 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning and Interpreting Gravitational-Wave Features from CNNs with a Random Forest Approach
May 26, 2025Convolutional neural networks (CNNs) have become widely adopted in gravitational wave (GW) detection pipelines due to their ability to automatically learn hierarchical features from raw strain data. However, the physical meaning of these learned features remains underexplored, limiting the interpretability of such models. In this work, we propose a hybrid architecture that combines a CNN-based feature extractor with a random forest (RF) classifier to improve both detection performance and interpretability. Unlike prior approaches that directly connect classifiers to CNN outputs, our method introduces four physically interpretable metrics - variance, signal-to-noise ratio (SNR), waveform overlap, and peak amplitude - computed from the final convolutional layer. These are jointly used with the CNN output in the RF classifier to enable more informed decision boundaries. Tested on long-duration strain datasets, our hybrid model outperforms a baseline CNN model, achieving a relative improvement of 21\% in sensitivity at a fixed false alarm rate of 10 events per month. Notably, it also shows improved detection of low-SNR signals (SNR $\le$ 10), which are especially vulnerable to misclassification in noisy environments. Feature attribution via the RF model reveals that both CNN-extracted and handcrafted features contribute significantly to classification decisions, with learned variance and CNN outputs ranked among the most informative. These findings suggest that physically motivated post-processing of CNN feature maps can serve as a valuable tool for interpretable and efficient GW detection, bridging the gap between deep learning and domain knowledge.
Yi-Lightning Technical Report
Dec 03, 2024



This technical report presents Yi-Lightning, our latest flagship large language model (LLM). It achieves exceptional performance, ranking 6th overall on Chatbot Arena, with particularly strong results (2nd to 4th place) in specialized categories including Chinese, Math, Coding, and Hard Prompts. Yi-Lightning leverages an enhanced Mixture-of-Experts (MoE) architecture, featuring advanced expert segmentation and routing mechanisms coupled with optimized KV-caching techniques. Our development process encompasses comprehensive pre-training, supervised fine-tuning (SFT), and reinforcement learning from human feedback (RLHF), where we devise deliberate strategies for multi-stage training, synthetic data construction, and reward modeling. Furthermore, we implement RAISE (Responsible AI Safety Engine), a four-component framework to address safety issues across pre-training, post-training, and serving phases. Empowered by our scalable super-computing infrastructure, all these innovations substantially reduce training, deployment and inference costs while maintaining high-performance standards. With further evaluations on public academic benchmarks, Yi-Lightning demonstrates competitive performance against top-tier LLMs, while we observe a notable disparity between traditional, static benchmark results and real-world, dynamic human preferences. This observation prompts a critical reassessment of conventional benchmarks' utility in guiding the development of more intelligent and powerful AI systems for practical applications. Yi-Lightning is now available through our developer platform at https://platform.lingyiwanwu.com.
