 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePathISE: Learning Informative Path Supervision for Knowledge Graph Question Answering
May 11, 2026Knowledge Graph Question Answering (KGQA) aims to answer user questions by reasoning over Knowledge Graphs (KGs). Recent KGQA methods mainly follow the retrieval-augmented generation paradigm to ground Large Language Models~(LLMs) with structured knowledge from KGs. However, training effective models to retrieve question-relevant evidence from KGs typically requires high-quality intermediate supervision signals, such as question-relevant paths or subgraphs, which are time- and resource-intensive to obtain. We propose PathISE, a novel framework for learning high-quality intermediate supervision from answer-level labels. PathISE introduces a lightweight transformer-based estimator that estimates the informativeness of relation paths to construct pseudo path-level supervision. This supervision is then distilled into an LLM path generator, whose generated paths are grounded in the KG to provide compact evidence for inductive answer reasoning. ExtensiveISE experiments on three KGQA benchmarks show that PathISE achieves competitive or state-of-the-art KGQA performance, and provides reusable supervision signals that can enhance existing KGQA models, without relying on costly LLM-refined supervision signals. Our source code is available at https://anonymous.4open.science/r/PathISE-2F87.
Consensus-Aligned Neuron Efficient Fine-Tuning Large Language Models for Multi-Domain Machine Translation
Feb 05, 2026Multi-domain machine translation (MDMT) aims to build a unified model capable of translating content across diverse domains. Despite the impressive machine translation capabilities demonstrated by large language models (LLMs), domain adaptation still remains a challenge for LLMs. Existing MDMT methods such as in-context learning and parameter-efficient fine-tuning often suffer from domain shift, parameter interference and limited generalization. In this work, we propose a neuron-efficient fine-tuning framework for MDMT that identifies and updates consensus-aligned neurons within LLMs. These neurons are selected by maximizing the mutual information between neuron behavior and domain features, enabling LLMs to capture both generalizable translation patterns and domain-specific nuances. Our method then fine-tunes LLMs guided by these neurons, effectively mitigating parameter interference and domain-specific overfitting. Comprehensive experiments on three LLMs across ten German-English and Chinese-English translation domains evidence that our method consistently outperforms strong PEFT baselines on both seen and unseen domains, achieving state-of-the-art performance.
Beyond Linearization: Attributed Table Graphs for Table Reasoning
Jan 13, 2026Table reasoning, a task to answer questions by reasoning over data presented in tables, is an important topic due to the prevalence of knowledge stored in tabular formats. Recent solutions use Large Language Models (LLMs), exploiting the semantic understanding and reasoning capabilities of LLMs. A common paradigm of such solutions linearizes tables to form plain texts that are served as input to LLMs. This paradigm has critical issues. It loses table structures, lacks explicit reasoning paths for result explainability, and is subject to the "lost-in-the-middle" issue. To address these issues, we propose Table Graph Reasoner (TABGR), a training-free model that represents tables as an Attributed Table Graph (ATG). The ATG explicitly preserves row-column-cell structures while enabling graph-based reasoning for explainability. We further propose a Question-Guided Personalized PageRank (QG-PPR) mechanism to rerank tabular data and mitigate the lost-in-the-middle issue. Extensive experiments on two commonly used benchmarks show that TABGR consistently outperforms state-of-the-art models by up to 9.7% in accuracy. Our code will be made publicly available upon publication.
