 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAUHead: Realistic Emotional Talking Head Generation via Action Units Control
Feb 10, 2026Realistic talking-head video generation is critical for virtual avatars, film production, and interactive systems. Current methods struggle with nuanced emotional expressions due to the lack of fine-grained emotion control. To address this issue, we introduce a novel two-stage method (AUHead) to disentangle fine-grained emotion control, i.e. , Action Units (AUs), from audio and achieve controllable generation. In the first stage, we explore the AU generation abilities of large audio-language models (ALMs), by spatial-temporal AU tokenization and an "emotion-then-AU" chain-of-thought mechanism. It aims to disentangle AUs from raw speech, effectively capturing subtle emotional cues. In the second stage, we propose an AU-driven controllable diffusion model that synthesizes realistic talking-head videos conditioned on AU sequences. Specifically, we first map the AU sequences into the structured 2D facial representation to enhance spatial fidelity, and then model the AU-vision interaction within cross-attention modules. To achieve flexible AU-quality trade-off control, we introduce an AU disentanglement guidance strategy during inference, further refining the emotional expressiveness and identity consistency of the generated videos. Results on benchmark datasets demonstrate that our approach achieves competitive performance in emotional realism, accurate lip synchronization, and visual coherence, significantly surpassing existing techniques. Our implementation is available at https://github.com/laura990501/AUHead_ICLR
Towards Unified Facial Action Unit Recognition Framework by Large Language Models
Sep 13, 2024



Facial Action Units (AUs) are of great significance in the realm of affective computing. In this paper, we propose AU-LLaVA, the first unified AU recognition framework based on the Large Language Model (LLM). AU-LLaVA consists of a visual encoder, a linear projector layer, and a pre-trained LLM. We meticulously craft the text descriptions and fine-tune the model on various AU datasets, allowing it to generate different formats of AU recognition results for the same input image. On the BP4D and DISFA datasets, AU-LLaVA delivers the most accurate recognition results for nearly half of the AUs. Our model achieves improvements of F1-score up to 11.4% in specific AU recognition compared to previous benchmark results. On the FEAFA dataset, our method achieves significant improvements over all 24 AUs compared to previous benchmark results. AU-LLaVA demonstrates exceptional performance and versatility in AU recognition.
MVLLaVA: An Intelligent Agent for Unified and Flexible Novel View Synthesis
Sep 11, 2024



This paper introduces MVLLaVA, an intelligent agent designed for novel view synthesis tasks. MVLLaVA integrates multiple multi-view diffusion models with a large multimodal model, LLaVA, enabling it to handle a wide range of tasks efficiently. MVLLaVA represents a versatile and unified platform that adapts to diverse input types, including a single image, a descriptive caption, or a specific change in viewing azimuth, guided by language instructions for viewpoint generation. We carefully craft task-specific instruction templates, which are subsequently used to fine-tune LLaVA. As a result, MVLLaVA acquires the capability to generate novel view images based on user instructions, demonstrating its flexibility across diverse tasks. Experiments are conducted to validate the effectiveness of MVLLaVA, demonstrating its robust performance and versatility in tackling diverse novel view synthesis challenges.
Pattern-Matching Dynamic Memory Network for Dual-Mode Traffic Prediction
Aug 12, 2024



In recent years, deep learning has increasingly gained attention in the field of traffic prediction. Existing traffic prediction models often rely on GCNs or attention mechanisms with O(N^2) complexity to dynamically extract traffic node features, which lack efficiency and are not lightweight. Additionally, these models typically only utilize historical data for prediction, without considering the impact of the target information on the prediction. To address these issues, we propose a Pattern-Matching Dynamic Memory Network (PM-DMNet). PM-DMNet employs a novel dynamic memory network to capture traffic pattern features with only O(N) complexity, significantly reducing computational overhead while achieving excellent performance. The PM-DMNet also introduces two prediction methods: Recursive Multi-step Prediction (RMP) and Parallel Multi-step Prediction (PMP), which leverage the time features of the prediction targets to assist in the forecasting process. Furthermore, a transfer attention mechanism is integrated into PMP, transforming historical data features to better align with the predicted target states, thereby capturing trend changes more accurately and reducing errors. Extensive experiments demonstrate the superiority of the proposed model over existing benchmarks. The source codes are available at: https://github.com/wengwenchao123/PM-DMNet.
FoodSAM: Any Food Segmentation
Aug 11, 2023



