 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupled Hierarchical Distillation for Multimodal Emotion Recognition
Feb 04, 2026Human multimodal emotion recognition (MER) seeks to infer human emotions by integrating information from language, visual, and acoustic modalities. Although existing MER approaches have achieved promising results, they still struggle with inherent multimodal heterogeneities and varying contributions from different modalities. To address these challenges, we propose a novel framework, Decoupled Hierarchical Multimodal Distillation (DHMD). DHMD decouples each modality's features into modality-irrelevant (homogeneous) and modality-exclusive (heterogeneous) components using a self-regression mechanism. The framework employs a two-stage knowledge distillation (KD) strategy: (1) coarse-grained KD via a Graph Distillation Unit (GD-Unit) in each decoupled feature space, where a dynamic graph facilitates adaptive distillation among modalities, and (2) fine-grained KD through a cross-modal dictionary matching mechanism, which aligns semantic granularities across modalities to produce more discriminative MER representations. This hierarchical distillation approach enables flexible knowledge transfer and effectively improves cross-modal feature alignment. Experimental results demonstrate that DHMD consistently outperforms state-of-the-art MER methods, achieving 1.3\%/2.4\% (ACC$_7$), 1.3\%/1.9\% (ACC$_2$) and 1.9\%/1.8\% (F1) relative improvement on CMU-MOSI/CMU-MOSEI dataset, respectively. Meanwhile, visualization results reveal that both the graph edges and dictionary activations in DHMD exhibit meaningful distribution patterns across modality-irrelevant/-exclusive feature spaces.
* arXiv admin note: text overlap with arXiv:2303.13802
Enhancing Black-Litterman Portfolio via Hybrid Forecasting Model Combining Multivariate Decomposition and Noise Reduction
May 03, 2025The sensitivity to input parameters and lack of flexibility limits the traditional Mean-Variance model. In contrast, the Black-Litterman model has attracted widespread attention by integrating market equilibrium returns with investors' subjective views. This paper proposes a novel hybrid deep learning model combining Singular Spectrum analysis (SSA), Multivariate Aligned Empirical Mode Decomposition (MA-EMD), and Temporal Convolutional Networks (TCNs), aiming to improve the prediction accuracy of asset prices and thus enhance the ability of the Black-Litterman model to generate subjective views. Experimental results show that noise reduction pre-processing can improve the model's accuracy, and the prediction performance of the proposed model is significantly better than that of three multivariate decomposition benchmark models. We construct an investment portfolio by using 20 representative stocks from the NASDAQ 100 index. By combining the hybrid forecasting model with the Black-Litterman model, the generated investment portfolio exhibits better returns and risk control capabilities than the Mean-Variance, Equal-Weighted, and Market-Weighted models in the short holding period.
MambaDETR: Query-based Temporal Modeling using State Space Model for Multi-View 3D Object Detection
Nov 20, 2024



Utilizing temporal information to improve the performance of 3D detection has made great progress recently in the field of autonomous driving. Traditional transformer-based temporal fusion methods suffer from quadratic computational cost and information decay as the length of the frame sequence increases. In this paper, we propose a novel method called MambaDETR, whose main idea is to implement temporal fusion in the efficient state space. Moreover, we design a Motion Elimination module to remove the relatively static objects for temporal fusion. On the standard nuScenes benchmark, our proposed MambaDETR achieves remarkable result in the 3D object detection task, exhibiting state-of-the-art performance among existing temporal fusion methods.
MVLLaVA: An Intelligent Agent for Unified and Flexible Novel View Synthesis
Sep 11, 2024



This paper introduces MVLLaVA, an intelligent agent designed for novel view synthesis tasks. MVLLaVA integrates multiple multi-view diffusion models with a large multimodal model, LLaVA, enabling it to handle a wide range of tasks efficiently. MVLLaVA represents a versatile and unified platform that adapts to diverse input types, including a single image, a descriptive caption, or a specific change in viewing azimuth, guided by language instructions for viewpoint generation. We carefully craft task-specific instruction templates, which are subsequently used to fine-tune LLaVA. As a result, MVLLaVA acquires the capability to generate novel view images based on user instructions, demonstrating its flexibility across diverse tasks. Experiments are conducted to validate the effectiveness of MVLLaVA, demonstrating its robust performance and versatility in tackling diverse novel view synthesis challenges.
ExpLLM: Towards Chain of Thought for Facial Expression Recognition
Sep 04, 2024



