 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEuclid Quick Data Release (Q1). AgileLens: A scalable CNN-based pipeline for strong gravitational lens identification
Apr 08, 2026We present an end-to-end, iterative pipeline for efficient identification of strong galaxy--galaxy lensing systems, applied to the Euclid Q1 imaging data. Starting from VIS catalogues, we reject point sources, apply a magnitude cut (I$_E$ $\leq$ 24) on deflectors, and run a pixel-level artefact/noise filter to build 96 $\times$ 96 pix cutouts; VIS+NISP colour composites are constructed with a VIS-anchored luminance scheme that preserves VIS morphology and NISP colour contrast. A VIS-only seed classifier supplies clear positives and typical impostors, from which we curate a morphology-balanced negative set and augment scarce positives. Among the six CNNs studied initially, a modified VGG16 (GlobalAveragePooling + 256/128 dense layers with the last nine layers trainable) performs best; the training set grows from 27 seed lenses (augmented to 1809) plus 2000 negatives to a colour dataset of 30,686 images. After three rounds of iterative fine-tuning, human grading of the top 4000 candidates ranked by the final model yields 441 Grade A/B candidate lensing systems, including 311 overlapping with the existing Q1 strong-lens catalogue, and 130 additional A/B candidates (9 As and 121 Bs) not previously reported. Independently, the model recovers 740 out of 905 (81.8%) candidate Q1 lenses within its top 20,000 predictions, considering off-centred samples. Candidates span I$_E$ $\simeq$ 17--24 AB mag (median 21.3 AB mag) and are redder in Y$_E$--H$_E$ than the parent population, consistent with massive early-type deflectors. Each training iteration required a week for a small team, and the approach easily scales to future Euclid releases; future work will calibrate the selection function via lens injection, extend recall through uncertainty-aware active learning, explore multi-scale or attention-based neural networks with fast post-hoc vetters that incorporate lens models into the classification.
Euclid Quick Data Release (Q1). Active galactic nuclei identification using diffusion-based inpainting of Euclid VIS images
Mar 19, 2025Light emission from galaxies exhibit diverse brightness profiles, influenced by factors such as galaxy type, structural features and interactions with other galaxies. Elliptical galaxies feature more uniform light distributions, while spiral and irregular galaxies have complex, varied light profiles due to their structural heterogeneity and star-forming activity. In addition, galaxies with an active galactic nucleus (AGN) feature intense, concentrated emission from gas accretion around supermassive black holes, superimposed on regular galactic light, while quasi-stellar objects (QSO) are the extreme case of the AGN emission dominating the galaxy. The challenge of identifying AGN and QSO has been discussed many times in the literature, often requiring multi-wavelength observations. This paper introduces a novel approach to identify AGN and QSO from a single image. Diffusion models have been recently developed in the machine-learning literature to generate realistic-looking images of everyday objects. Utilising the spatial resolving power of the Euclid VIS images, we created a diffusion model trained on one million sources, without using any source pre-selection or labels. The model learns to reconstruct light distributions of normal galaxies, since the population is dominated by them. We condition the prediction of the central light distribution by masking the central few pixels of each source and reconstruct the light according to the diffusion model. We further use this prediction to identify sources that deviate from this profile by examining the reconstruction error of the few central pixels regenerated in each source's core. Our approach, solely using VIS imaging, features high completeness compared to traditional methods of AGN and QSO selection, including optical, near-infrared, mid-infrared, and X-rays. [abridged]
Topology-based deep-learning segmentation method for deep anterior lamellar keratoplasty (DALK) surgical guidance using M-mode OCT data
Jan 07, 2025



Deep Anterior Lamellar Keratoplasty (DALK) is a partial-thickness corneal transplant procedure used to treat corneal stromal diseases. A crucial step in this procedure is the precise separation of the deep stroma from Descemet's membrane (DM) using the Big Bubble technique. To simplify the tasks of needle insertion and pneumo-dissection in this technique, we previously developed an Optical Coherence Tomography (OCT)-guided, eye-mountable robot that uses real-time tracking of corneal layers from M-mode OCT signals for control. However, signal noise and instability during manipulation of the OCT fiber sensor-integrated needle have hindered the performance of conventional deep-learning segmentation methods, resulting in rough and inaccurate detection of corneal layers. To address these challenges, we have developed a topology-based deep-learning segmentation method that integrates a topological loss function with a modified network architecture. This approach effectively reduces the effects of noise and improves segmentation speed, precision, and stability. Validation using in vivo, ex vivo, and hybrid rabbit eye datasets demonstrates that our method outperforms traditional loss-based techniques, providing fast, accurate, and robust segmentation of the epithelium and DM to guide surgery.
