prompting for Interrelated Interpersonal Risk Factors in Reddit Posts
Nov 21, 2023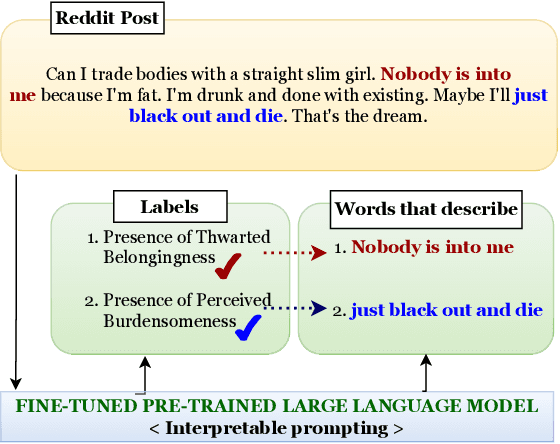

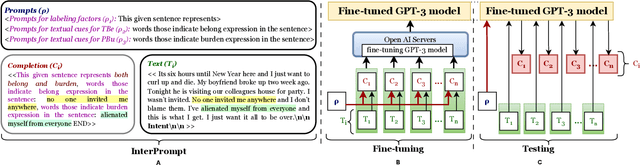

Mental health professionals and clinicians have observed the upsurge of mental disorders due to Interpersonal Risk Factors (IRFs). To simulate the human-in-the-loop triaging scenario for early detection of mental health disorders, we recognized textual indications to ascertain these IRFs : Thwarted Belongingness (TBe) and Perceived Burdensomeness (PBu) within personal narratives. In light of this, we use N-shot learning with GPT-3 model on the IRF dataset, and underscored the importance of fine-tuning GPT-3 model to incorporate the context-specific sensitivity and the interconnectedness of textual cues that represent both IRFs. In this paper, we introduce an Interpretable Prompting (InterPrompt)} method to boost the attention mechanism by fine-tuning the GPT-3 model. This allows a more sophisticated level of language modification by adjusting the pre-trained weights. Our model learns to detect usual patterns and underlying connections across both the IRFs, which leads to better system-level explainability and trustworthiness. The results of our research demonstrate that all four variants of GPT-3 model, when fine-tuned with InterPrompt, perform considerably better as compared to the baseline methods, both in terms of classification and explanation generation.
Leveraging Knowledge and Reinforcement Learning for Enhanced Reliability of Language Models
Aug 25, 2023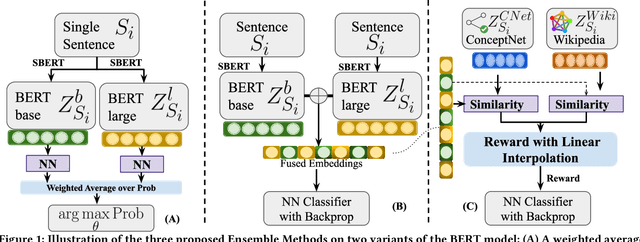
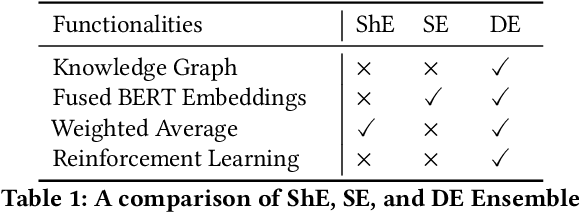
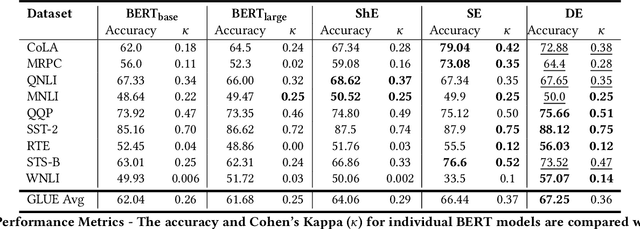
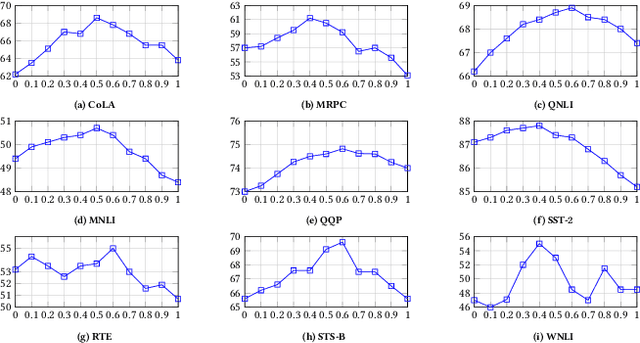
The Natural Language Processing(NLP) community has been using crowd sourcing techniques to create benchmark datasets such as General Language Understanding and Evaluation(GLUE) for training modern Language Models such as BERT. GLUE tasks measure the reliability scores using inter annotator metrics i.e. Cohens Kappa. However, the reliability aspect of LMs has often been overlooked. To counter this problem, we explore a knowledge-guided LM ensembling approach that leverages reinforcement learning to integrate knowledge from ConceptNet and Wikipedia as knowledge graph embeddings. This approach mimics human annotators resorting to external knowledge to compensate for information deficits in the datasets. Across nine GLUE datasets, our research shows that ensembling strengthens reliability and accuracy scores, outperforming state of the art.
Simple is Better and Large is Not Enough: Towards Ensembling of Foundational Language Models
Aug 23, 2023


Foundational Language Models (FLMs) have advanced natural language processing (NLP) research. Current researchers are developing larger FLMs (e.g., XLNet, T5) to enable contextualized language representation, classification, and generation. While developing larger FLMs has been of significant advantage, it is also a liability concerning hallucination and predictive uncertainty. Fundamentally, larger FLMs are built on the same foundations as smaller FLMs (e.g., BERT); hence, one must recognize the potential of smaller FLMs which can be realized through an ensemble. In the current research, we perform a reality check on FLMs and their ensemble on benchmark and real-world datasets. We hypothesize that the ensembling of FLMs can influence the individualistic attention of FLMs and unravel the strength of coordination and cooperation of different FLMs. We utilize BERT and define three other ensemble techniques: {Shallow, Semi, and Deep}, wherein the Deep-Ensemble introduces a knowledge-guided reinforcement learning approach. We discovered that the suggested Deep-Ensemble BERT outperforms its large variation i.e. BERTlarge, by a factor of many times using datasets that show the usefulness of NLP in sensitive fields, such as mental health.
Towards Explainable and Safe Conversational Agents for Mental Health: A Survey
Apr 25, 2023Virtual Mental Health Assistants (VMHAs) are seeing continual advancements to support the overburdened global healthcare system that gets 60 million primary care visits, and 6 million Emergency Room (ER) visits annually. These systems are built by clinical psychologists, psychiatrists, and Artificial Intelligence (AI) researchers for Cognitive Behavioral Therapy (CBT). At present, the role of VMHAs is to provide emotional support through information, focusing less on developing a reflective conversation with the patient. A more comprehensive, safe and explainable approach is required to build responsible VMHAs to ask follow-up questions or provide a well-informed response. This survey offers a systematic critical review of the existing conversational agents in mental health, followed by new insights into the improvements of VMHAs with contextual knowledge, datasets, and their emerging role in clinical decision support. We also provide new directions toward enriching the user experience of VMHAs with explainability, safety, and wholesome trustworthiness. Finally, we provide evaluation metrics and practical considerations for VMHAs beyond the current literature to build trust between VMHAs and patients in active communications.