 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedLatentDx: Latent Multi-Agent Communication for Cross-Hospital Rare-Disease Diagnosis
Jun 11, 2026Rare diseases affect over $300$ million patients across more than $7{,}000$ conditions, yet no single hospital encounters enough cases of any one condition for reliable diagnosis. Cross-hospital collaboration could help by allowing a diagnosing institution to use distributed, case-specific diagnostic evidence, but privacy regulations restrict the transmission of identifiable clinical text across institutional boundaries. This setting raises two challenges: existing medical agent systems often rely on textual evidence exchange, while raw latent states such as hidden states and KV caches may still reveal prompt-derived clinical content. We introduce MedLatentDx, a latent multi-agent communication framework in which hospital agents keep private clinical records and retrieved cases local, and send compact latent KV blocks to a host agent for rare-disease diagnosis. MedLatentDx supports two deployment settings: same-backbone hospital agents use latent KV distillation, while hospitals with different LLM backbones use cross-family latent alignment. On CrossRare-Bench, a self-built large-scale rare-disease benchmark with hospital-level partitions, MedLatentDx improves cross-hospital diagnostic performance while reducing reconstructable clinical content relative to raw-latent communication baselines.
STRIDE: Strategic Iterative Decision-Making for Retrieval-Augmented Multi-Hop Question Answering
Apr 19, 2026Multi-hop question answering (MHQA) enables accurate answers to complex queries by retrieving and reasoning over evidence dispersed across multiple documents. Existing MHQA approaches mainly rely on iterative retrieval-augmented generation, which suffer from the following two major issues. 1) Existing methods prematurely commit to surface-level entities rather than underlying reasoning structures, making question decomposition highly vulnerable to lexical ambiguity. 2) Existing methods overlook the logical dependencies among reasoning steps, resulting in uncoordinated execution. To address these issues, we propose STRIDE, a framework that separates strategic planning, dynamic control, and grounded execution. At its core, a Meta-Planner first constructs an entity-agnostic reasoning skeleton to capture the abstract logic of the query, thereby deferring entity grounding until after the reasoning structure is established, which mitigates disambiguation errors caused by premature lexical commitment. A Supervisor then orchestrates sub-question execution in a dependency-aware manner, enabling efficient parallelization where possible and sequential coordination when necessary. By dynamically deciding whether to retrieve new evidence or infer from existing facts, it avoids redundant queries and error propagation, while fusing cross-branch information and reformulating failed queries to enhance robustness. Grounded fact extraction and logical inference are delegated to specialized execution modules, ensuring faithfulness through explicit separation of retrieval and reasoning. We further propose STRIDE-FT, a modular fine-tuning framework that uses self-generated execution trajectories from STRIDE, requiring neither human annotations nor stronger teacher models. Experiments show that STRIDE achieves robust and accurate reasoning, while STRIDE-FT effectively enhances open-source LLMs.
Simulating Human-Like Learning Dynamics with LLM-Empowered Agents
Aug 07, 2025Capturing human learning behavior based on deep learning methods has become a major research focus in both psychology and intelligent systems. Recent approaches rely on controlled experiments or rule-based models to explore cognitive processes. However, they struggle to capture learning dynamics, track progress over time, or provide explainability. To address these challenges, we introduce LearnerAgent, a novel multi-agent framework based on Large Language Models (LLMs) to simulate a realistic teaching environment. To explore human-like learning dynamics, we construct learners with psychologically grounded profiles-such as Deep, Surface, and Lazy-as well as a persona-free General Learner to inspect the base LLM's default behavior. Through weekly knowledge acquisition, monthly strategic choices, periodic tests, and peer interaction, we can track the dynamic learning progress of individual learners over a full-year journey. Our findings are fourfold: 1) Longitudinal analysis reveals that only Deep Learner achieves sustained cognitive growth. Our specially designed "trap questions" effectively diagnose Surface Learner's shallow knowledge. 2) The behavioral and cognitive patterns of distinct learners align closely with their psychological profiles. 3) Learners' self-concept scores evolve realistically, with the General Learner developing surprisingly high self-efficacy despite its cognitive limitations. 4) Critically, the default profile of base LLM is a "diligent but brittle Surface Learner"-an agent that mimics the behaviors of a good student but lacks true, generalizable understanding. Extensive simulation experiments demonstrate that LearnerAgent aligns well with real scenarios, yielding more insightful findings about LLMs' behavior.
