 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified modality separation: A vision-language framework for unsupervised domain adaptation
Aug 07, 2025



Unsupervised domain adaptation (UDA) enables models trained on a labeled source domain to handle new unlabeled domains. Recently, pre-trained vision-language models (VLMs) have demonstrated promising zero-shot performance by leveraging semantic information to facilitate target tasks. By aligning vision and text embeddings, VLMs have shown notable success in bridging domain gaps. However, inherent differences naturally exist between modalities, which is known as modality gap. Our findings reveal that direct UDA with the presence of modality gap only transfers modality-invariant knowledge, leading to suboptimal target performance. To address this limitation, we propose a unified modality separation framework that accommodates both modality-specific and modality-invariant components. During training, different modality components are disentangled from VLM features then handled separately in a unified manner. At test time, modality-adaptive ensemble weights are automatically determined to maximize the synergy of different components. To evaluate instance-level modality characteristics, we design a modality discrepancy metric to categorize samples into modality-invariant, modality-specific, and uncertain ones. The modality-invariant samples are exploited to facilitate cross-modal alignment, while uncertain ones are annotated to enhance model capabilities. Building upon prompt tuning techniques, our methods achieve up to 9% performance gain with 9 times of computational efficiencies. Extensive experiments and analysis across various backbones, baselines, datasets and adaptation settings demonstrate the efficacy of our design.
Split to Merge: Unifying Separated Modalities for Unsupervised Domain Adaptation
Mar 11, 2024
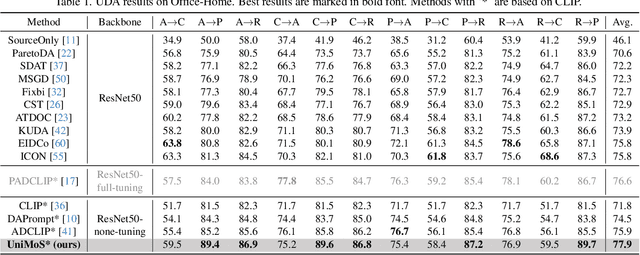
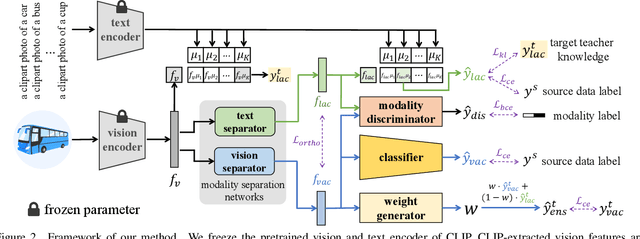
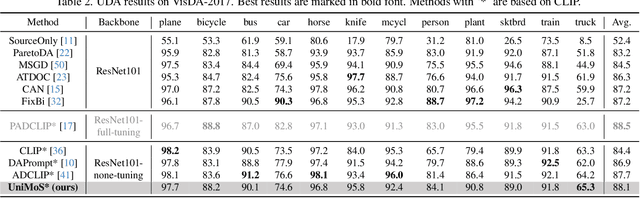
Large vision-language models (VLMs) like CLIP have demonstrated good zero-shot learning performance in the unsupervised domain adaptation task. Yet, most transfer approaches for VLMs focus on either the language or visual branches, overlooking the nuanced interplay between both modalities. In this work, we introduce a Unified Modality Separation (UniMoS) framework for unsupervised domain adaptation. Leveraging insights from modality gap studies, we craft a nimble modality separation network that distinctly disentangles CLIP's features into language-associated and vision-associated components. Our proposed Modality-Ensemble Training (MET) method fosters the exchange of modality-agnostic information while maintaining modality-specific nuances. We align features across domains using a modality discriminator. Comprehensive evaluations on three benchmarks reveal our approach sets a new state-of-the-art with minimal computational costs. Code: https://github.com/TL-UESTC/UniMoS
Domain-Agnostic Mutual Prompting for Unsupervised Domain Adaptation
Mar 05, 2024Conventional Unsupervised Domain Adaptation (UDA) strives to minimize distribution discrepancy between domains, which neglects to harness rich semantics from data and struggles to handle complex domain shifts. A promising technique is to leverage the knowledge of large-scale pre-trained vision-language models for more guided adaptation. Despite some endeavors, current methods often learn textual prompts to embed domain semantics for source and target domains separately and perform classification within each domain, limiting cross-domain knowledge transfer. Moreover, prompting only the language branch lacks flexibility to adapt both modalities dynamically. To bridge this gap, we propose Domain-Agnostic Mutual Prompting (DAMP) to exploit domain-invariant semantics by mutually aligning visual and textual embeddings. Specifically, the image contextual information is utilized to prompt the language branch in a domain-agnostic and instance-conditioned way. Meanwhile, visual prompts are imposed based on the domain-agnostic textual prompt to elicit domain-invariant visual embeddings. These two branches of prompts are learned mutually with a cross-attention module and regularized with a semantic-consistency loss and an instance-discrimination contrastive loss. Experiments on three UDA benchmarks demonstrate the superiority of DAMP over state-of-the-art approaches.