Reimagining partial thickness keratoplasty: An eye mountable robot for autonomous big bubble needle insertion
Oct 18, 2024Autonomous surgical robots have demonstrated significant potential to standardize surgical outcomes, driving innovations that enhance safety and consistency regardless of individual surgeon experience. Deep anterior lamellar keratoplasty (DALK), a partial thickness corneal transplant surgery aimed at replacing the anterior part of cornea above Descemet membrane (DM), would greatly benefit from an autonomous surgical approach as it highly relies on surgeon skill with high perforation rates. In this study, we proposed a novel autonomous surgical robotic system (AUTO-DALK) based on a customized neural network capable of precise needle control and consistent big bubble demarcation on cadaver and live rabbit models. We demonstrate the feasibility of an AI-based image-guided vertical drilling approach for big bubble generation, in contrast to the conventional horizontal needle approach. Our system integrates an optical coherence tomography (OCT) fiber optic distal sensor into the eye-mountable micro robotic system, which automatically segments OCT M-mode depth signals to identify corneal layers using a custom deep learning algorithm. It enables the robot to autonomously guide the needle to targeted tissue layers via a depth-controlled feedback loop. We compared autonomous needle insertion performance and resulting pneumo-dissection using AUTO-DALK against 1) freehand insertion, 2) OCT sensor guided manual insertion, and 3) teleoperated robotic insertion, reporting significant improvements in insertion depth, pneumo-dissection depth, task completion time, and big bubble formation. Ex vivo and in vivo results indicate that the AI-driven, AUTO-DALK system, is a promising solution to standardize pneumo-dissection outcomes for partial thickness keratoplasty.
The Oscars of AI Theater: A Survey on Role-Playing with Language Models
Jul 16, 2024This survey explores the burgeoning field of role-playing with language models, focusing on their development from early persona-based models to advanced character-driven simulations facilitated by Large Language Models (LLMs). Initially confined to simple persona consistency due to limited model capabilities, role-playing tasks have now expanded to embrace complex character portrayals involving character consistency, behavioral alignment, and overall attractiveness. We provide a comprehensive taxonomy of the critical components in designing these systems, including data, models and alignment, agent architecture and evaluation. This survey not only outlines the current methodologies and challenges, such as managing dynamic personal profiles and achieving high-level persona consistency but also suggests avenues for future research in improving the depth and realism of role-playing applications. The goal is to guide future research by offering a structured overview of current methodologies and identifying potential areas for improvement. Related resources and papers are available at https://github.com/nuochenpku/Awesome-Role-Play-Papers.
Stylizing Sparse-View 3D Scenes with Hierarchical Neural Representation
Apr 08, 2024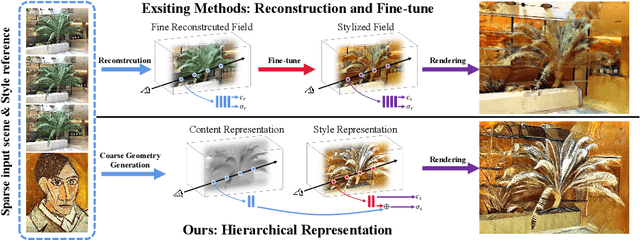
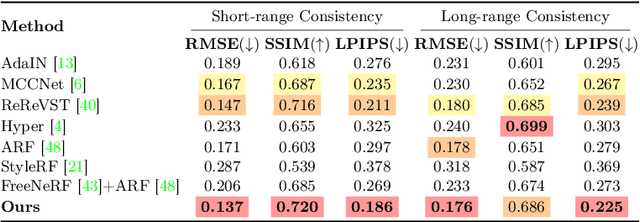
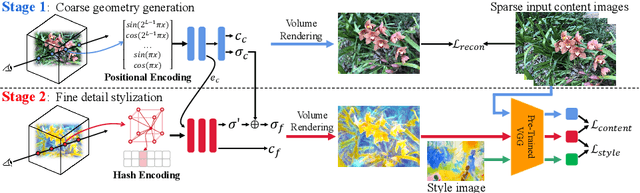

Recently, a surge of 3D style transfer methods has been proposed that leverage the scene reconstruction power of a pre-trained neural radiance field (NeRF). To successfully stylize a scene this way, one must first reconstruct a photo-realistic radiance field from collected images of the scene. However, when only sparse input views are available, pre-trained few-shot NeRFs often suffer from high-frequency artifacts, which are generated as a by-product of high-frequency details for improving reconstruction quality. Is it possible to generate more faithful stylized scenes from sparse inputs by directly optimizing encoding-based scene representation with target style? In this paper, we consider the stylization of sparse-view scenes in terms of disentangling content semantics and style textures. We propose a coarse-to-fine sparse-view scene stylization framework, where a novel hierarchical encoding-based neural representation is designed to generate high-quality stylized scenes directly from implicit scene representations. We also propose a new optimization strategy with content strength annealing to achieve realistic stylization and better content preservation. Extensive experiments demonstrate that our method can achieve high-quality stylization of sparse-view scenes and outperforms fine-tuning-based baselines in terms of stylization quality and efficiency.
