 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelay Hindsight Experience Replay: Continual Reinforcement Learning for Robot Manipulation Tasks with Sparse Rewards
Paper and Code
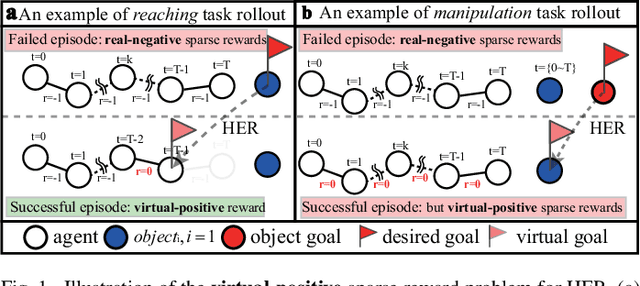
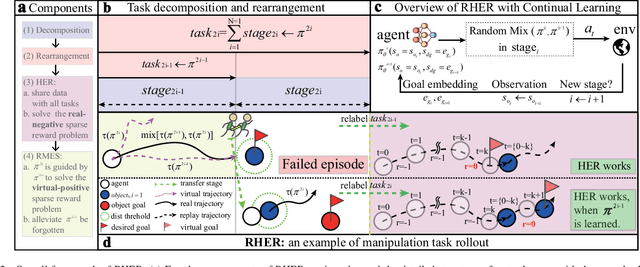
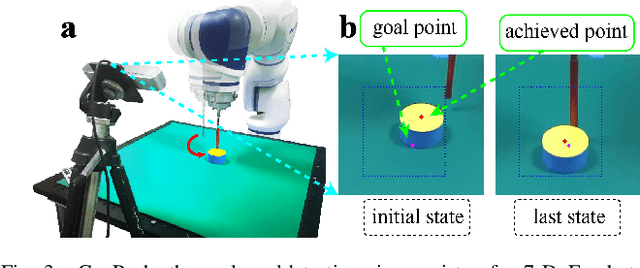
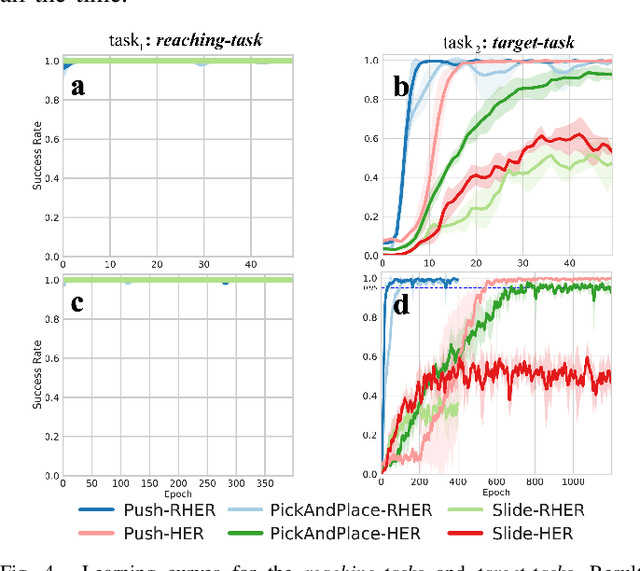
Learning with sparse rewards is usually inefficient in Reinforcement Learning (RL). Hindsight Experience Replay (HER) has been shown an effective solution to handle the low sample efficiency that results from sparse rewards by goal relabeling. However, the HER still has an implicit virtual-positive sparse reward problem caused by invariant achieved goals, especially for robot manipulation tasks. To solve this problem, we propose a novel model-free continual RL algorithm, called Relay-HER (RHER). The proposed method first decomposes and rearranges the original long-horizon task into new sub-tasks with incremental complexity. Subsequently, a multi-task network is designed to learn the sub-tasks in ascending order of complexity. To solve the virtual-positive sparse reward problem, we propose a Random-Mixed Exploration Strategy (RMES), in which the achieved goals of the sub-task with higher complexity are quickly changed under the guidance of the one with lower complexity. The experimental results indicate the significant improvements in sample efficiency of RHER compared to vanilla-HER in five typical robot manipulation tasks, including Push, PickAndPlace, Drawer, Insert, and ObstaclePush. The proposed RHER method has also been applied to learn a contact-rich push task on a physical robot from scratch, and the success rate reached 10/10 with only 250 episodes.