Imbalanced Open Set Domain Adaptation via Moving-threshold Estimation and Gradual Alignment
Mar 09, 2023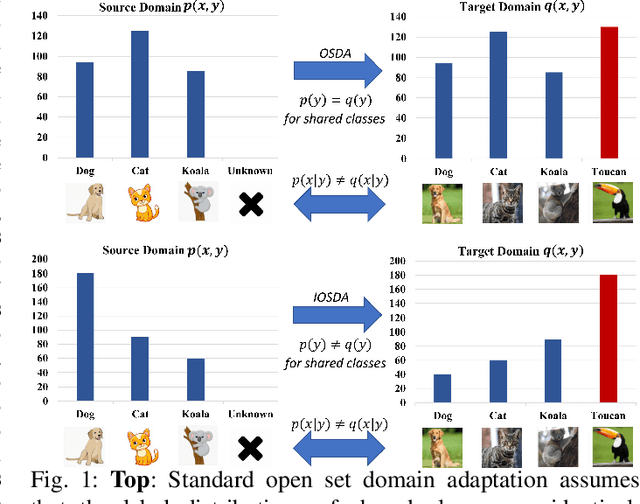
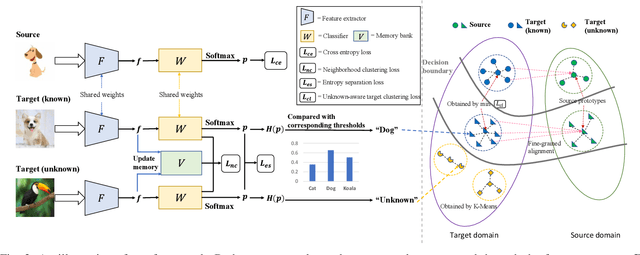
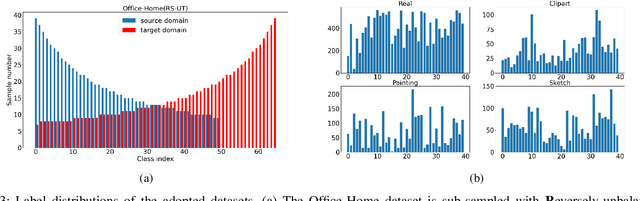
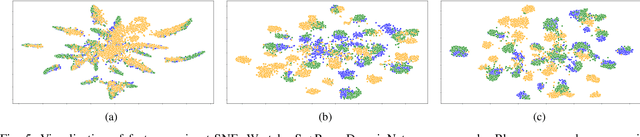
Multimedia applications are often associated with cross-domain knowledge transfer, where Unsupervised Domain Adaptation (UDA) can be used to reduce the domain shifts. Open Set Domain Adaptation (OSDA) aims to transfer knowledge from a well-labeled source domain to an unlabeled target domain under the assumption that the target domain contains unknown classes. Existing OSDA methods consistently lay stress on the covariate shift, ignoring the potential label shift problem. The performance of OSDA methods degrades drastically under intra-domain class imbalance and inter-domain label shift. However, little attention has been paid to this issue in the community. In this paper, the Imbalanced Open Set Domain Adaptation (IOSDA) is explored where the covariate shift, label shift and category mismatch exist simultaneously. To alleviate the negative effects raised by label shift in OSDA, we propose Open-set Moving-threshold Estimation and Gradual Alignment (OMEGA) - a novel architecture that improves existing OSDA methods on class-imbalanced data. Specifically, a novel unknown-aware target clustering scheme is proposed to form tight clusters in the target domain to reduce the negative effects of label shift and intra-domain class imbalance. Furthermore, moving-threshold estimation is designed to generate specific thresholds for each target sample rather than using one for all. Extensive experiments on IOSDA, OSDA and OPDA benchmarks demonstrate that our method could significantly outperform existing state-of-the-arts. Code and data are available at https://github.com/mendicant04/OMEGA.
Integrating Pre-trained Model into Rule-based Dialogue Management
Feb 17, 2021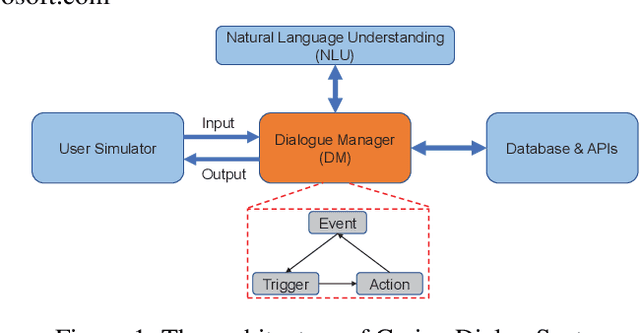
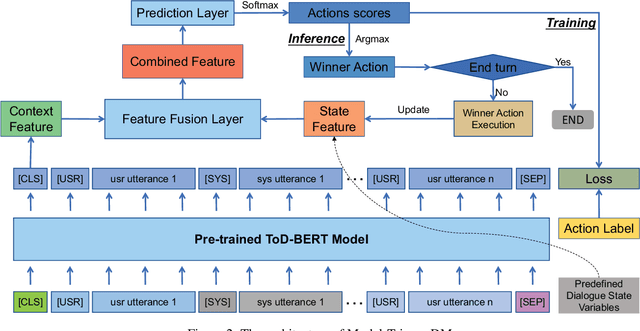
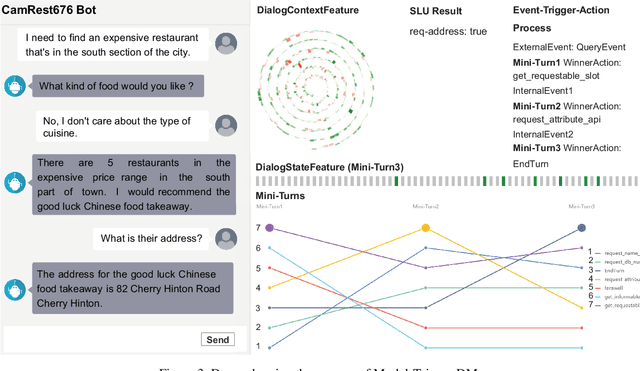
Rule-based dialogue management is still the most popular solution for industrial task-oriented dialogue systems for their interpretablility. However, it is hard for developers to maintain the dialogue logic when the scenarios get more and more complex. On the other hand, data-driven dialogue systems, usually with end-to-end structures, are popular in academic research and easier to deal with complex conversations, but such methods require plenty of training data and the behaviors are less interpretable. In this paper, we propose a method to leverages the strength of both rule-based and data-driven dialogue managers (DM). We firstly introduce the DM of Carina Dialog System (CDS, an advanced industrial dialogue system built by Microsoft). Then we propose the "model-trigger" design to make the DM trainable thus scalable to scenario changes. Furthermore, we integrate pre-trained models and empower the DM with few-shot capability. The experimental results demonstrate the effectiveness and strong few-shot capability of our method.