In this paper, we explore the zero-shot capability of the Segment Anything Model (SAM) for food image segmentation. To address the lack of class-specific information in SAM-generated masks, we propose a novel framework, called FoodSAM. This innovative approach integrates the coarse semantic mask with SAM-generated masks to enhance semantic segmentation quality. Besides, we recognize that the ingredients in food can be supposed as independent individuals, which motivated us to perform instance segmentation on food images. Furthermore, FoodSAM extends its zero-shot capability to encompass panoptic segmentation by incorporating an object detector, which renders FoodSAM to effectively capture non-food object information. Drawing inspiration from the recent success of promptable segmentation, we also extend FoodSAM to promptable segmentation, supporting various prompt variants. Consequently, FoodSAM emerges as an all-encompassing solution capable of segmenting food items at multiple levels of granularity. Remarkably, this pioneering framework stands as the first-ever work to achieve instance, panoptic, and promptable segmentation on food images. Extensive experiments demonstrate the feasibility and impressing performance of FoodSAM, validating SAM's potential as a prominent and influential tool within the domain of food image segmentation. We release our code at https://github.com/jamesjg/FoodSAM.
Rate-Splitting Multiple Access for Uplink Massive MIMO With Electromagnetic Exposure Constraints
Dec 14, 2022



Over the past few years, the prevalence of wireless devices has become one of the essential sources of electromagnetic (EM) radiation to the public. Facing with the swift development of wireless communications, people are skeptical about the risks of long-term exposure to EM radiation. As EM exposure is required to be restricted at user terminals, it is inefficient to blindly decrease the transmit power, which leads to limited spectral efficiency and energy efficiency (EE). Recently, rate-splitting multiple access (RSMA) has been proposed as an effective way to provide higher wireless transmission performance, which is a promising technology for future wireless communications. To this end, we propose using RSMA to increase the EE of massive MIMO uplink while limiting the EM exposure of users. In