 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReWiTe: Realistic Wide-angle and Telephoto Dual Camera Fusion Dataset via Beam Splitter Camera Rig
Apr 16, 2024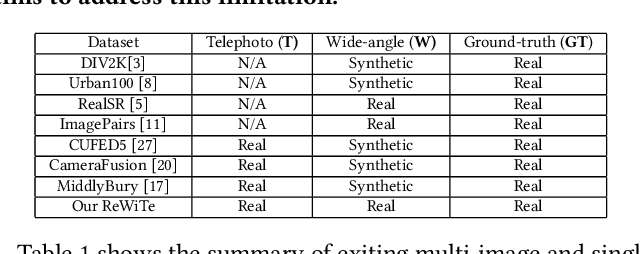
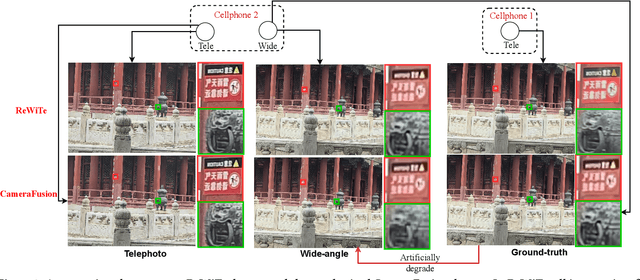
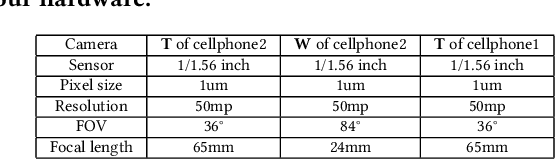

The fusion of images from dual camera systems featuring a wide-angle and a telephoto camera has become a hotspot problem recently. By integrating simultaneously captured wide-angle and telephoto images from these systems, the resulting fused image achieves a wide field of view (FOV) coupled with high-definition quality. Existing approaches are mostly deep learning methods, and predominantly rely on supervised learning, where the training dataset plays a pivotal role. However, current datasets typically adopt a data synthesis approach generate input pairs of wide-angle and telephoto images alongside ground-truth images. Notably, the wide-angle inputs are synthesized rather than captured using real wide-angle cameras, and the ground-truth image is captured by wide-angle camera whose quality is substantially lower than that of input telephoto images captured by telephoto cameras. To address these limitations, we introduce a novel hardware setup utilizing a beam splitter to simultaneously capture three images, i.e. input pairs and ground-truth images, from two authentic cellphones equipped with wide-angle and telephoto dual cameras. Specifically, the wide-angle and telephoto images captured by cellphone 2 serve as the input pair, while the telephoto image captured by cellphone 1, which is calibrated to match the optical path of the wide-angle image from cellphone 2, serves as the ground-truth image, maintaining quality on par with the input telephoto image. Experiments validate the efficacy of our newly introduced dataset, named ReWiTe, significantly enhances the performance of various existing methods for real-world wide-angle and telephoto dual image fusion tasks.
FoodSAM: Any Food Segmentation
Aug 11, 2023



In this paper, we explore the zero-shot capability of the Segment Anything Model (SAM) for food image segmentation. To address the lack of class-specific information in SAM-generated masks, we propose a novel framework, called FoodSAM. This innovative approach integrates the coarse semantic mask with SAM-generated masks to enhance semantic segmentation quality. Besides, we recognize that the ingredients in food can be supposed as independent individuals, which motivated us to perform instance segmentation on food images. Furthermore, FoodSAM extends its zero-shot capability to encompass panoptic segmentation by incorporating an object detector, which renders FoodSAM to effectively capture non-food object information. Drawing inspiration from the recent success of promptable segmentation, we also extend FoodSAM to promptable segmentation, supporting various prompt variants. Consequently, FoodSAM emerges as an all-encompassing solution capable of segmenting food items at multiple levels of granularity. Remarkably, this pioneering framework stands as the first-ever work to achieve instance, panoptic, and promptable segmentation on food images. Extensive experiments demonstrate the feasibility and impressing performance of FoodSAM, validating SAM's potential as a prominent and influential tool within the domain of food image segmentation. We release our code at https://github.com/jamesjg/FoodSAM.
