 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery-centric Audio-Visual Cognition Network for Moment Retrieval, Segmentation and Step-Captioning
Dec 18, 2024Video has emerged as a favored multimedia format on the internet. To better gain video contents, a new topic HIREST is presented, including video retrieval, moment retrieval, moment segmentation, and step-captioning. The pioneering work chooses the pre-trained CLIP-based model for video retrieval, and leverages it as a feature extractor for other three challenging tasks solved in a multi-task learning paradigm. Nevertheless, this work struggles to learn the comprehensive cognition of user-preferred content, due to disregarding the hierarchies and association relations across modalities. In this paper, guided by the shallow-to-deep principle, we propose a query-centric audio-visual cognition (QUAG) network to construct a reliable multi-modal representation for moment retrieval, segmentation and step-captioning. Specifically, we first design the modality-synergistic perception to obtain rich audio-visual content, by modeling global contrastive alignment and local fine-grained interaction between visual and audio modalities. Then, we devise the query-centric cognition that uses the deep-level query to perform the temporal-channel filtration on the shallow-level audio-visual representation. This can cognize user-preferred content and thus attain a query-centric audio-visual representation for three tasks. Extensive experiments show QUAG achieves the SOTA results on HIREST. Further, we test QUAG on the query-based video summarization task and verify its good generalization.
Distractors-Immune Representation Learning with Cross-modal Contrastive Regularization for Change Captioning
Jul 16, 2024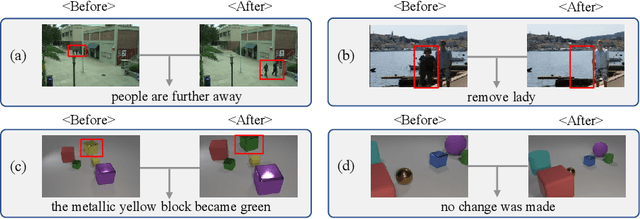
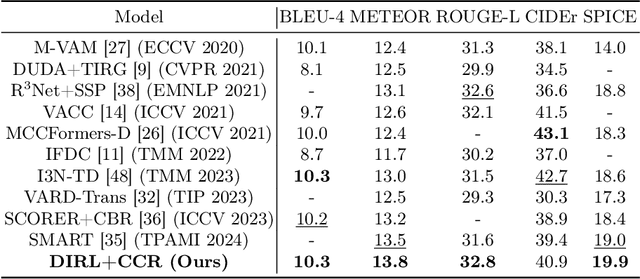
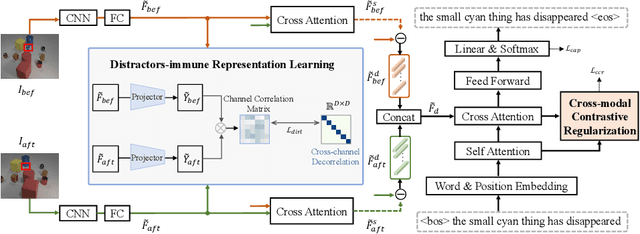
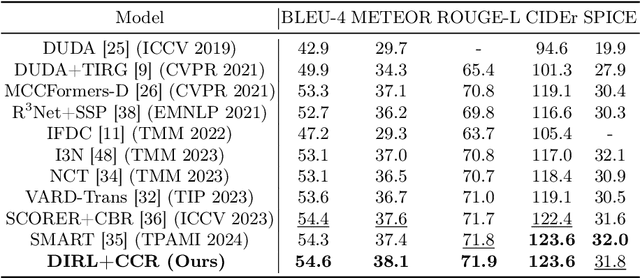
Change captioning aims to succinctly describe the semantic change between a pair of similar images, while being immune to distractors (illumination and viewpoint changes). Under these distractors, unchanged objects often appear pseudo changes about location and scale, and certain objects might overlap others, resulting in perturbational and discrimination-degraded features between two images. However, most existing methods directly capture the difference between them, which risk obtaining error-prone difference features. In this paper, we propose a distractors-immune representation learning network that correlates the corresponding channels of two image representations and decorrelates different ones in a self-supervised manner, thus attaining a pair of stable image representations under distractors. Then, the model can better interact them to capture the reliable difference features for caption generation. To yield words based on the most related difference features, we further design a cross-modal contrastive regularization, which regularizes the cross-modal alignment by maximizing the contrastive alignment between the attended difference features and generated words. Extensive experiments show that our method outperforms the state-of-the-art methods on four public datasets. The code is available at https://github.com/tuyunbin/DIRL.
