 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiroThinker-1.7 & H1: Towards Heavy-Duty Research Agents via Verification
Mar 16, 2026We present MiroThinker-1.7, a new research agent designed for complex long-horizon reasoning tasks. Building on this foundation, we further introduce MiroThinker-H1, which extends the agent with heavy-duty reasoning capabilities for more reliable multi-step problem solving. In particular, MiroThinker-1.7 improves the reliability of each interaction step through an agentic mid-training stage that emphasizes structured planning, contextual reasoning, and tool interaction. This enables more effective multi-step interaction and sustained reasoning across complex tasks. MiroThinker-H1 further incorporates verification directly into the reasoning process at both local and global levels. Intermediate reasoning decisions can be evaluated and refined during inference, while the overall reasoning trajectory is audited to ensure that final answers are supported by coherent chains of evidence. Across benchmarks covering open-web research, scientific reasoning, and financial analysis, MiroThinker-H1 achieves state-of-the-art performance on deep research tasks while maintaining strong results on specialized domains. We also release MiroThinker-1.7 and MiroThinker-1.7-mini as open-source models, providing competitive research-agent capabilities with significantly improved efficiency.
Test-time Controllable Image Generation by Explicit Spatial Constraint Enforcement
Jan 02, 2025



Recent text-to-image generation favors various forms of spatial conditions, e.g., masks, bounding boxes, and key points. However, the majority of the prior art requires form-specific annotations to fine-tune the original model, leading to poor test-time generalizability. Meanwhile, existing training-free methods work well only with simplified prompts and spatial conditions. In this work, we propose a novel yet generic test-time controllable generation method that aims at natural text prompts and complex conditions. Specifically, we decouple spatial conditions into semantic and geometric conditions and then enforce their consistency during the image-generation process individually. As for the former, we target bridging the gap between the semantic condition and text prompts, as well as the gap between such condition and the attention map from diffusion models. To achieve this, we propose to first complete the prompt w.r.t. semantic condition, and then remove the negative impact of distracting prompt words by measuring their statistics in attention maps as well as distances in word space w.r.t. this condition. To further cope with the complex geometric conditions, we introduce a geometric transform module, in which Region-of-Interests will be identified in attention maps and further used to translate category-wise latents w.r.t. geometric condition. More importantly, we propose a diffusion-based latents-refill method to explicitly remove the impact of latents at the RoI, reducing the artifacts on generated images. Experiments on Coco-stuff dataset showcase 30$\%$ relative boost compared to SOTA training-free methods on layout consistency evaluation metrics.
Towards Explainable and Safe Conversational Agents for Mental Health: A Survey
Apr 25, 2023Virtual Mental Health Assistants (VMHAs) are seeing continual advancements to support the overburdened global healthcare system that gets 60 million primary care visits, and 6 million Emergency Room (ER) visits annually. These systems are built by clinical psychologists, psychiatrists, and Artificial Intelligence (AI) researchers for Cognitive Behavioral Therapy (CBT). At present, the role of VMHAs is to provide emotional support through information, focusing less on developing a reflective conversation with the patient. A more comprehensive, safe and explainable approach is required to build responsible VMHAs to ask follow-up questions or provide a well-informed response. This survey offers a systematic critical review of the existing conversational agents in mental health, followed by new insights into the improvements of VMHAs with contextual knowledge, datasets, and their emerging role in clinical decision support. We also provide new directions toward enriching the user experience of VMHAs with explainability, safety, and wholesome trustworthiness. Finally, we provide evaluation metrics and practical considerations for VMHAs beyond the current literature to build trust between VMHAs and patients in active communications.
HaloAE: An HaloNet based Local Transformer Auto-Encoder for Anomaly Detection and Localization
Aug 06, 2022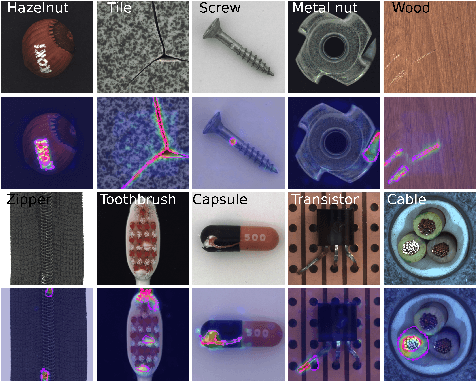

