 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep-Unfolding Neural-Network Aided Hybrid Beamforming Based on Symbol-Error Probability Minimization
Sep 14, 2021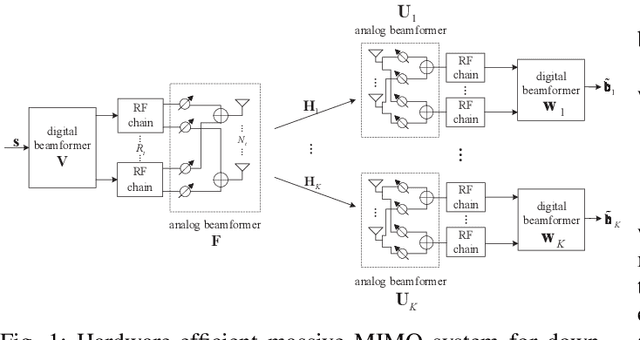
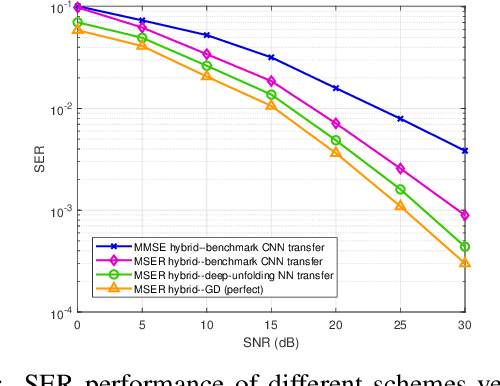
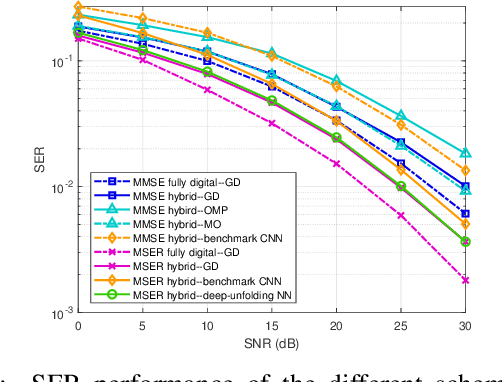
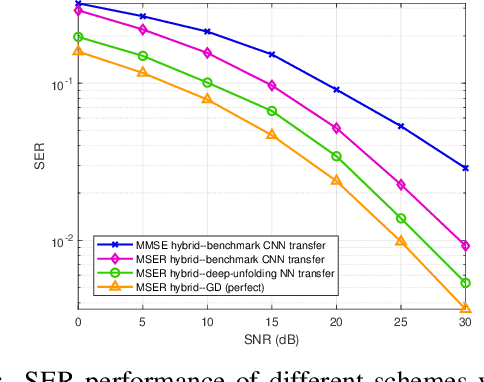
In massive multiple-input multiple-output (MIMO) systems, hybrid analog-digital (AD) beamforming can be used to attain a high directional gain without requiring a dedicated radio frequency (RF) chain for each antenna element, which substantially reduces both the hardware costs and power consumption. While massive MIMO transceiver design typically relies on the conventional mean-square error (MSE) criterion, directly minimizing the symbol error rate (SER) can lead to a superior performance. In this paper, we first mathematically formulate the problem of hybrid transceiver design under the minimum SER (MSER) optimization criterion and then develop a MSER-based gradient descent (GD) iterative algorithm to find the related stationary points. We then propose a deep-unfolding neural network (NN), in which the iterative GD algorithm is unfolded into a multi-layer structure wherein a set of trainable parameters are introduced for accelerating the convergence and enhancing the overall system performance. To implement the training stage, the relationship between the gradients of adjacent layers is derived based on the generalized chain rule (GCR). The deep-unfolding NN is developed for both quadrature phase shift keying (QPSK) and for $M$-ary quadrature amplitude modulated (QAM) signals and its convergence is investigated theoretically. Furthermore, we analyze the transfer capability, computational complexity, and generalization capability of the proposed deep-unfolding NN. Our simulation results show that the latter significantly outperforms its conventional counterpart at a reduced complexity.
