 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStylizing Sparse-View 3D Scenes with Hierarchical Neural Representation
Apr 08, 2024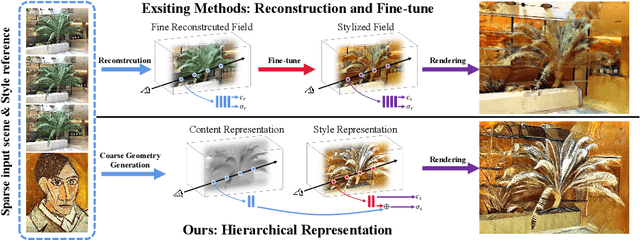
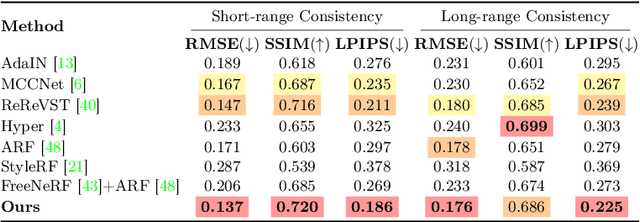
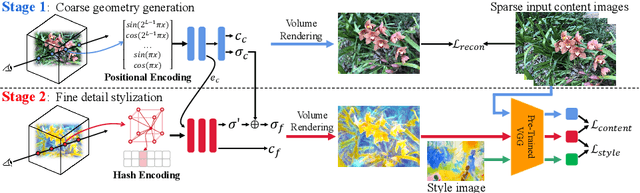

Recently, a surge of 3D style transfer methods has been proposed that leverage the scene reconstruction power of a pre-trained neural radiance field (NeRF). To successfully stylize a scene this way, one must first reconstruct a photo-realistic radiance field from collected images of the scene. However, when only sparse input views are available, pre-trained few-shot NeRFs often suffer from high-frequency artifacts, which are generated as a by-product of high-frequency details for improving reconstruction quality. Is it possible to generate more faithful stylized scenes from sparse inputs by directly optimizing encoding-based scene representation with target style? In this paper, we consider the stylization of sparse-view scenes in terms of disentangling content semantics and style textures. We propose a coarse-to-fine sparse-view scene stylization framework, where a novel hierarchical encoding-based neural representation is designed to generate high-quality stylized scenes directly from implicit scene representations. We also propose a new optimization strategy with content strength annealing to achieve realistic stylization and better content preservation. Extensive experiments demonstrate that our method can achieve high-quality stylization of sparse-view scenes and outperforms fine-tuning-based baselines in terms of stylization quality and efficiency.
Anisotropic Neural Representation Learning for High-Quality Neural Rendering
Nov 30, 2023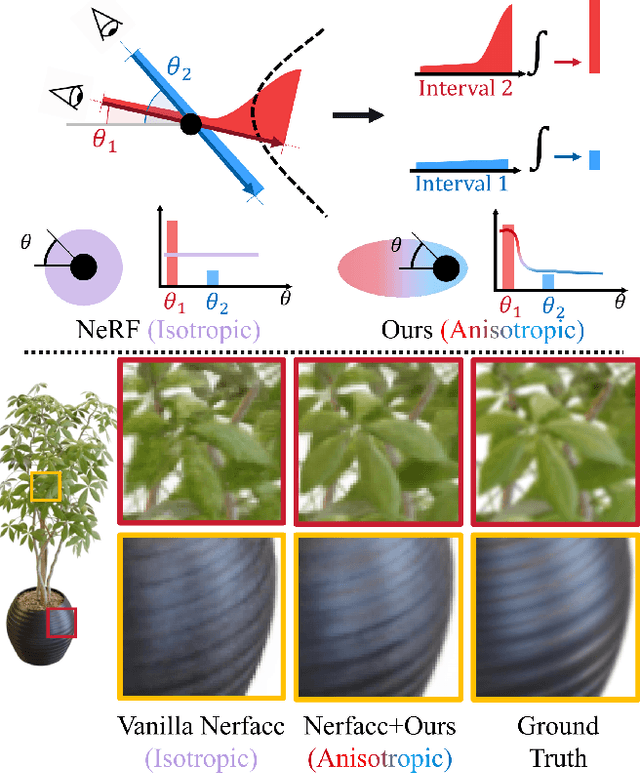
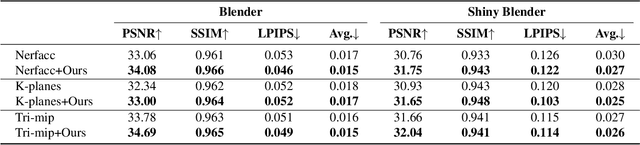
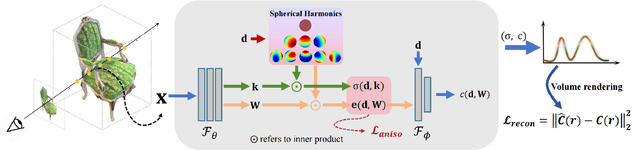
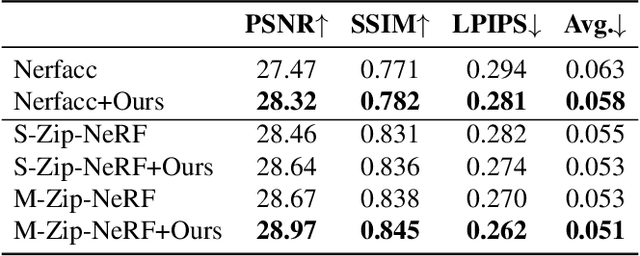
Neural radiance fields (NeRFs) have achieved impressive view synthesis results by learning an implicit volumetric representation from multi-view images. To project the implicit representation into an image, NeRF employs volume rendering that approximates the continuous integrals of rays as an accumulation of the colors and densities of the sampled points. Although this approximation enables efficient rendering, it ignores the direction information in point intervals, resulting in ambiguous features and limited reconstruction quality. In this paper, we propose an anisotropic neural representation learning method that utilizes learnable view-dependent features to improve scene representation and reconstruction. We model the volumetric function as spherical harmonic (SH)-guided anisotropic features, parameterized by multilayer perceptrons, facilitating ambiguity elimination while preserving the rendering efficiency. To achieve robust scene reconstruction without anisotropy overfitting, we regularize the energy of the anisotropic features during training. Our method is flexiable and can be plugged into NeRF-based frameworks. Extensive experiments show that the proposed representation can boost the rendering quality of various NeRFs and achieve state-of-the-art rendering performance on both synthetic and real-world scenes.