Context-aware Difference Distilling for Multi-change Captioning
May 31, 2024Multi-change captioning aims to describe complex and coupled changes within an image pair in natural language. Compared with single-change captioning, this task requires the model to have higher-level cognition ability to reason an arbitrary number of changes. In this paper, we propose a novel context-aware difference distilling (CARD) network to capture all genuine changes for yielding sentences. Given an image pair, CARD first decouples context features that aggregate all similar/dissimilar semantics, termed common/difference context features. Then, the consistency and independence constraints are designed to guarantee the alignment/discrepancy of common/difference context features. Further, the common context features guide the model to mine locally unchanged features, which are subtracted from the pair to distill locally difference features. Next, the difference context features augment the locally difference features to ensure that all changes are distilled. In this way, we obtain an omni-representation of all changes, which is translated into linguistic sentences by a transformer decoder. Extensive experiments on three public datasets show CARD performs favourably against state-of-the-art methods.The code is available at https://github.com/tuyunbin/CARD.
Self-supervised Cross-view Representation Reconstruction for Change Captioning
Sep 28, 2023
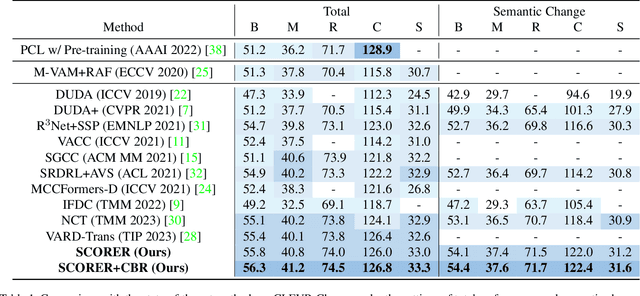
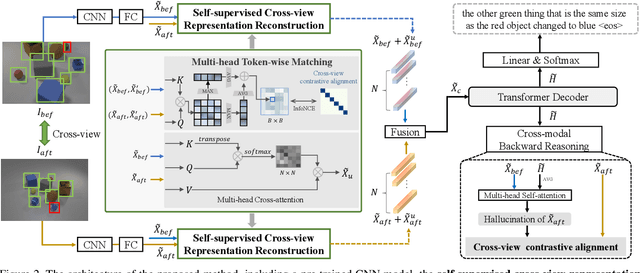
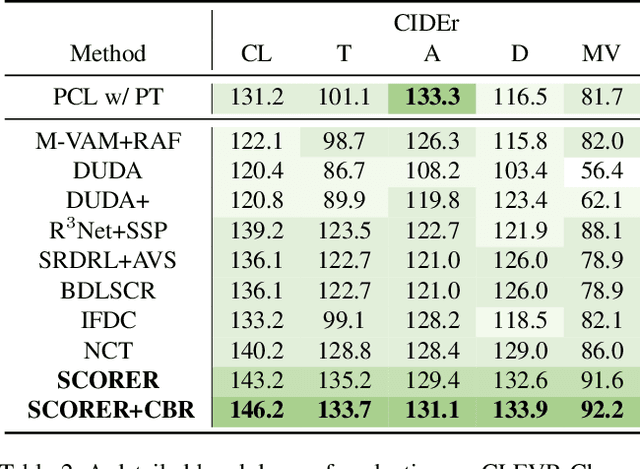
Change captioning aims to describe the difference between a pair of similar images. Its key challenge is how to learn a stable difference representation under pseudo changes caused by viewpoint change. In this paper, we address this by proposing a self-supervised cross-view representation reconstruction (SCORER) network. Concretely, we first design a multi-head token-wise matching to model relationships between cross-view features from similar/dissimilar images. Then, by maximizing cross-view contrastive alignment of two similar images, SCORER learns two view-invariant image representations in a self-supervised way. Based on these, we reconstruct the representations of unchanged objects by cross-attention, thus learning a stable difference representation for caption generation. Further, we devise a cross-modal backward reasoning to improve the quality of caption. This module reversely models a ``hallucination'' representation with the caption and ``before'' representation. By pushing it closer to the ``after'' representation, we enforce the caption to be informative about the difference in a self-supervised manner. Extensive experiments show our method achieves the state-of-the-art results on four datasets. The code is available at https://github.com/tuyunbin/SCORER.