Relay Hindsight Experience Replay: Continual Reinforcement Learning for Robot Manipulation Tasks with Sparse Rewards
Aug 01, 2022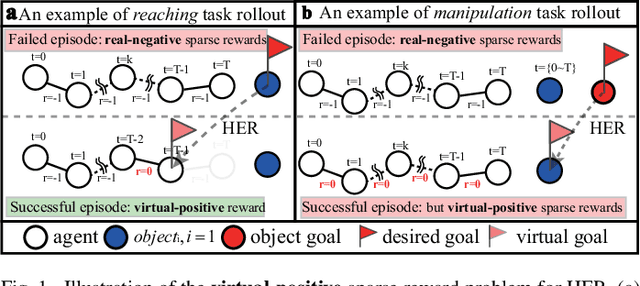
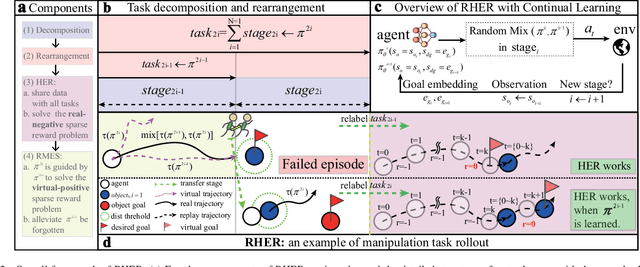
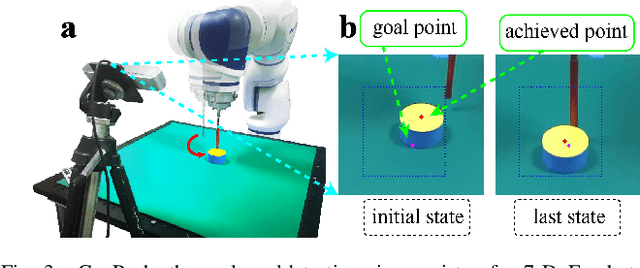
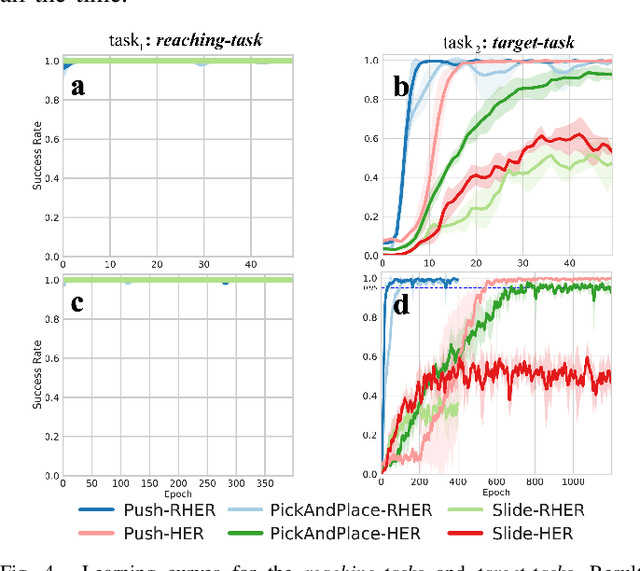
Learning with sparse rewards is usually inefficient in Reinforcement Learning (RL). Hindsight Experience Replay (HER) has been shown an effective solution to handle the low sample efficiency that results from sparse rewards by goal relabeling. However, the HER still has an implicit virtual-positive sparse reward problem caused by invariant achieved goals, especially for robot manipulation tasks. To solve this problem, we propose a novel model-free continual RL algorithm, called Relay-HER (RHER). The proposed method first decomposes and rearranges the original long-horizon task into new sub-tasks with incremental complexity. Subsequently, a multi-task network is designed to learn the sub-tasks in ascending order of complexity. To solve the virtual-positive sparse reward problem, we propose a Random-Mixed Exploration Strategy (RMES), in which the achieved goals of the sub-task with higher complexity are quickly changed under the guidance of the one with lower complexity. The experimental results indicate the significant improvements in sample efficiency of RHER compared to vanilla-HER in five typical robot manipulation tasks, including Push, PickAndPlace, Drawer, Insert, and ObstaclePush. The proposed RHER method has also been applied to learn a contact-rich push task on a physical robot from scratch, and the success rate reached 10/10 with only 250 episodes.
