 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaloAE: An HaloNet based Local Transformer Auto-Encoder for Anomaly Detection and Localization
Aug 06, 2022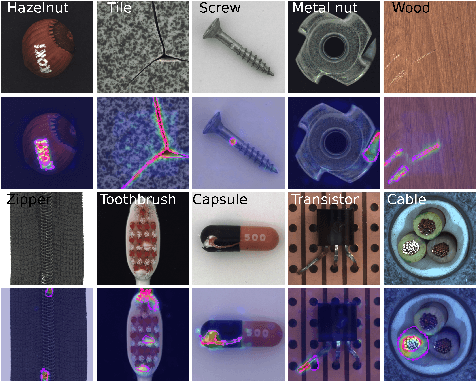

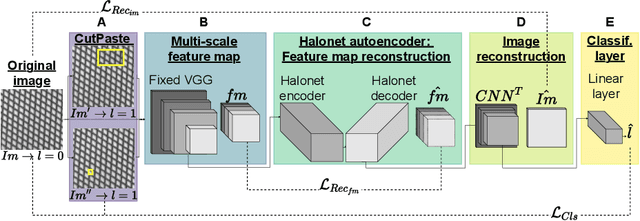

Unsupervised anomaly detection and localization is a crucial task as it is impossible to collect and label all possible anomalies. Many studies have emphasized the importance of integrating local and global information to achieve accurate segmentation of anomalies. To this end, there has been a growing interest in Transformer, which allows modeling long-range content interactions. However, global interactions through self attention are generally too expensive for most image scales. In this study, we introduce HaloAE, the first auto-encoder based on a local 2D version of Transformer with HaloNet. With HaloAE, we have created a hybrid model that combines convolution and local 2D block-wise self-attention layers and jointly performs anomaly detection and segmentation through a single model. We achieved competitive results on the MVTec dataset, suggesting that vision models incorporating Transformer could benefit from a local computation of the self-attention operation, and pave the way for other applications.
Randomized Kaczmarz Method for Single Particle X-ray Image Phase Retrieval
Jul 11, 2022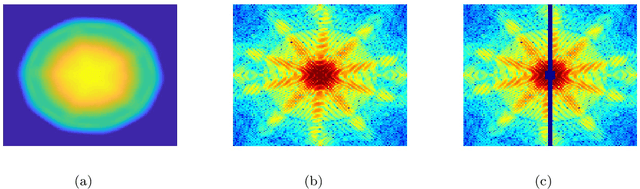

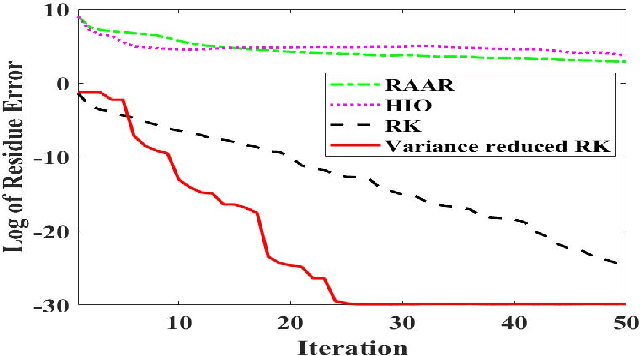
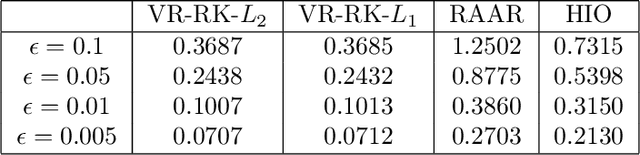
In this paper, we investigate phase retrieval algorithm for the single particle X-ray imaging data. We present a variance-reduced randomized Kaczmarz (VR-RK) algorithm for phase retrieval. The VR-RK algorithm is inspired by the randomized Kaczmarz method and the Stochastic Variance Reduce Gradient Descent (SVRG) algorithm. Numerical experiments show that the VR-RK algorithm has a faster convergence rate than randomized Kaczmarz algorithm and the iterative projection phase retrieval methods, such as the hybrid input output (HIO) and the relaxed averaged alternating reflections (RAAR) methods. The VR-RK algorithm can recover the phases with higher accuracy, and is robust at the presence of noise. Experimental results on the scattering data from individual particles show that the VR-RK algorithm can recover phases and improve the single particle image identification.