Neighborhood Contrastive Transformer for Change Captioning
Mar 06, 2023



Change captioning is to describe the semantic change between a pair of similar images in natural language. It is more challenging than general image captioning, because it requires capturing fine-grained change information while being immune to irrelevant viewpoint changes, and solving syntax ambiguity in change descriptions. In this paper, we propose a neighborhood contrastive transformer to improve the model's perceiving ability for various changes under different scenes and cognition ability for complex syntax structure. Concretely, we first design a neighboring feature aggregating to integrate neighboring context into each feature, which helps quickly locate the inconspicuous changes under the guidance of conspicuous referents. Then, we devise a common feature distilling to compare two images at neighborhood level and extract common properties from each image, so as to learn effective contrastive information between them. Finally, we introduce the explicit dependencies between words to calibrate the transformer decoder, which helps better understand complex syntax structure during training. Extensive experimental results demonstrate that the proposed method achieves the state-of-the-art performance on three public datasets with different change scenarios. The code is available at https://github.com/tuyunbin/NCT.
R$^3$Net:Relation-embedded Representation Reconstruction Network for Change Captioning
Oct 20, 2021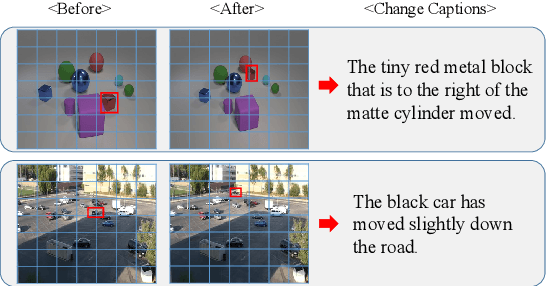
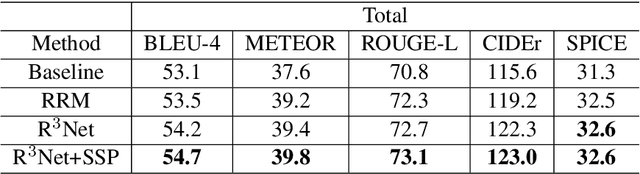
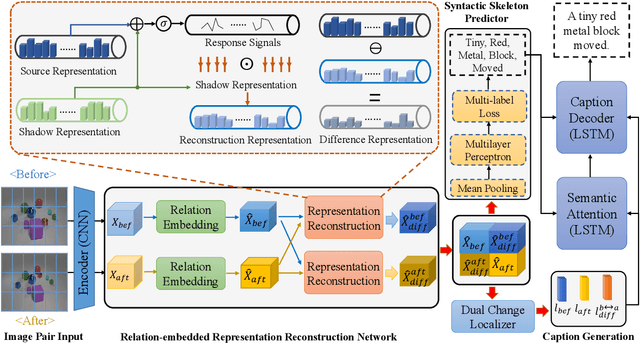
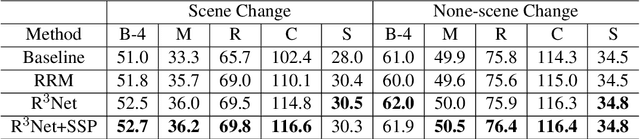
Change captioning is to use a natural language sentence to describe the fine-grained disagreement between two similar images. Viewpoint change is the most typical distractor in this task, because it changes the scale and location of the objects and overwhelms the representation of real change. In this paper, we propose a Relation-embedded Representation Reconstruction Network (R$^3$Net) to explicitly distinguish the real change from the large amount of clutter and irrelevant changes. Specifically, a relation-embedded module is first devised to explore potential changed objects in the large amount of clutter. Then, based on the semantic similarities of corresponding locations in the two images, a representation reconstruction module (RRM) is designed to learn the reconstruction representation and further model the difference representation. Besides, we introduce a syntactic skeleton predictor (SSP) to enhance the semantic interaction between change localization and caption generation. Extensive experiments show that the proposed method achieves the state-of-the-art results on two public datasets.