Imbalanced Open Set Domain Adaptation via Moving-threshold Estimation and Gradual Alignment
Mar 09, 2023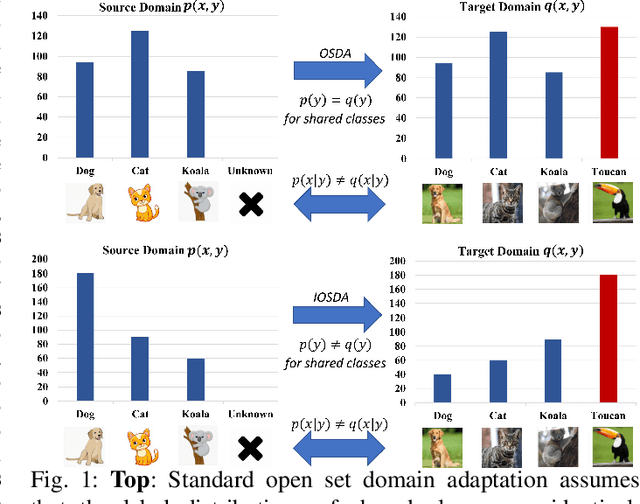
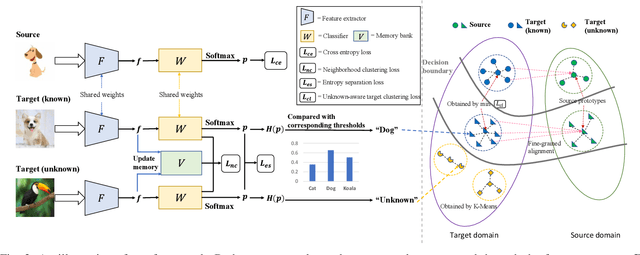
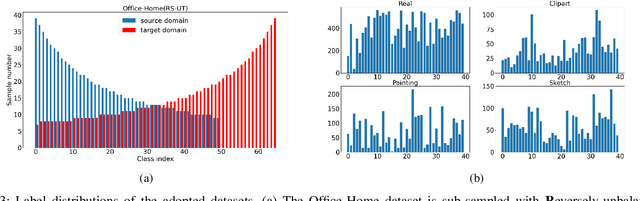
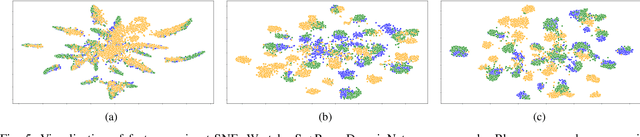
Multimedia applications are often associated with cross-domain knowledge transfer, where Unsupervised Domain Adaptation (UDA) can be used to reduce the domain shifts. Open Set Domain Adaptation (OSDA) aims to transfer knowledge from a well-labeled source domain to an unlabeled target domain under the assumption that the target domain contains unknown classes. Existing OSDA methods consistently lay stress on the covariate shift, ignoring the potential label shift problem. The performance of OSDA methods degrades drastically under intra-domain class imbalance and inter-domain label shift. However, little attention has been paid to this issue in the community. In this paper, the Imbalanced Open Set Domain Adaptation (IOSDA) is explored where the covariate shift, label shift and category mismatch exist simultaneously. To alleviate the negative effects raised by label shift in OSDA, we propose Open-set Moving-threshold Estimation and Gradual Alignment (OMEGA) - a novel architecture that improves existing OSDA methods on class-imbalanced data. Specifically, a novel unknown-aware target clustering scheme is proposed to form tight clusters in the target domain to reduce the negative effects of label shift and intra-domain class imbalance. Furthermore, moving-threshold estimation is designed to generate specific thresholds for each target sample rather than using one for all. Extensive experiments on IOSDA, OSDA and OPDA benchmarks demonstrate that our method could significantly outperform existing state-of-the-arts. Code and data are available at https://github.com/mendicant04/OMEGA.