Varying Joint Patterns and Compensatory Strategies Can Lead to the Same Functional Gait Outcomes: A Case Study
Jun 27, 2022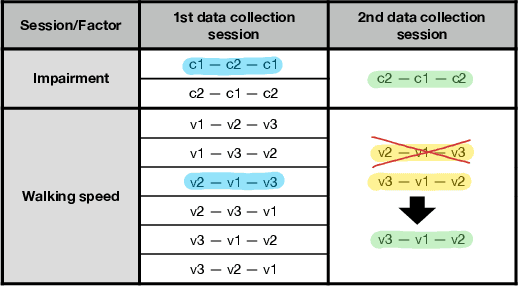
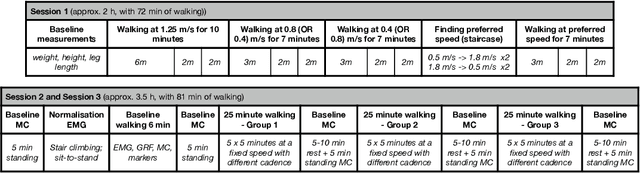
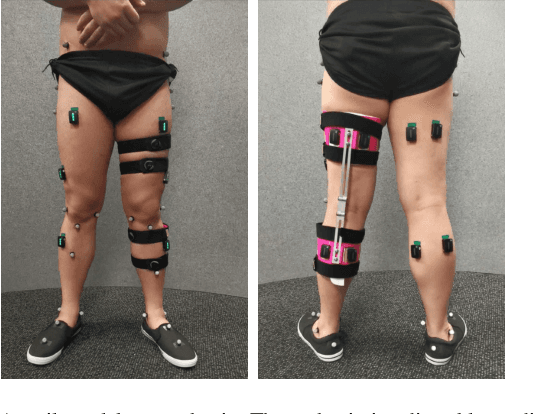
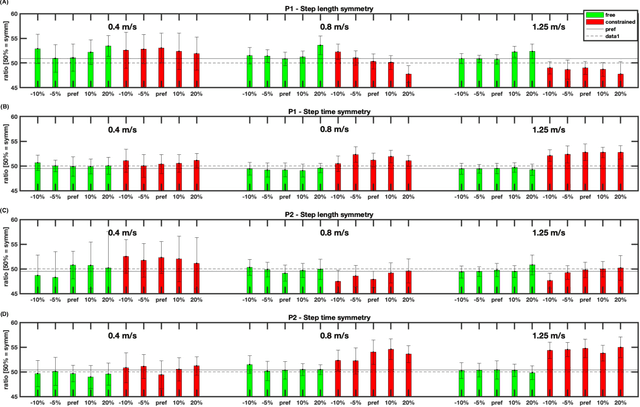
This paper analyses joint-space walking mechanisms and redundancies in delivering functional gait outcomes. Multiple biomechanical measures are analysed for two healthy male adults who participated in a multi-factorial study and walked during three sessions. Both participants employed varying intra- and inter-personal compensatory strategies (e.g., vaulting, hip hiking) across walking conditions and exhibited notable gait pattern alterations while keeping task-space (functional) gait parameters invariant. They also preferred various levels of asymmetric step length but kept their symmetric step time consistent and cadence-invariant during free walking. The results demonstrate the importance of an individualised approach and the need for a paradigm shift from functional (task-space) to joint-space gait analysis in attending to (a)typical gaits and delivering human-centred human-robot interaction.
A Multi-task Two-stream Spatiotemporal Convolutional Neural Network for Convective Storm Nowcasting
Oct 27, 2020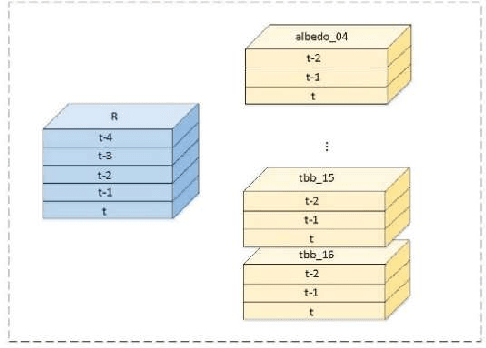
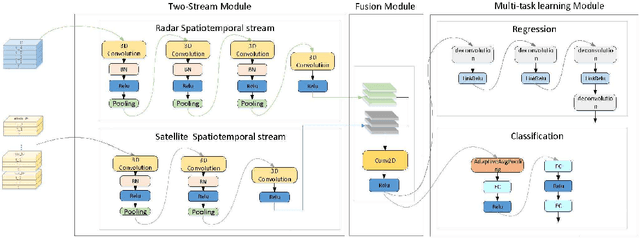
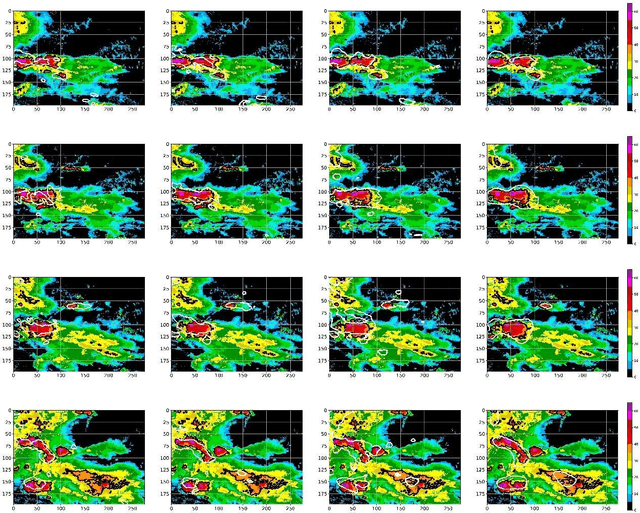
The goal of convective storm nowcasting is local prediction of severe and imminent convective storms. Here, we consider the convective storm nowcasting problem from the perspective of machine learning. First, we use a pixel-wise sampling method to construct spatiotemporal features for nowcasting, and flexibly adjust the proportions of positive and negative samples in the training set to mitigate class-imbalance issues. Second, we employ a concise two-stream convolutional neural network to extract spatial and temporal cues for nowcasting. This simplifies the network structure, reduces the training time requirement, and improves classification accuracy. The two-stream network used both radar and satellite data. In