Instruction-Driven Game Engines on Large Language Models
Apr 03, 2024The Instruction-Driven Game Engine (IDGE) project aims to democratize game development by enabling a large language model (LLM) to follow free-form game rules and autonomously generate game-play processes. The IDGE allows users to create games by issuing simple natural language instructions, which significantly lowers the barrier for game development. We approach the learning process for IDGEs as a Next State Prediction task, wherein the model autoregressively predicts in-game states given player actions. It is a challenging task because the computation of in-game states must be precise; otherwise, slight errors could disrupt the game-play. To address this, we train the IDGE in a curriculum manner that progressively increases the model's exposure to complex scenarios. Our initial progress lies in developing an IDGE for Poker, a universally cherished card game. The engine we've designed not only supports a wide range of poker variants but also allows for high customization of rules through natural language inputs. Furthermore, it also favors rapid prototyping of new games from minimal samples, proposing an innovative paradigm in game development that relies on minimal prompt and data engineering. This work lays the groundwork for future advancements in instruction-driven game creation, potentially transforming how games are designed and played.
With Greater Text Comes Greater Necessity: Inference-Time Training Helps Long Text Generation
Jan 21, 2024Long text generation, such as novel writing or discourse-level translation with extremely long contexts, presents significant challenges to current language models. Existing methods mainly focus on extending the model's context window through strategies like length extrapolation. However, these approaches demand substantial hardware resources during the training and/or inference phases. Our proposed method, Temp-Lora, introduces an alternative concept. Instead of relying on the KV cache to store all context information, Temp-Lora embeds this information directly into the model's parameters. In the process of long text generation, we use a temporary Lora module, progressively trained with text generated previously. This approach not only efficiently preserves contextual knowledge but also prevents any permanent alteration to the model's parameters given that the module is discarded post-generation. Extensive experiments on the PG19 language modeling benchmark and the GuoFeng discourse-level translation benchmark validate the effectiveness of Temp-Lora. Our results show that: 1) Temp-Lora substantially enhances generation quality for long texts, as indicated by a 13.2% decrease in perplexity on a subset of PG19, and a 29.6% decrease in perplexity along with a 53.2% increase in BLEU score on GuoFeng, 2) Temp-Lora is compatible with and enhances most existing long text generation methods, and 3) Temp-Lora can greatly reduce computational costs by shortening the context window. While ensuring a slight improvement in generation quality (a decrease of 3.8% in PPL), it enables a reduction of 70.5% in the FLOPs required for inference and a 51.5% decrease in latency.