Facial expression recognition (FER) is a critical task in multimedia with significant implications across various domains. However, analyzing the causes of facial expressions is essential for accurately recognizing them. Current approaches, such as those based on facial action units (AUs), typically provide AU names and intensities but lack insight into the interactions and relationships between AUs and the overall expression. In this paper, we propose a novel method called ExpLLM, which leverages large language models to generate an accurate chain of thought (CoT) for facial expression recognition. Specifically, we have designed the CoT mechanism from three key perspectives: key observations, overall emotional interpretation, and conclusion. The key observations describe the AU's name, intensity, and associated emotions. The overall emotional interpretation provides an analysis based on multiple AUs and their interactions, identifying the dominant emotions and their relationships. Finally, the conclusion presents the final expression label derived from the preceding analysis. Furthermore, we also introduce the Exp-CoT Engine, designed to construct this expression CoT and generate instruction-description data for training our ExpLLM. Extensive experiments on the RAF-DB and AffectNet datasets demonstrate that ExpLLM outperforms current state-of-the-art FER methods. ExpLLM also surpasses the latest GPT-4o in expression CoT generation, particularly in recognizing micro-expressions where GPT-4o frequently fails.
SciQAG: A Framework for Auto-Generated Scientific Question Answering Dataset with Fine-grained Evaluation
May 16, 2024
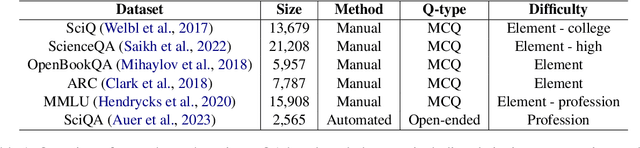


The use of question-answer (QA) pairs for training and evaluating large language models (LLMs) has attracted considerable attention. Yet few available QA datasets are based on knowledge from the scientific literature. Here we bridge this gap by presenting Automatic Generation of Scientific Question Answers (SciQAG), a framework for automatic generation and evaluation of scientific QA pairs sourced from published scientific literature. We fine-tune an open-source LLM to generate \num{960000} scientific QA pairs from full-text scientific papers and propose a five-dimensional metric to evaluate the quality of the generated QA pairs. We show via LLM-based evaluation that the generated QA pairs consistently achieve an average score of 2.5 out of 3 across five dimensions, indicating that our framework can distill key knowledge from papers into high-quality QA pairs at scale. We make the dataset, models, and evaluation codes publicly available.
Split to Merge: Unifying Separated Modalities for Unsupervised Domain Adaptation
Mar 11, 2024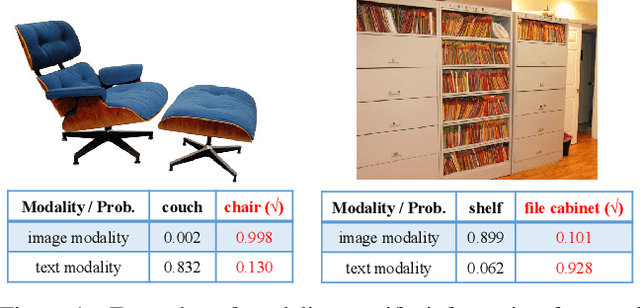
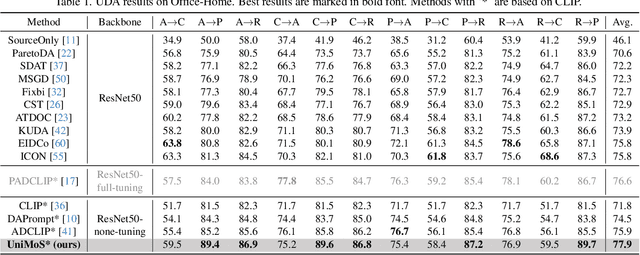
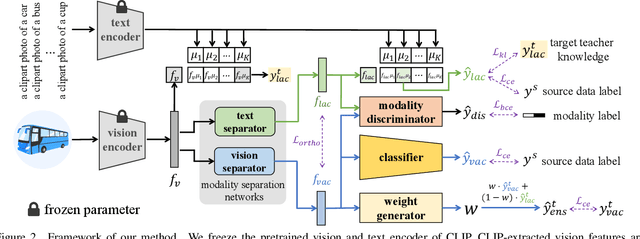
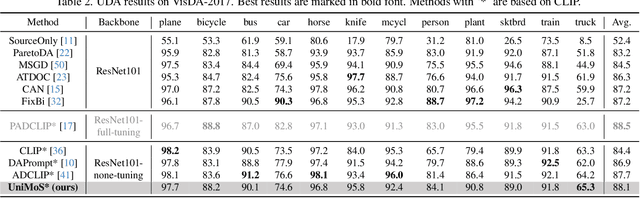
Large vision-language models (VLMs) like CLIP have demonstrated good zero-shot learning performance in the unsupervised domain adaptation task. Yet, most transfer approaches for VLMs focus on either the language or visual branches, overlooking the nuanced interplay between both modalities. In this work, we introduce a Unified Modality Separation (UniMoS) framework for unsupervised domain adaptation. Leveraging insights from modality gap studies, we craft a nimble modality separation network that distinctly disentangles CLIP's features into language-associated and vision-associated components. Our proposed Modality-Ensemble Training (MET) method fosters the exchange of modality-agnostic information while maintaining modality-specific nuances. We align features across domains using a modality discriminator. Comprehensive evaluations on three benchmarks reveal our approach sets a new state-of-the-art with minimal computational costs. Code: https://github.com/TL-UESTC/UniMoS
Agile Multi-Source-Free Domain Adaptation
Mar 08, 2024