the resulting two-stream, fused convolutional neural network, some of the parameters are entered into a single-stream convolutional neural network, but it can learn the features of many data. Further, considering the relevance of classification and regression tasks, we develop a multi-task learning strategy that predicts the labels used in such tasks. We integrate two-stream multi-task learning into a single convolutional neural network. Given the compact architecture, this network is more efficient and easier to optimize than existing recurrent neural networks.
Multiview Hessian regularized logistic regression for action recognition
Mar 03, 2014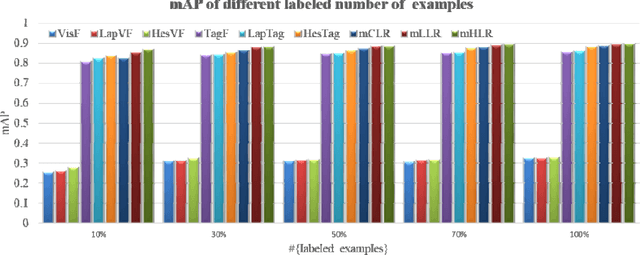
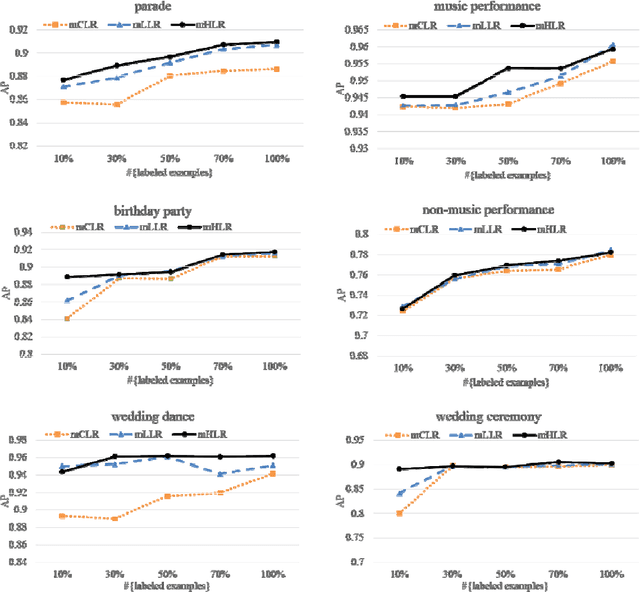
With the rapid development of social media sharing, people often need to manage the growing volume of multimedia data such as large scale video classification and annotation, especially to organize those videos containing human activities. Recently, manifold regularized semi-supervised learning (SSL), which explores the intrinsic data probability distribution and then improves the generalization ability with only a small number of labeled data, has emerged as a promising paradigm for semiautomatic video classification. In addition, human action videos often have multi-modal content and different representations. To tackle the above problems, in this paper we propose multiview Hessian regularized logistic regression (mHLR) for human action recognition. Compared with existing work, the advantages of mHLR lie in three folds: (1) mHLR combines multiple Hessian regularization, each of which obtained from a particular representation of instance, to leverage the exploring of local geometry; (2) mHLR naturally handle multi-view instances with multiple representations; (3) mHLR employs a smooth loss function and then can be effectively optimized. We carefully conduct extensive experiments on the unstructured social activity attribute (USAA) dataset and the experimental results demonstrate the effectiveness of the proposed multiview Hessian regularized logistic regression for human action recognition.