On-the-Fly Rectification for Robust Large-Vocabulary Topic Inference
Nov 12, 2021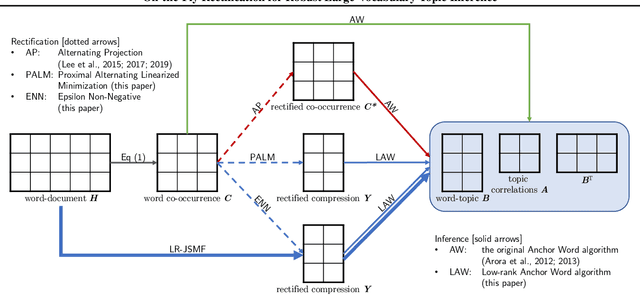

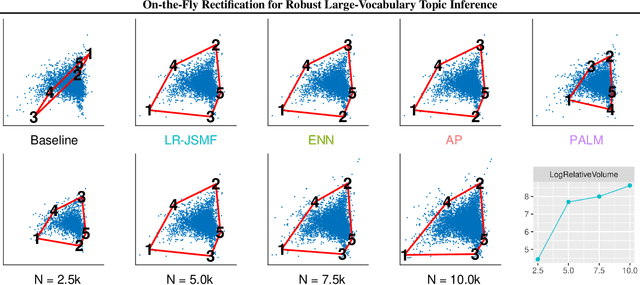
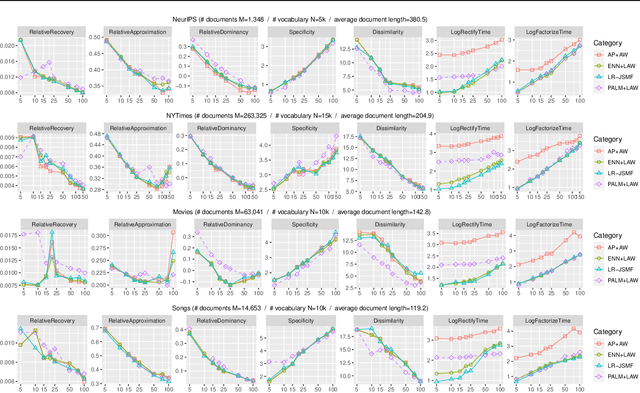
Across many data domains, co-occurrence statistics about the joint appearance of objects are powerfully informative. By transforming unsupervised learning problems into decompositions of co-occurrence statistics, spectral algorithms provide transparent and efficient algorithms for posterior inference such as latent topic analysis and community detection. As object vocabularies grow, however, it becomes rapidly more expensive to store and run inference algorithms on co-occurrence statistics. Rectifying co-occurrence, the key process to uphold model assumptions, becomes increasingly more vital in the presence of rare terms, but current techniques cannot scale to large vocabularies. We propose novel methods that simultaneously compress and rectify co-occurrence statistics, scaling gracefully with the size of vocabulary and the dimension of latent space. We also present new algorithms learning latent variables from the compressed statistics, and verify that our methods perform comparably to previous approaches on both textual and non-textual data.