Anisotropic Neural Representation Learning for High-Quality Neural Rendering
Nov 30, 2023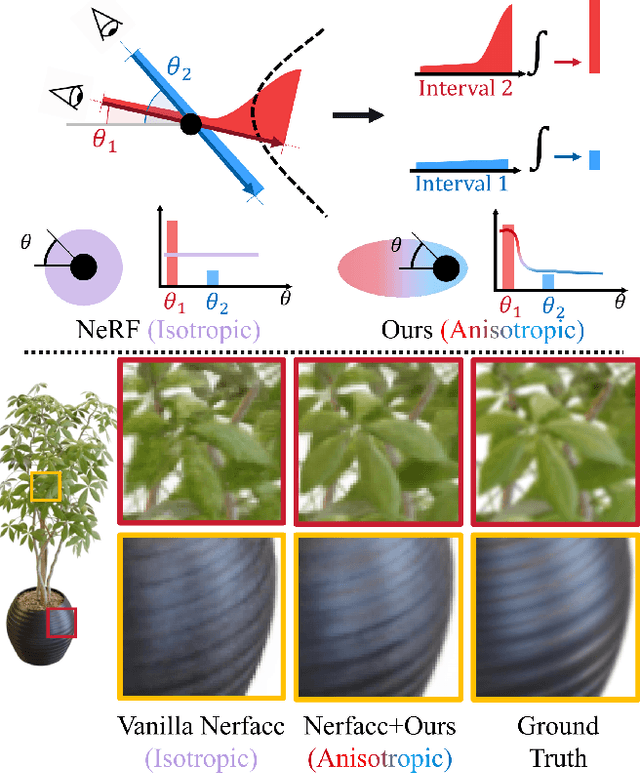
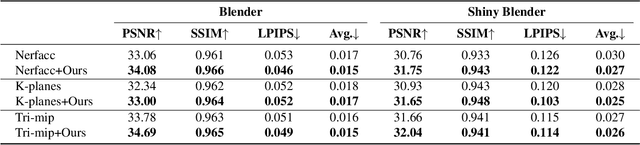
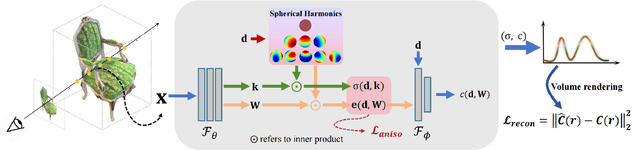
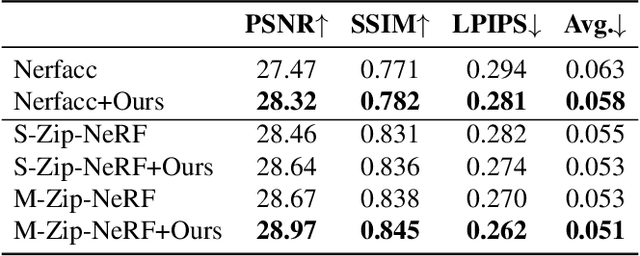
Neural radiance fields (NeRFs) have achieved impressive view synthesis results by learning an implicit volumetric representation from multi-view images. To project the implicit representation into an image, NeRF employs volume rendering that approximates the continuous integrals of rays as an accumulation of the colors and densities of the sampled points. Although this approximation enables efficient rendering, it ignores the direction information in point intervals, resulting in ambiguous features and limited reconstruction quality. In this paper, we propose an anisotropic neural representation learning method that utilizes learnable view-dependent features to improve scene representation and reconstruction. We model the volumetric function as spherical harmonic (SH)-guided anisotropic features, parameterized by multilayer perceptrons, facilitating ambiguity elimination while preserving the rendering efficiency. To achieve robust scene reconstruction without anisotropy overfitting, we regularize the energy of the anisotropic features during training. Our method is flexiable and can be plugged into NeRF-based frameworks. Extensive experiments show that the proposed representation can boost the rendering quality of various NeRFs and achieve state-of-the-art rendering performance on both synthetic and real-world scenes.
Euclid: Identification of asteroid streaks in simulated images using deep learning
Oct 05, 2023Up to 150000 asteroids will be visible in the images of the ESA Euclid space telescope, and the instruments of Euclid offer multiband visual to near-infrared photometry and slitless spectra of these objects. Most asteroids will appear as streaks in the images. Due to the large number of images and asteroids, automated detection methods are needed. A non-machine-learning approach based on the StreakDet software was previously tested, but the results were not optimal for short and/or faint streaks. We set out to improve the capability to detect asteroid streaks in Euclid images by using deep learning. We built, trained, and tested a three-step machine-learning pipeline with simulated Euclid images. First, a convolutional neural network (CNN) detected streaks and their coordinates in full images, aiming to maximize the completeness (recall) of detections. Then, a recurrent neural network (RNN) merged snippets of long streaks detected in several parts by the CNN. Lastly, gradient-boosted trees (XGBoost) linked detected streaks between different Euclid exposures to reduce the number of false positives and improve the purity (precision) of the sample. The deep-learning pipeline surpasses the completeness and reaches a similar level of purity of a non-machine-learning pipeline based on the StreakDet software. Additionally, the deep-learning pipeline can detect asteroids 0.25-0.5 magnitudes fainter than StreakDet. The deep-learning pipeline could result in a 50% increase in the number of detected asteroids compared to the StreakDet software. There is still scope for further refinement, particularly in improving the accuracy of streak coordinates and enhancing the completeness of the final stage of the pipeline, which involves linking detections across multiple exposures.