Efficiently utilizing rich knowledge in pretrained models has become a critical topic in the era of large models. This work focuses on adaptively utilizing knowledge from multiple source-pretrained models to an unlabeled target domain without accessing the source data. Despite being a practically useful setting, existing methods require extensive parameter tuning over each source model, which is computationally expensive when facing abundant source domains or larger source models. To address this challenge, we propose a novel approach which is free of the parameter tuning over source backbones. Our technical contribution lies in the Bi-level ATtention ENsemble (Bi-ATEN) module, which learns both intra-domain weights and inter-domain ensemble weights to achieve a fine balance between instance specificity and domain consistency. By slightly tuning source bottlenecks, we achieve comparable or even superior performance on a challenging benchmark DomainNet with less than 3% trained parameters and 8 times of throughput compared with SOTA method. Furthermore, with minor modifications, the proposed module can be easily equipped to existing methods and gain more than 4% performance boost. Code is available at https://github.com/TL-UESTC/Bi-ATEN.
Domain-Agnostic Mutual Prompting for Unsupervised Domain Adaptation
Mar 05, 2024Conventional Unsupervised Domain Adaptation (UDA) strives to minimize distribution discrepancy between domains, which neglects to harness rich semantics from data and struggles to handle complex domain shifts. A promising technique is to leverage the knowledge of large-scale pre-trained vision-language models for more guided adaptation. Despite some endeavors, current methods often learn textual prompts to embed domain semantics for source and target domains separately and perform classification within each domain, limiting cross-domain knowledge transfer. Moreover, prompting only the language branch lacks flexibility to adapt both modalities dynamically. To bridge this gap, we propose Domain-Agnostic Mutual Prompting (DAMP) to exploit domain-invariant semantics by mutually aligning visual and textual embeddings. Specifically, the image contextual information is utilized to prompt the language branch in a domain-agnostic and instance-conditioned way. Meanwhile, visual prompts are imposed based on the domain-agnostic textual prompt to elicit domain-invariant visual embeddings. These two branches of prompts are learned mutually with a cross-attention module and regularized with a semantic-consistency loss and an instance-discrimination contrastive loss. Experiments on three UDA benchmarks demonstrate the superiority of DAMP over state-of-the-art approaches.
Neighborhood Contrastive Transformer for Change Captioning
Mar 06, 2023



Change captioning is to describe the semantic change between a pair of similar images in natural language. It is more challenging than general image captioning, because it requires capturing fine-grained change information while being immune to irrelevant viewpoint changes, and solving syntax ambiguity in change descriptions. In this paper, we propose a neighborhood contrastive transformer to improve the model's perceiving ability for various changes under different scenes and cognition ability for complex syntax structure. Concretely, we first design a neighboring feature aggregating to integrate neighboring context into each feature, which helps quickly locate the inconspicuous changes under the guidance of conspicuous referents. Then, we devise a common feature distilling to compare two images at neighborhood level and extract common properties from each image, so as to learn effective contrastive information between them. Finally, we introduce the explicit dependencies between words to calibrate the transformer decoder, which helps better understand complex syntax structure during training. Extensive experimental results demonstrate that the proposed method achieves the state-of-the-art performance on three public datasets with different change scenarios. The code is available at https://github.com/tuyunbin/NCT.