A Comprehensive Survey on Source-free Domain Adaptation
Feb 23, 2023



Over the past decade, domain adaptation has become a widely studied branch of transfer learning that aims to improve performance on target domains by leveraging knowledge from the source domain. Conventional domain adaptation methods often assume access to both source and target domain data simultaneously, which may not be feasible in real-world scenarios due to privacy and confidentiality concerns. As a result, the research of Source-Free Domain Adaptation (SFDA) has drawn growing attention in recent years, which only utilizes the source-trained model and unlabeled target data to adapt to the target domain. Despite the rapid explosion of SFDA work, yet there has no timely and comprehensive survey in the field. To fill this gap, we provide a comprehensive survey of recent advances in SFDA and organize them into a unified categorization scheme based on the framework of transfer learning. Instead of presenting each approach independently, we modularize several components of each method to more clearly illustrate their relationships and mechanics in light of the composite properties of each method. Furthermore, we compare the results of more than 30 representative SFDA methods on three popular classification benchmarks, namely Office-31, Office-home, and VisDA, to explore the effectiveness of various technical routes and the combination effects among them. Additionally, we briefly introduce the applications of SFDA and related fields. Drawing from our analysis of the challenges facing SFDA, we offer some insights into future research directions and potential settings.
Adversarial Energy Disaggregation for Non-intrusive Load Monitoring
Aug 02, 2021
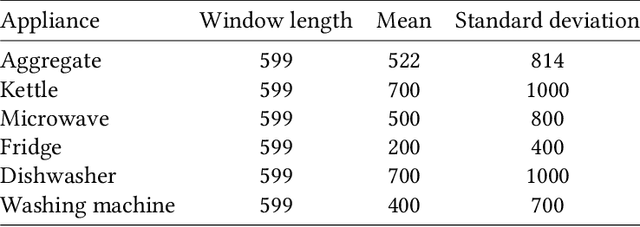
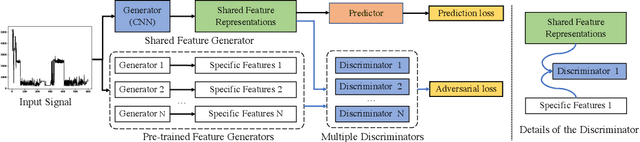
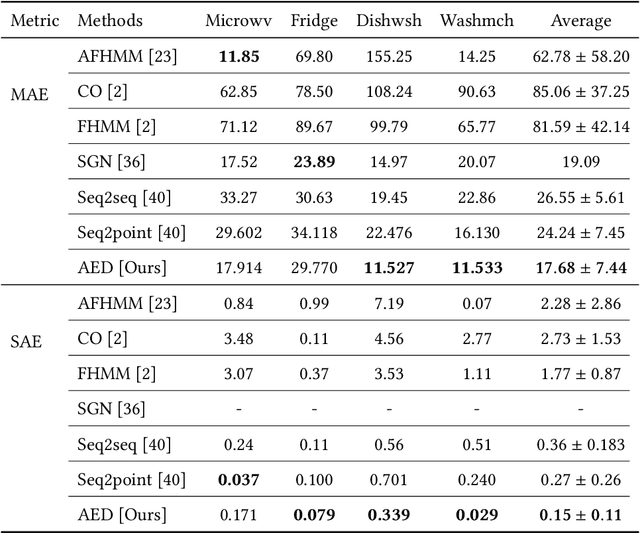
Energy disaggregation, also known as non-intrusive load monitoring (NILM), challenges the problem of separating the whole-home electricity usage into appliance-specific individual consumptions, which is a typical application of data analysis. {NILM aims to help households understand how the energy is used and consequently tell them how to effectively manage the energy, thus allowing energy efficiency which is considered as one of the twin pillars of sustainable energy policy (i.e., energy efficiency and renewable energy).} Although NILM is unidentifiable, it is widely believed that the NILM problem can be addressed by data science. Most of the existing approaches address the energy disaggregation problem by conventional techniques such as sparse coding, non-negative matrix factorization, and hidden Markov model. Recent advances reveal that deep neural networks (DNNs) can get favorable performance for NILM since DNNs can inherently learn the discriminative signatures of the different appliances. In this paper, we propose a novel method named adversarial energy disaggregation (AED) based on DNNs. We introduce the idea of adversarial learning into NILM, which is new for the energy disaggregation task. Our method trains a generator and multiple discriminators via an adversarial fashion. The proposed method not only learns shard representations for different appliances, but captures the specific multimode structures of each appliance. Extensive experiments on real-world datasets verify that our method can achieve new state-of-the-art performance.
