 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSI Feedback with Model-Driven Deep Learning of Massive MIMO Systems
Dec 13, 2021
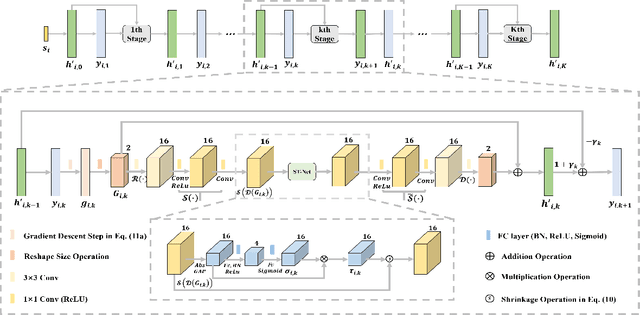
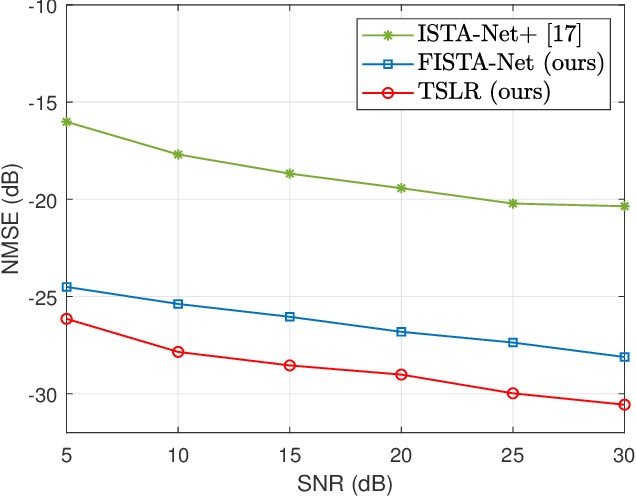

In order to achieve reliable communication with a high data rate of massive multiple-input multiple-output (MIMO) systems in frequency division duplex (FDD) mode, the estimated channel state information (CSI) at the receiver needs to be fed back to the transmitter. However, the feedback overhead becomes exorbitant with the increasing number of antennas. In this paper, a two stages low rank (TSLR) CSI feedback scheme for millimeter wave (mmWave) massive MIMO systems is proposed to reduce the feedback overhead based on model-driven deep learning. Besides, we design a deep iterative neural network, named FISTA-Net, by unfolding the fast iterative shrinkage thresholding algorithm (FISTA) to achieve more efficient CSI feedback. Moreover, a shrinkage thresholding network (ST-Net) is designed in FISTA-Net based on the attention mechanism, which can choose the threshold adaptively. Simulation results show that the proposed TSLR CSI feedback scheme and FISTA-Net outperform the existing algorithms in various scenarios.
AdaGCN:Adaptive Boosting Algorithm for Graph Convolutional Networks on Imbalanced Node Classification
May 25, 2021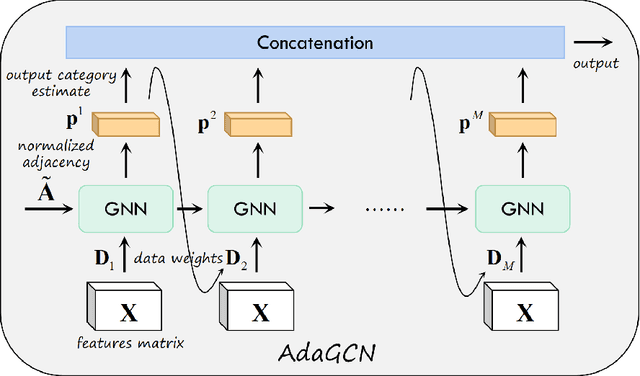
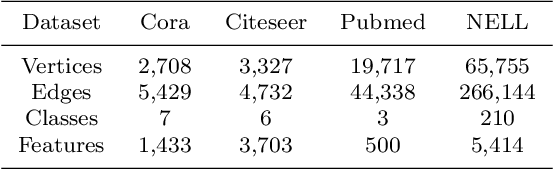
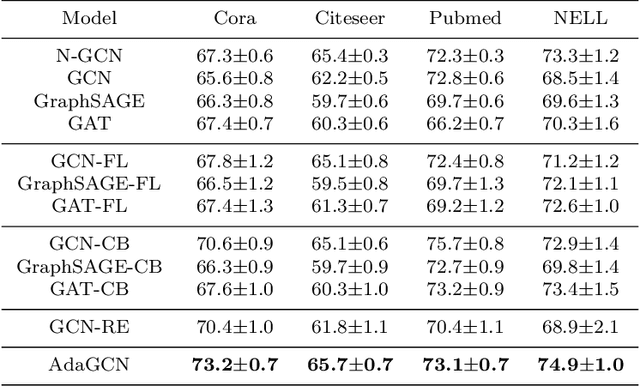
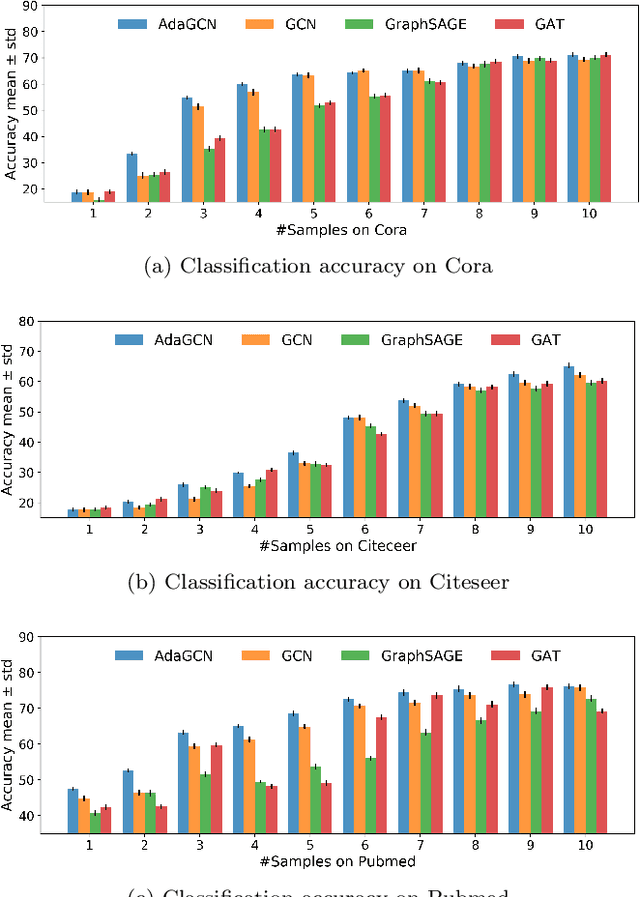
The Graph Neural Network (GNN) has achieved remarkable success in graph data representation. However, the previous work only considered the ideal balanced dataset, and the practical imbalanced dataset was rarely considered, which, on the contrary, is of more significance for the application of GNN. Traditional methods such as resampling, reweighting and synthetic samples that deal with imbalanced datasets are no longer applicable in GNN. Ensemble models can handle imbalanced datasets better compared with single estimator. Besides, ensemble learning can achieve higher estimation accuracy and has better reliability compared with the single estimator. In this paper, we propose an ensemble model called AdaGCN, which uses a Graph Convolutional Network (GCN) as the base estimator during adaptive boosting. In AdaGCN, a higher weight will be set for the training samples that are not properly classified by the previous classifier, and transfer learning is used to reduce computational cost and increase fitting capability. Experiments show that the AdaGCN model we proposed achieves better performance than GCN, GraphSAGE, GAT, N-GCN and the most of advanced reweighting and resampling methods on synthetic imbalanced datasets, with an average improvement of 4.3%. Our model also improves state-of-the-art baselines on all of the challenging node classification tasks we consider: Cora, Citeseer, Pubmed, and NELL.
Self-Supervised Domain Adaptation with Consistency Training
Oct 15, 2020