AdaGCN:Adaptive Boosting Algorithm for Graph Convolutional Networks on Imbalanced Node Classification
May 25, 2021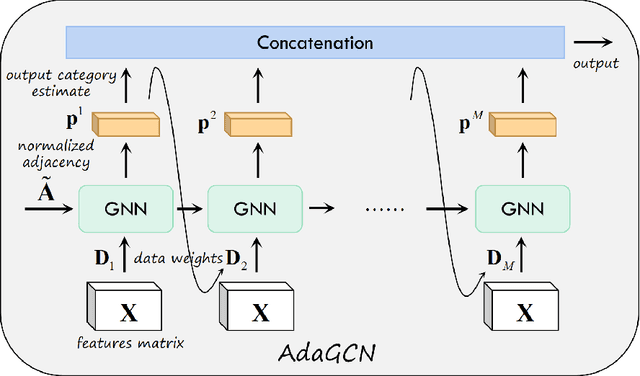
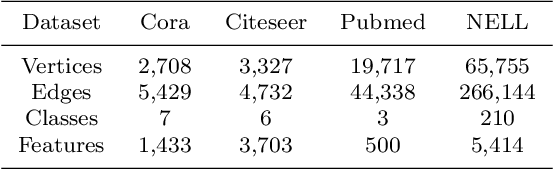
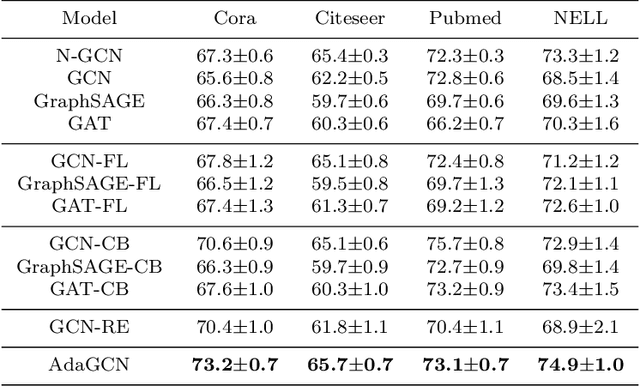
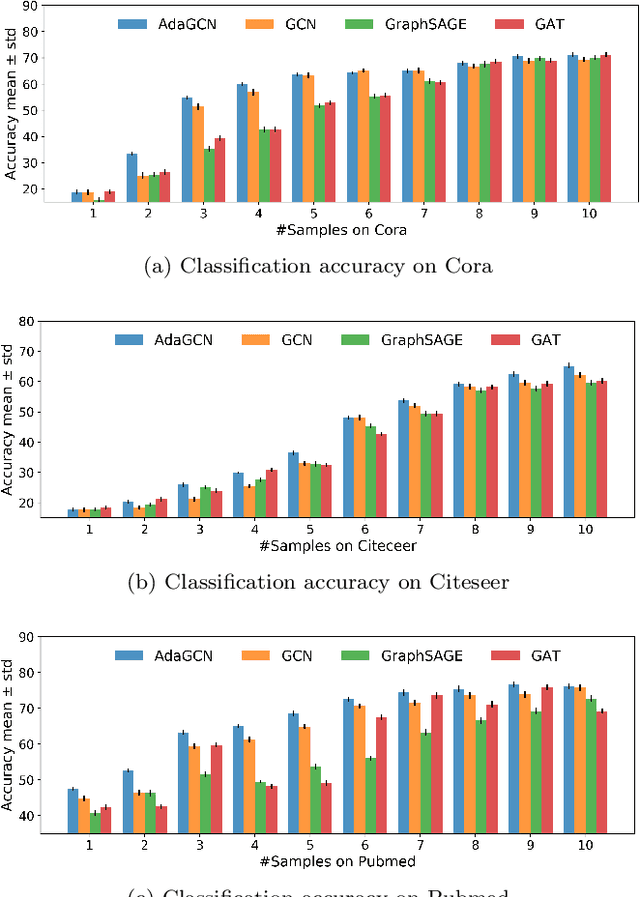
The Graph Neural Network (GNN) has achieved remarkable success in graph data representation. However, the previous work only considered the ideal balanced dataset, and the practical imbalanced dataset was rarely considered, which, on the contrary, is of more significance for the application of GNN. Traditional methods such as resampling, reweighting and synthetic samples that deal with imbalanced datasets are no longer applicable in GNN. Ensemble models can handle imbalanced datasets better compared with single estimator. Besides, ensemble learning can achieve higher estimation accuracy and has better reliability compared with the single estimator. In this paper, we propose an ensemble model called AdaGCN, which uses a Graph Convolutional Network (GCN) as the base estimator during adaptive boosting. In AdaGCN, a higher weight will be set for the training samples that are not properly classified by the previous classifier, and transfer learning is used to reduce computational cost and increase fitting capability. Experiments show that the AdaGCN model we proposed achieves better performance than GCN, GraphSAGE, GAT, N-GCN and the most of advanced reweighting and resampling methods on synthetic imbalanced datasets, with an average improvement of 4.3%. Our model also improves state-of-the-art baselines on all of the challenging node classification tasks we consider: Cora, Citeseer, Pubmed, and NELL.