 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnisotropic Neural Representation Learning for High-Quality Neural Rendering
Nov 30, 2023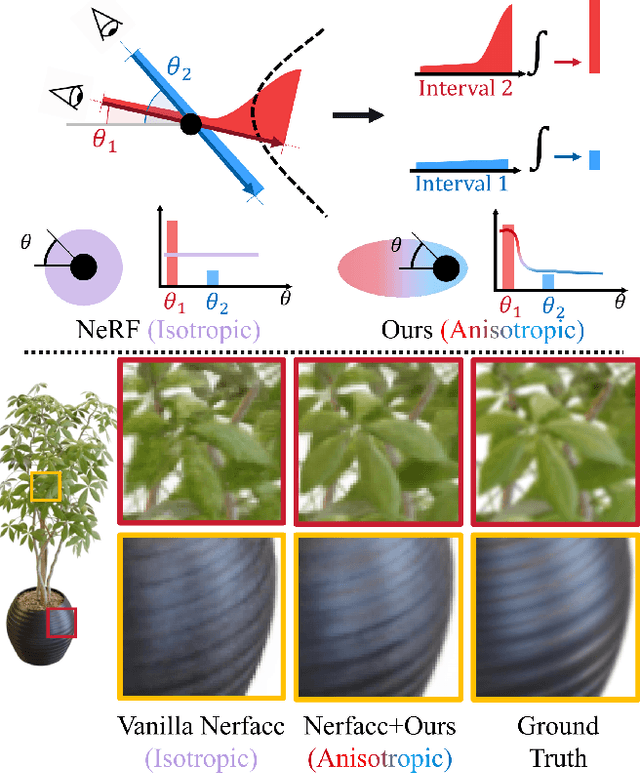
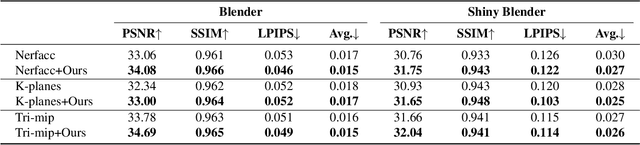
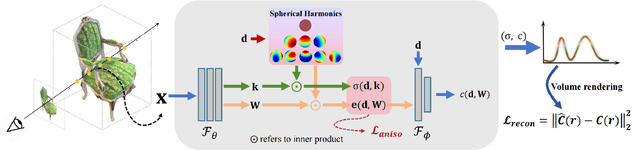
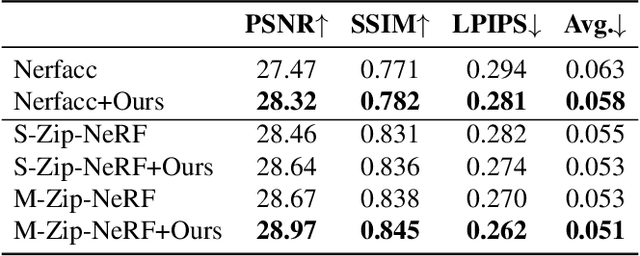
Neural radiance fields (NeRFs) have achieved impressive view synthesis results by learning an implicit volumetric representation from multi-view images. To project the implicit representation into an image, NeRF employs volume rendering that approximates the continuous integrals of rays as an accumulation of the colors and densities of the sampled points. Although this approximation enables efficient rendering, it ignores the direction information in point intervals, resulting in ambiguous features and limited reconstruction quality. In this paper, we propose an anisotropic neural representation learning method that utilizes learnable view-dependent features to improve scene representation and reconstruction. We model the volumetric function as spherical harmonic (SH)-guided anisotropic features, parameterized by multilayer perceptrons, facilitating ambiguity elimination while preserving the rendering efficiency. To achieve robust scene reconstruction without anisotropy overfitting, we regularize the energy of the anisotropic features during training. Our method is flexiable and can be plugged into NeRF-based frameworks. Extensive experiments show that the proposed representation can boost the rendering quality of various NeRFs and achieve state-of-the-art rendering performance on both synthetic and real-world scenes.
Self-Supervised Domain Adaptation with Consistency Training
Oct 15, 2020



We consider the problem of unsupervised domain adaptation for image classification. To learn target-domain-aware features from the unlabeled data, we create a self-supervised pretext task by augmenting the unlabeled data with a certain type of transformation (specifically, image rotation) and ask the learner to predict the properties of the transformation. However, the obtained feature representation may contain a large amount of irrelevant information with respect to the main task. To provide further guidance, we force the feature representation of the augmented data to be consistent with that of the original data. Intuitively, the consistency introduces additional constraints to representation learning, therefore, the learned representation is more likely to focus on the right information about the main task. Our experimental results validate the proposed method and demonstrate state-of-the-art performance on classical domain adaptation benchmarks. Code is available at https://github.com/Jiaolong/ss-da-consistency.