 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn-the-Fly Rectification for Robust Large-Vocabulary Topic Inference
Paper and Code
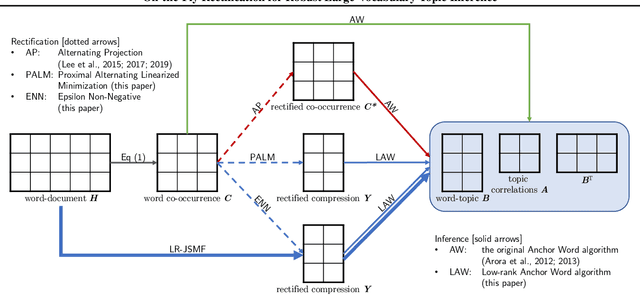

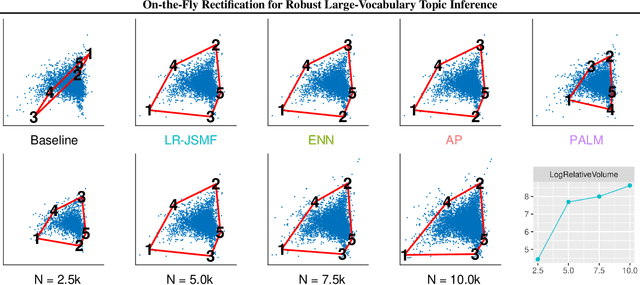
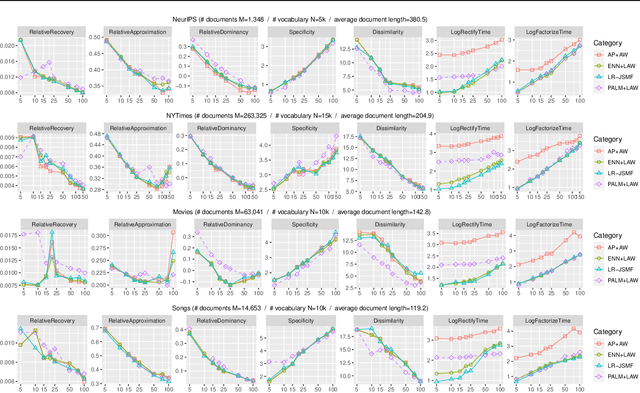
Across many data domains, co-occurrence statistics about the joint appearance of objects are powerfully informative. By transforming unsupervised learning problems into decompositions of co-occurrence statistics, spectral algorithms provide transparent and efficient algorithms for posterior inference such as latent topic analysis and community detection. As object vocabularies grow, however, it becomes rapidly more expensive to store and run inference algorithms on co-occurrence statistics. Rectifying co-occurrence, the key process to uphold model assumptions, becomes increasingly more vital in the presence of rare terms, but current techniques cannot scale to large vocabularies. We propose novel methods that simultaneously compress and rectify co-occurrence statistics, scaling gracefully with the size of vocabulary and the dimension of latent space. We also present new algorithms learning latent variables from the compressed statistics, and verify that our methods perform comparably to previous approaches on both textual and non-textual data.