Cross-Domain Gradient Discrepancy Minimization for Unsupervised Domain Adaptation
Jun 08, 2021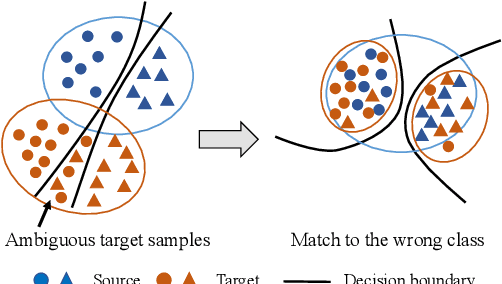
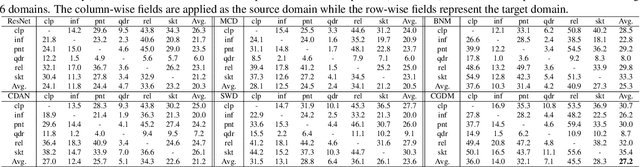
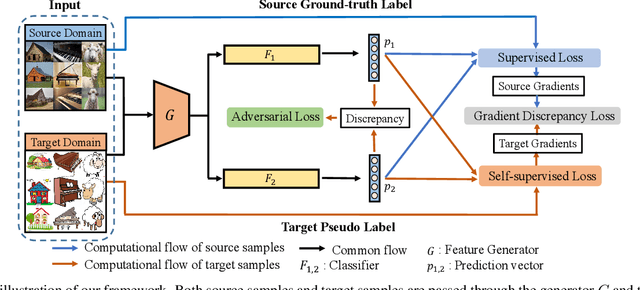
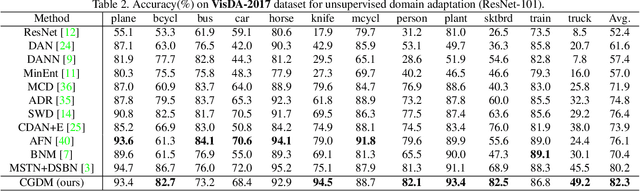
Unsupervised Domain Adaptation (UDA) aims to generalize the knowledge learned from a well-labeled source domain to an unlabeled target domain. Recently, adversarial domain adaptation with two distinct classifiers (bi-classifier) has been introduced into UDA which is effective to align distributions between different domains. Previous bi-classifier adversarial learning methods only focus on the similarity between the outputs of two distinct classifiers. However, the similarity of the outputs cannot guarantee the accuracy of target samples, i.e., target samples may match to wrong categories even if the discrepancy between two classifiers is small. To challenge this issue, in this paper, we propose a cross-domain gradient discrepancy minimization (CGDM) method which explicitly minimizes the discrepancy of gradients generated by source samples and target samples. Specifically, the gradient gives a cue for the semantic information of target samples so it can be used as a good supervision to improve the accuracy of target samples. In order to compute the gradient signal of target samples, we further obtain target pseudo labels through a clustering-based self-supervised learning. Extensive experiments on three widely used UDA datasets show that our method surpasses many previous state-of-the-arts. Codes are available at https://github.com/lijin118/CGDM.