Balance Between Efficient and Effective Learning: Dense2Sparse Reward Shaping for Robot Manipulation with Environment Uncertainty
Mar 05, 2020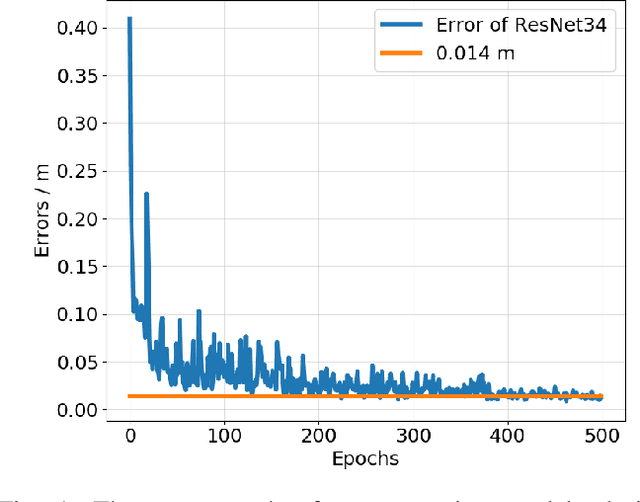
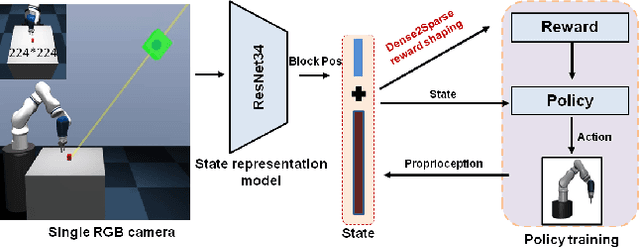
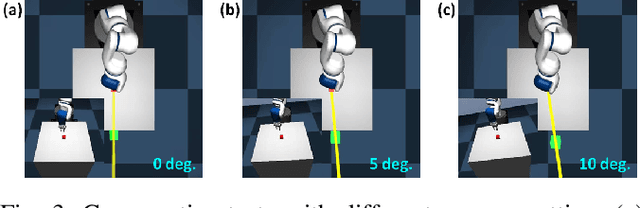
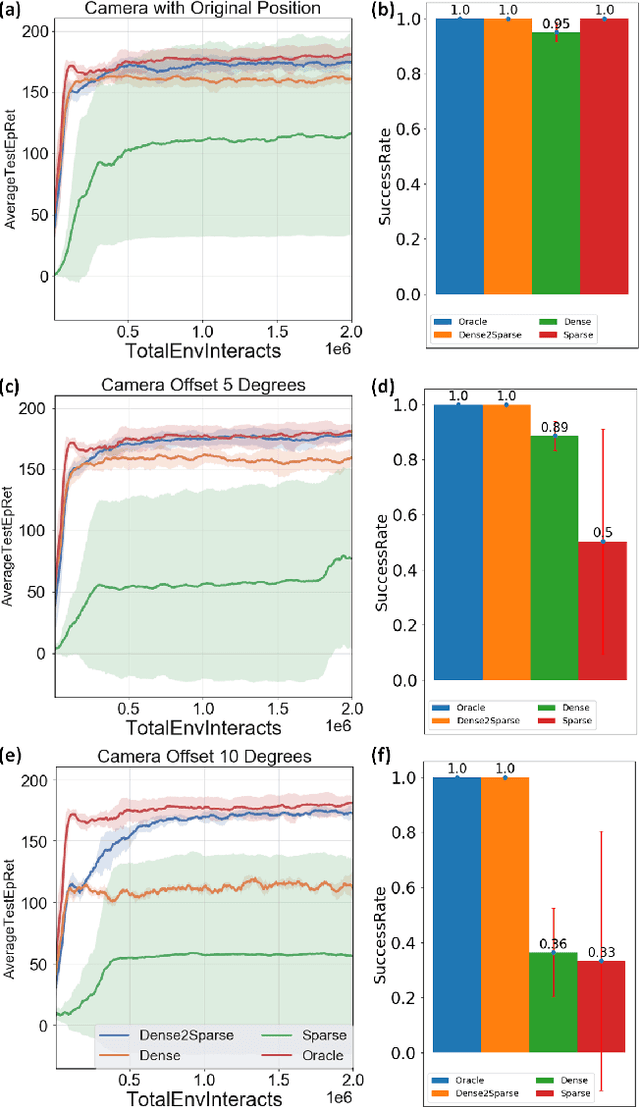
Efficient and effective learning is one of the ultimate goals of the deep reinforcement learning (DRL), although the compromise has been made in most of the time, especially for the application of robot manipulations. Learning is always expensive for robot manipulation tasks and the learning effectiveness could be affected by the system uncertainty. In order to solve above challenges, in this study, we proposed a simple but powerful reward shaping method, namely Dense2Sparse. It combines the advantage of fast convergence of dense reward and the noise isolation of the sparse reward, to achieve a balance between learning efficiency and effectiveness, which makes it suitable for robot manipulation tasks. We evaluated our Dense2Sparse method with a series of ablation experiments using the state representation model with system uncertainty. The experiment results show that the Dense2Sparse method obtained higher expected reward compared with the ones using standalone dense reward or sparse reward, and it also has a superior tolerance of system uncertainty.