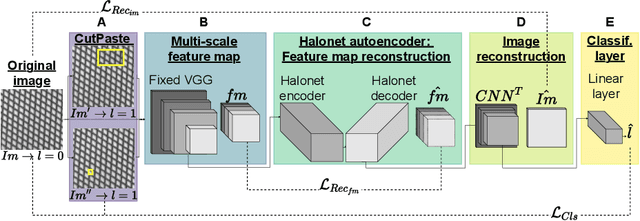

Unsupervised anomaly detection and localization is a crucial task as it is impossible to collect and label all possible anomalies. Many studies have emphasized the importance of integrating local and global information to achieve accurate segmentation of anomalies. To this end, there has been a growing interest in Transformer, which allows modeling long-range content interactions. However, global interactions through self attention are generally too expensive for most image scales. In this study, we introduce HaloAE, the first auto-encoder based on a local 2D version of Transformer with HaloNet. With HaloAE, we have created a hybrid model that combines convolution and local 2D block-wise self-attention layers and jointly performs anomaly detection and segmentation through a single model. We achieved competitive results on the MVTec dataset, suggesting that vision models incorporating Transformer could benefit from a local computation of the self-attention operation, and pave the way for other applications.
Autonomous Driving at Intersections: A Critical-Turning-Point Approach for Left Turns
Mar 05, 2020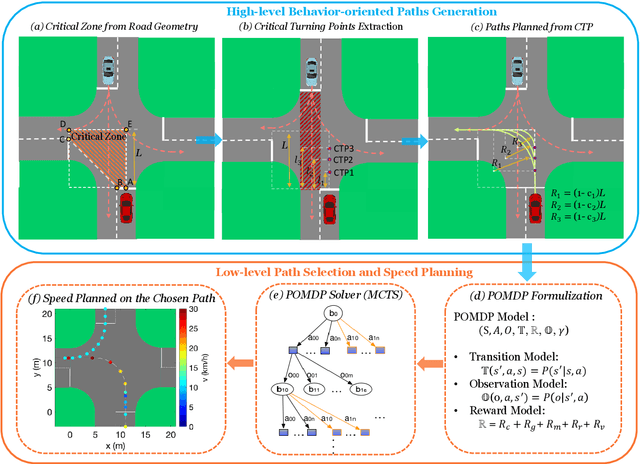
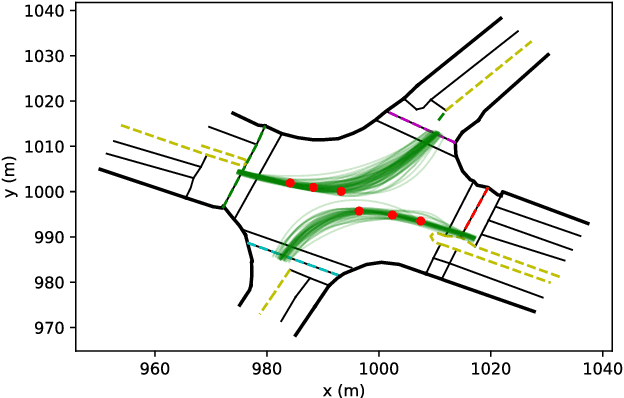
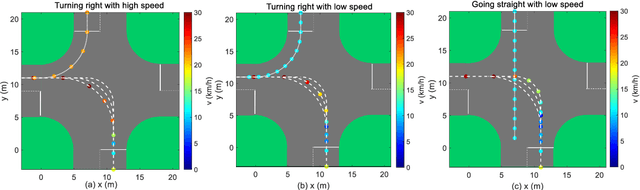
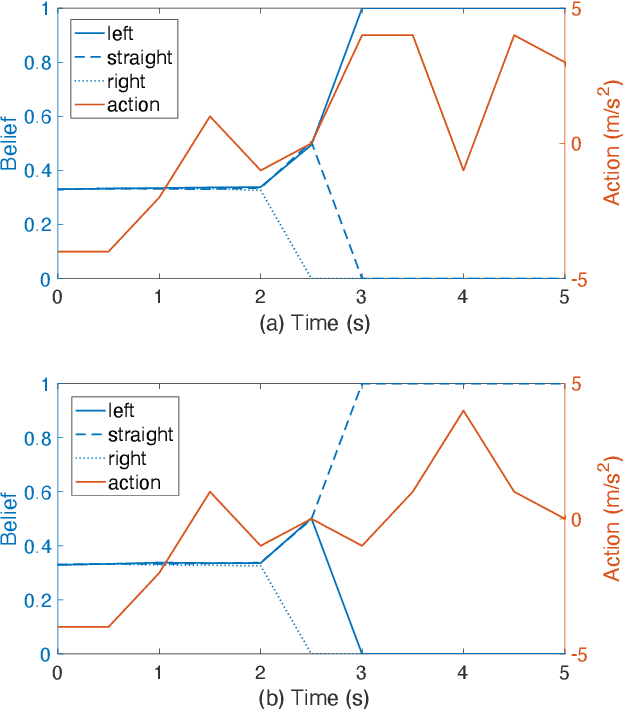
Left-turn planning is one of the formidable challenges for autonomous vehicles, especially at unsignalized intersections due to the unknown intentions of oncoming vehicles. This paper addresses the challenge by proposing a critical turning point (CTP) based hierarchical planning approach. This includes a high-level candidate path generator and a low-level partially observable Markov decision process (POMDP) based planner. The proposed (CTP) concept, inspired by human-driving behaviors at intersections, aims to increase the computational efficiency of the low-level planner and to enable human-friendly autonomous driving. The POMDP based low-level planner takes unknown intentions of oncoming vehicles into considerations to perform less conservative yet safe actions. With proper integration, the proposed hierarchical approach is capable of achieving safe planning results with high commute efficiency at unsignalized intersections in real time.
Vertex nomination schemes for membership prediction
Nov 17, 2015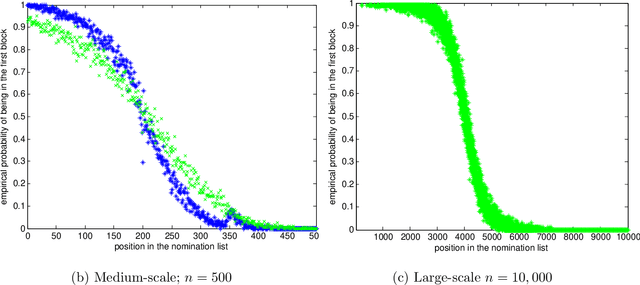