particularly, we investigate the optimization of the transmit covariance matrices and decoding order using statistical channel state information (CSI). The problem is formulated as non-convex mixed integer program, which is in general difficult to handle. We first propose a modified water-filling scheme to obtain the transmit covariance matrices with fixed decoding order. Then, a greedy approach is proposed to obtain the decoding permutation. Numerical results verify the effectiveness of the proposed EM exposure-aware EE maximization scheme for uplink RSMA.
Hybrid RIS and DMA Assisted Multiuser MIMO Uplink Transmission With Electromagnetic Exposure Constraints
May 10, 2022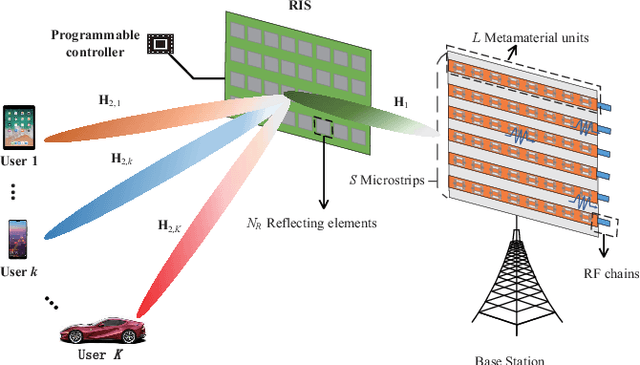
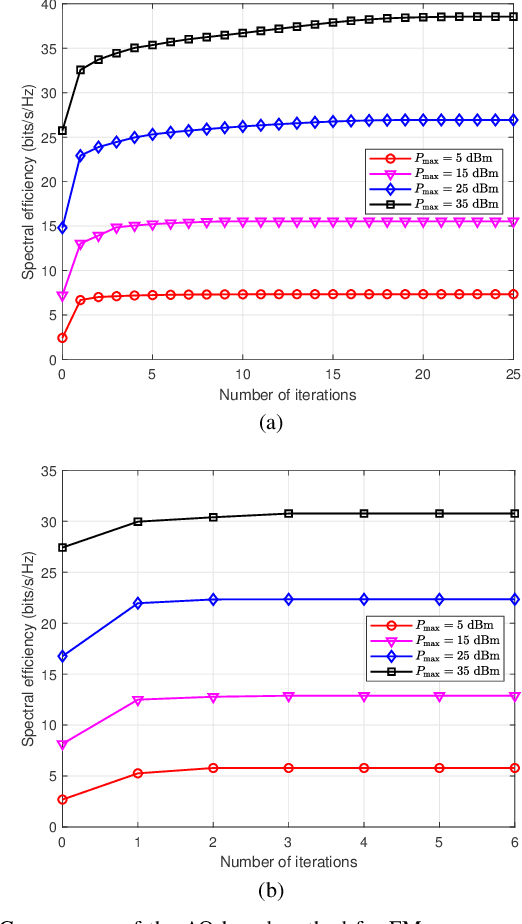
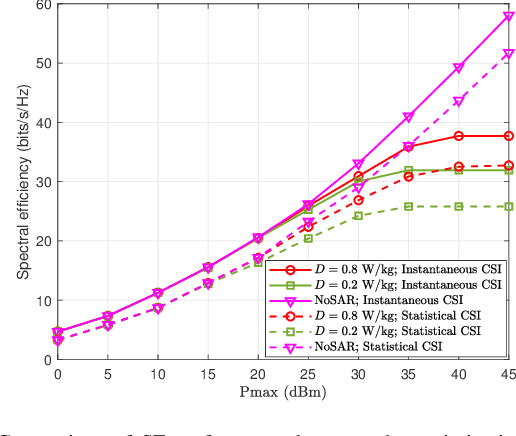
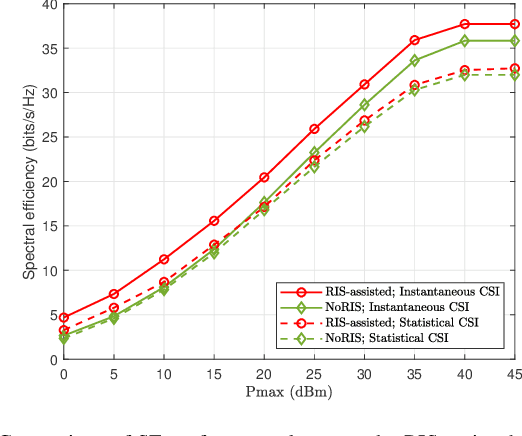
In the fifth-generation and beyond era, reconfigurable intelligent surface (RIS) and dynamic metasurface antennas (DMAs) are emerging metamaterials keeping up with the demand for high-quality wireless communication services, which promote the diversification of portable wireless terminals. However, along with the rapid expansion of wireless devices, the electromagnetic (EM) radiation increases unceasingly and inevitably affects public health, which requires a limited exposure level in the transmission design. To reduce the EM radiation and preserve the quality of communication service, we investigate the spectral efficiency (SE) maximization with EM constraints for uplink transmission in hybrid RIS and DMA assisted multiuser multiple-input multiple-output systems. Specifically, alternating optimization is adopted to optimize the transmit covariance, RIS phase shift, and DMA weight matrices. We first figure out the water-filling solutions of transmit covariance matrices with given RIS and DMA parameters. Then, the RIS phase shift matrix is optimized via the weighted minimum mean square error, block coordinate descent and minorization-maximization methods. Furthermore, we solve the unconstrainted DMA weight matrix optimization problem in closed form and then design the DMA weight matrix to approach this performance under DMA constraints. Numerical results confirm the effectiveness of the EM aware SE maximization transmission scheme over the conventional baselines.