We consider the problem of unsupervised domain adaptation for image classification. To learn target-domain-aware features from the unlabeled data, we create a self-supervised pretext task by augmenting the unlabeled data with a certain type of transformation (specifically, image rotation) and ask the learner to predict the properties of the transformation. However, the obtained feature representation may contain a large amount of irrelevant information with respect to the main task. To provide further guidance, we force the feature representation of the augmented data to be consistent with that of the original data. Intuitively, the consistency introduces additional constraints to representation learning, therefore, the learned representation is more likely to focus on the right information about the main task. Our experimental results validate the proposed method and demonstrate state-of-the-art performance on classical domain adaptation benchmarks. Code is available at https://github.com/Jiaolong/ss-da-consistency.
Angular Learning: Toward Discriminative Embedded Features
Dec 17, 2019



The margin-based softmax loss functions greatly enhance intra-class compactness and perform well on the tasks of face recognition and object classification. Outperformance, however, depends on the careful hyperparameter selection. Moreover, the hard angle restriction also increases the risk of overfitting. In this paper, angular loss suggested by maximizing the angular gradient to promote intra-class compactness avoids overfitting. Besides, our method has only one adjustable constant for intra-class compactness control. We define three metrics to measure inter-class separability and intra-class compactness. In experiments, we test our method, as well as other methods, on many well-known datasets. Experimental results reveal that our method has the superiority of accuracy improvement, discriminative information, and time-consumption.
Proceedings of the third "international Traveling Workshop on Interactions between Sparse models and Technology"
Sep 14, 2016
The third edition of the "international - Traveling Workshop on Interactions between Sparse models and Technology" (iTWIST) took place in Aalborg, the 4th largest city in Denmark situated beautifully in the northern part of the country, from the 24th to 26th of August 2016. The workshop venue was at the Aalborg University campus. One implicit objective of this biennial workshop is to foster collaboration between international scientific teams by disseminating ideas through both specific oral/poster presentations and free discussions. For this third edition, iTWIST'16 gathered about 50 international participants and features 8 invited talks, 12 oral presentations, and 12 posters on the following themes, all related to the theory, application and generalization of the "sparsity paradigm": Sparsity-driven data sensing and processing (e.g., optics, computer vision, genomics, biomedical, digital communication, channel estimation, astronomy); Application of sparse models in non-convex/non-linear inverse problems (e.g., phase retrieval, blind deconvolution, self calibration); Approximate probabilistic inference for sparse problems; Sparse machine learning and inference; "Blind" inverse problems and dictionary learning; Optimization for sparse modelling; Information theory, geometry and randomness; Sparsity? What's next? (Discrete-valued signals; Union of low-dimensional spaces, Cosparsity, mixed/group norm, model-based, low-complexity models, ...); Matrix/manifold sensing/processing (graph, low-rank approximation, ...); Complexity/accuracy tradeoffs in numerical methods/optimization; Electronic/optical compressive sensors (hardware).