Scaling Gaussian Process Regression with Derivatives
Oct 29, 2018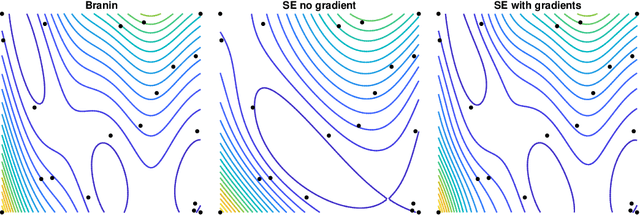
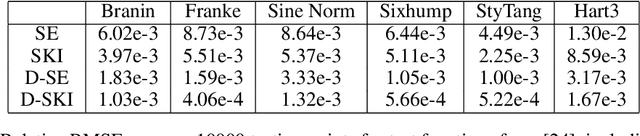
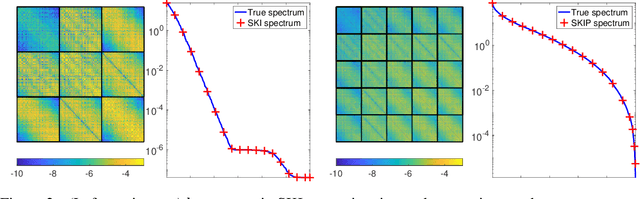
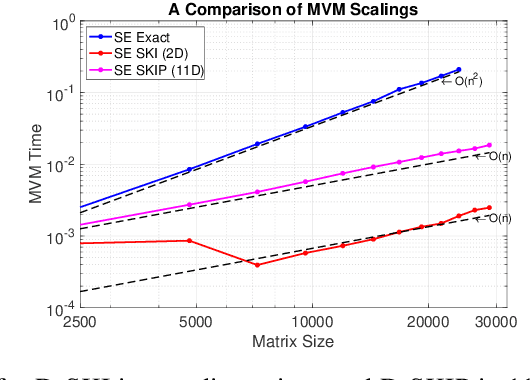
Gaussian processes (GPs) with derivatives are useful in many applications, including Bayesian optimization, implicit surface reconstruction, and terrain reconstruction. Fitting a GP to function values and derivatives at $n$ points in $d$ dimensions requires linear solves and log determinants with an ${n(d+1) \times n(d+1)}$ positive definite matrix -- leading to prohibitive $\mathcal{O}(n^3d^3)$ computations for standard direct methods. We propose iterative solvers using fast $\mathcal{O}(nd)$ matrix-vector multiplications (MVMs), together with pivoted Cholesky preconditioning that cuts the iterations to convergence by several orders of magnitude, allowing for fast kernel learning and prediction. Our approaches, together with dimensionality reduction, enables Bayesian optimization with derivatives to scale to high-dimensional problems and large evaluation budgets.
* Appears at Advances in Neural Information Processing Systems 32 (NIPS), 2018
Scalable Log Determinants for Gaussian Process Kernel Learning
Nov 09, 2017

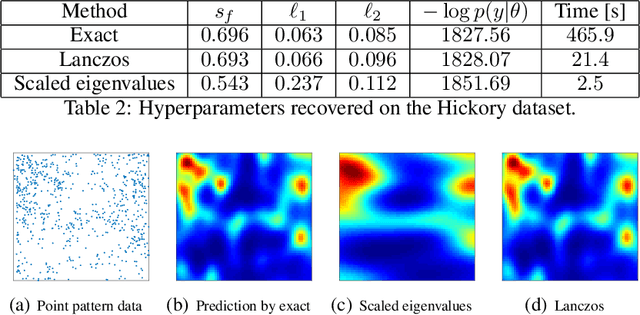

For applications as varied as Bayesian neural networks, determinantal point processes, elliptical graphical models, and kernel learning for Gaussian processes (GPs), one must compute a log determinant of an $n \times n$ positive definite matrix, and its derivatives - leading to prohibitive $\mathcal{O}(n^3)$ computations. We propose novel $\mathcal{O}(n)$ approaches to estimating these quantities from only fast matrix vector multiplications (MVMs). These stochastic approximations are based on Chebyshev, Lanczos, and surrogate models, and converge quickly even for kernel matrices that have challenging spectra. We leverage these approximations to develop a scalable Gaussian process approach to kernel learning. We find that Lanczos is generally superior to Chebyshev for kernel learning, and that a surrogate approach can be highly efficient and accurate with popular kernels.
* Appears at Advances in Neural Information Processing Systems 30 (NIPS), 2017