Multilingual Generative Retrieval via Cross-lingual Semantic Compression
Oct 09, 2025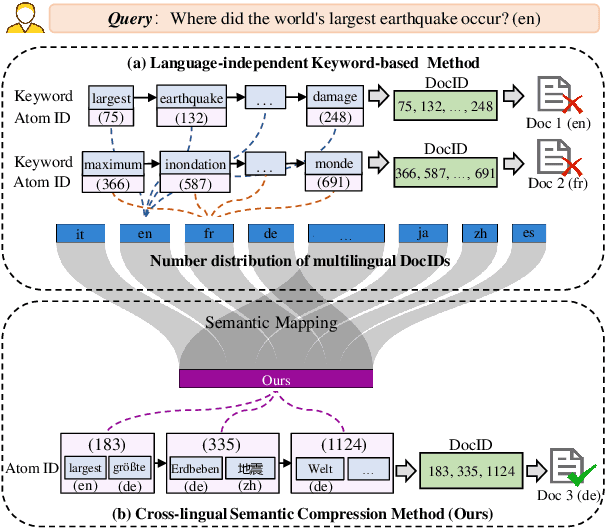
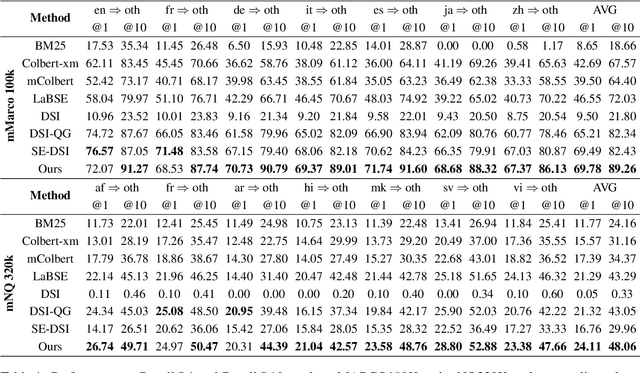
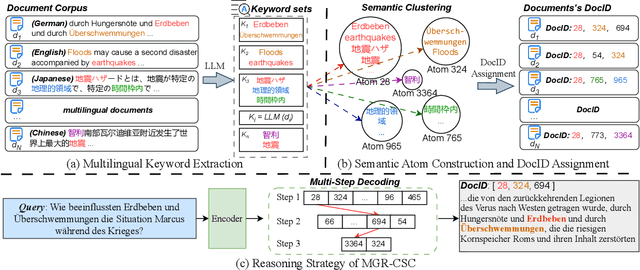

Generative Information Retrieval is an emerging retrieval paradigm that exhibits remarkable performance in monolingual scenarios.However, applying these methods to multilingual retrieval still encounters two primary challenges, cross-lingual identifier misalignment and identifier inflation. To address these limitations, we propose Multilingual Generative Retrieval via Cross-lingual Semantic Compression (MGR-CSC), a novel framework that unifies semantically equivalent multilingual keywords into shared atoms to align semantics and compresses the identifier space, and we propose a dynamic multi-step constrained decoding strategy during retrieval. MGR-CSC improves cross-lingual alignment by assigning consistent identifiers and enhances decoding efficiency by reducing redundancy. Experiments demonstrate that MGR-CSC achieves outstanding retrieval accuracy, improving by 6.83% on mMarco100k and 4.77% on mNQ320k, while reducing document identifiers length by 74.51% and 78.2%, respectively.
Beyond Seen Data: Improving KBQA Generalization Through Schema-Guided Logical Form Generation
Feb 19, 2025Knowledge base question answering (KBQA) aims to answer user questions in natural language using rich human knowledge stored in large KBs. As current KBQA methods struggle with unseen knowledge base elements at test time,we introduce SG-KBQA: a novel model that injects schema contexts into entity retrieval and logical form generation to tackle this issue. It uses the richer semantics and awareness of the knowledge base structure provided by schema contexts to enhance generalizability. We show that SG-KBQA achieves strong generalizability, outperforming state-of-the-art models on two commonly used benchmark datasets across a variety of test settings. Our source code is available at https://github.com/gaosx2000/SG_KBQA.
A Mixed-Language Multi-Document News Summarization Dataset and a Graphs-Based Extract-Generate Model
Oct 13, 2024Existing research on news summarization primarily focuses on single-language single-document (SLSD), single-language multi-document (SLMD) or cross-language single-document (CLSD). However, in real-world scenarios, news about a international event often involves multiple documents in different languages, i.e., mixed-language multi-document (MLMD). Therefore, summarizing MLMD news is of great significance. However, the lack of datasets for MLMD news summarization has constrained the development of research in this area. To fill this gap, we construct a mixed-language multi-document news summarization dataset (MLMD-news), which contains four different languages and 10,992 source document cluster and target summary pairs. Additionally, we propose a graph-based extract-generate model and benchmark various methods on the MLMD-news dataset and publicly release our dataset and code\footnote[1]{https://github.com/Southnf9/MLMD-news}, aiming to advance research in summarization within MLMD scenarios.