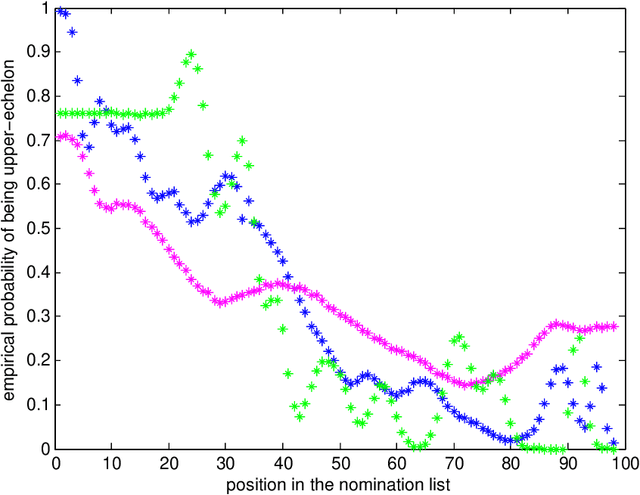

Suppose that a graph is realized from a stochastic block model where one of the blocks is of interest, but many or all of the vertices' block labels are unobserved. The task is to order the vertices with unobserved block labels into a ``nomination list'' such that, with high probability, vertices from the interesting block are concentrated near the list's beginning. We propose several vertex nomination schemes. Our basic - but principled - setting and development yields a best nomination scheme (which is a Bayes-Optimal analogue), and also a likelihood maximization nomination scheme that is practical to implement when there are a thousand vertices, and which is empirically near-optimal when the number of vertices is small enough to allow comparison to the best nomination scheme. We then illustrate the robustness of the likelihood maximization nomination scheme to the modeling challenges inherent in real data, using examples which include a social network involving human trafficking, the Enron Graph, a worm brain connectome and a political blog network.
* Published at http://dx.doi.org/10.1214/15-AOAS834 in the Annals of Applied Statistics (http://www.imstat.org/aoas/) by the Institute of Mathematical Statistics (http://www.imstat.org)