Manifold regularized kernel logistic regression for web image annotation
Dec 21, 2013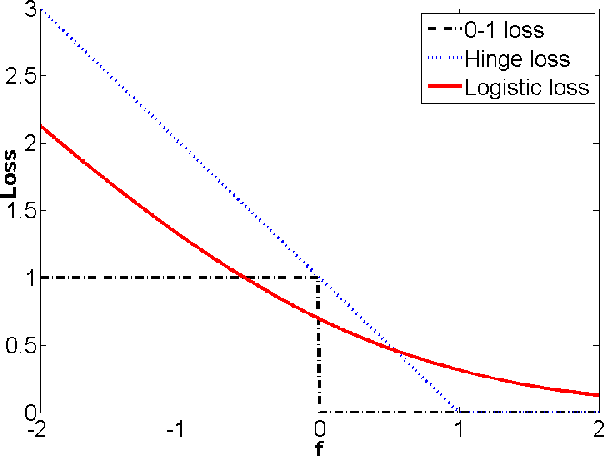

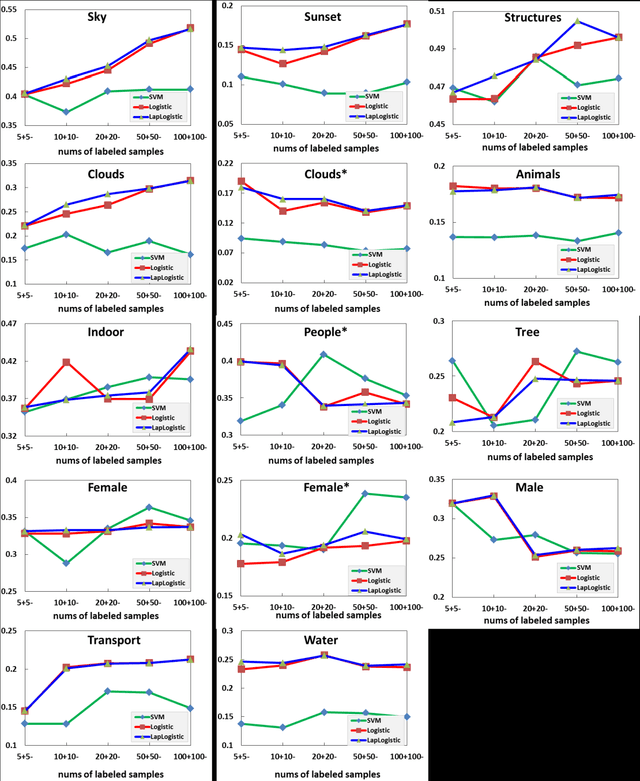
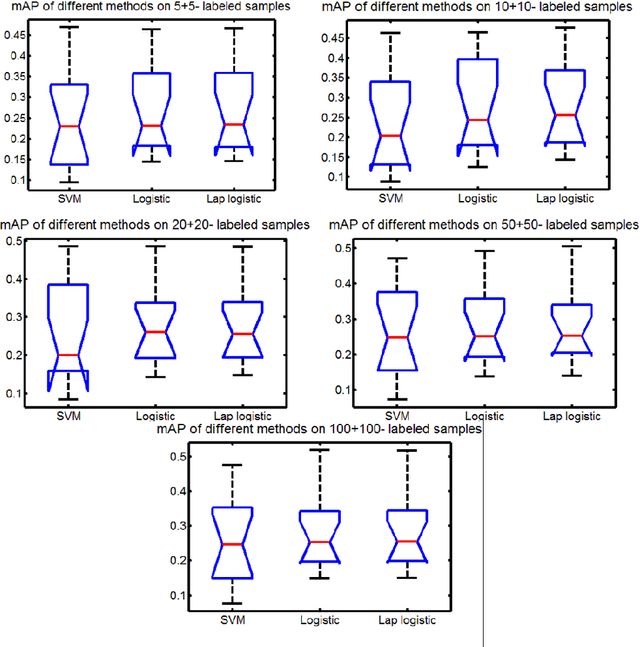
With the rapid advance of Internet technology and smart devices, users often need to manage large amounts of multimedia information using smart devices, such as personal image and video accessing and browsing. These requirements heavily rely on the success of image (video) annotation, and thus large scale image annotation through innovative machine learning methods has attracted intensive attention in recent years. One representative work is support vector machine (SVM). Although it works well in binary classification, SVM has a non-smooth loss function and can not naturally cover multi-class case. In this paper, we propose manifold regularized kernel logistic regression (KLR) for web image annotation. Compared to SVM, KLR has the following advantages: (1) the KLR has a smooth loss function; (2) the KLR produces an explicit estimate of the probability instead of class label; and (3) the KLR can naturally be generalized to the multi-class case. We carefully conduct experiments on MIR FLICKR dataset and demonstrate the effectiveness of manifold regularized kernel logistic regression for image annotation.