Multilingual Knowledge Graph Completion from Pretrained Language Models with Knowledge Constraints
Jun 26, 2024



Multilingual Knowledge Graph Completion (mKGC) aim at solving queries like (h, r, ?) in different languages by reasoning a tail entity t thus improving multilingual knowledge graphs. Previous studies leverage multilingual pretrained language models (PLMs) and the generative paradigm to achieve mKGC. Although multilingual pretrained language models contain extensive knowledge of different languages, its pretraining tasks cannot be directly aligned with the mKGC tasks. Moreover, the majority of KGs and PLMs currently available exhibit a pronounced English-centric bias. This makes it difficult for mKGC to achieve good results, particularly in the context of low-resource languages. To overcome previous problems, this paper introduces global and local knowledge constraints for mKGC. The former is used to constrain the reasoning of answer entities, while the latter is used to enhance the representation of query contexts. The proposed method makes the pretrained model better adapt to the mKGC task. Experimental results on public datasets demonstrate that our method outperforms the previous SOTA on Hits@1 and Hits@10 by an average of 12.32% and 16.03%, which indicates that our proposed method has significant enhancement on mKGC.
R$^3$Net:Relation-embedded Representation Reconstruction Network for Change Captioning
Oct 20, 2021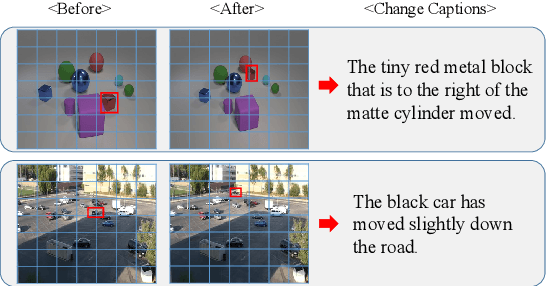
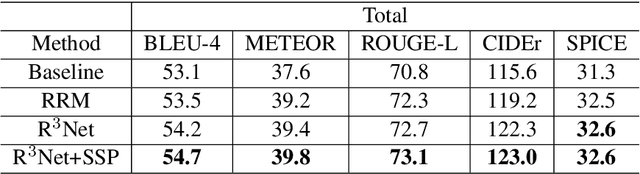
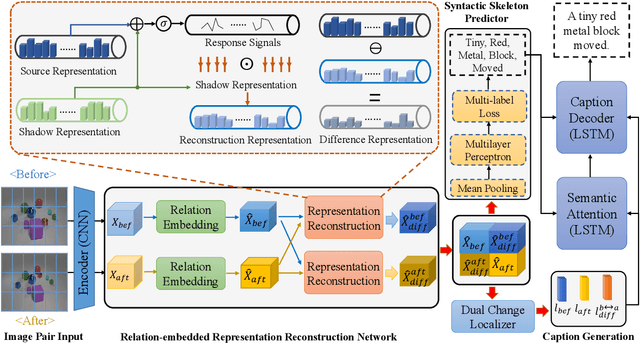
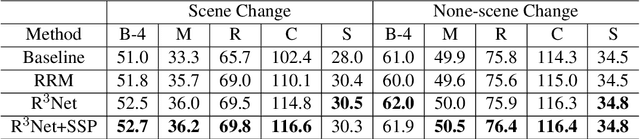
Change captioning is to use a natural language sentence to describe the fine-grained disagreement between two similar images. Viewpoint change is the most typical distractor in this task, because it changes the scale and location of the objects and overwhelms the representation of real change. In this paper, we propose a Relation-embedded Representation Reconstruction Network (R$^3$Net) to explicitly distinguish the real change from the large amount of clutter and irrelevant changes. Specifically, a relation-embedded module is first devised to explore potential changed objects in the large amount of clutter. Then, based on the semantic similarities of corresponding locations in the two images, a representation reconstruction module (RRM) is designed to learn the reconstruction representation and further model the difference representation. Besides, we introduce a syntactic skeleton predictor (SSP) to enhance the semantic interaction between change localization and caption generation. Extensive experiments show that the proposed method achieves the state-of-the-art results on two public datasets.