REWAFL: Residual Energy and Wireless Aware Participant Selection for Efficient Federated Learning over Mobile Devices
Sep 24, 2023Participant selection (PS) helps to accelerate federated learning (FL) convergence, which is essential for the practical deployment of FL over mobile devices. While most existing PS approaches focus on improving training accuracy and efficiency rather than residual energy of mobile devices, which fundamentally determines whether the selected devices can participate. Meanwhile, the impacts of mobile devices' heterogeneous wireless transmission rates on PS and FL training efficiency are largely ignored. Moreover, PS causes the staleness issue. Prior research exploits isolated functions to force long-neglected devices to participate, which is decoupled from original PS designs. In this paper, we propose a residual energy and wireless aware PS design for efficient FL training over mobile devices (REWAFL). REW AFL introduces a novel PS utility function that jointly considers global FL training utilities and local energy utility, which integrates energy consumption and residual battery energy of candidate mobile devices. Under the proposed PS utility function framework, REW AFL further presents a residual energy and wireless aware local computing policy. Besides, REWAFL buries the staleness solution into its utility function and local computing policy. The experimental results show that REW AFL is effective in improving training accuracy and efficiency, while avoiding "flat battery" of mobile devices.
Multiple Categories Of Visual Smoke Detection Database
Jul 30, 2022

Smoke detection has become a significant task in associated industries due to the close relationship between the petrochemical industry's smoke emission and its safety production and environmental damage. There are several production situations in the real industrial production environment, including complete combustion of exhaust gas, inadequate combustion of exhaust gas, direct emission of exhaust gas, etc. We discovered that the datasets used in previous research work can only determine whether smoke is present or not, not its type. That is, the dataset's category does not map to the real-world production situations, which are not conducive to the precise regulation of the production system. As a result, we created a multi-categories smoke detection database that includes a total of 70196 images. We further employed multiple models to conduct the experiment on the proposed database, the results show that the performance of the current algorithms needs to be improved and demonstrate the effectiveness of the proposed database.