Cyst-X: AI-Powered Pancreatic Cancer Risk Prediction from Multicenter MRI in Centralized and Federated Learning
Jul 29, 2025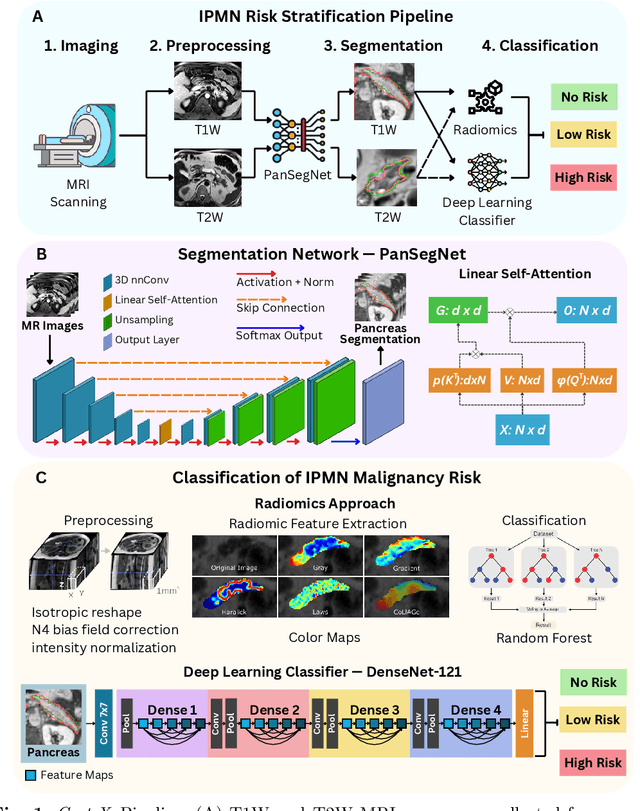

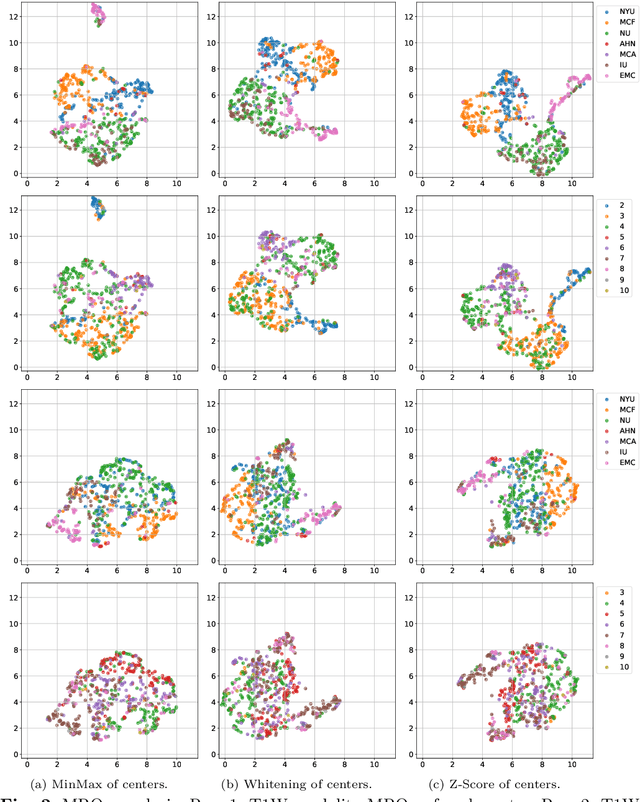
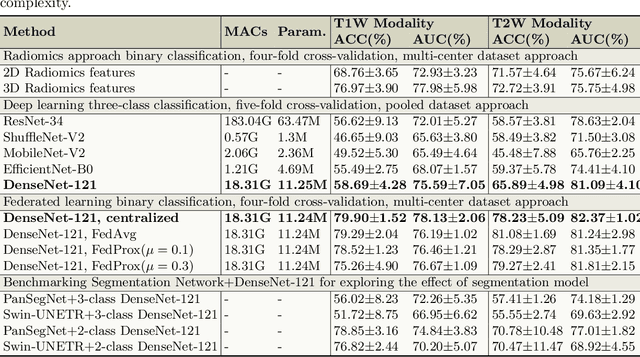
Pancreatic cancer is projected to become the second-deadliest malignancy in Western countries by 2030, highlighting the urgent need for better early detection. Intraductal papillary mucinous neoplasms (IPMNs), key precursors to pancreatic cancer, are challenging to assess with current guidelines, often leading to unnecessary surgeries or missed malignancies. We present Cyst-X, an AI framework that predicts IPMN malignancy using multicenter MRI data, leveraging MRI's superior soft tissue contrast over CT. Trained on 723 T1- and 738 T2-weighted scans from 764 patients across seven institutions, our models (AUC=0.82) significantly outperform both Kyoto guidelines (AUC=0.75) and expert radiologists. The AI-derived imaging features align with known clinical markers and offer biologically meaningful insights. We also demonstrate strong performance in a federated learning setting, enabling collaborative training without sharing patient data. To promote privacy-preserving AI development and improve IPMN risk stratification, the Cyst-X dataset is released as the first large-scale, multi-center pancreatic cysts MRI dataset.
MiMu: Mitigating Multiple Shortcut Learning Behavior of Transformers
Apr 14, 2025Empirical Risk Minimization (ERM) models often rely on spurious correlations between features and labels during the learning process, leading to shortcut learning behavior that undermines robustness generalization performance. Current research mainly targets identifying or mitigating a single shortcut; however, in real-world scenarios, cues within the data are diverse and unknown. In empirical studies, we reveal that the models rely to varying extents on different shortcuts. Compared to weak shortcuts, models depend more heavily on strong shortcuts, resulting in their poor generalization ability. To address these challenges, we propose MiMu, a novel method integrated with Transformer-based ERMs designed to Mitigate Multiple shortcut learning behavior, which incorporates self-calibration strategy and self-improvement strategy. In the source model, we preliminarily propose the self-calibration strategy to prevent the model from relying on shortcuts and make overconfident predictions. Then, we further design self-improvement strategy in target model to reduce the reliance on multiple shortcuts. The random mask strategy involves randomly masking partial attention positions to diversify the focus of target model other than concentrating on a fixed region. Meanwhile, the adaptive attention alignment module facilitates the alignment of attention weights to the calibrated source model, without the need for post-hoc attention maps or supervision. Finally, extensive experiments conducted on Natural Language Processing (NLP) and Computer Vision (CV) demonstrate the effectiveness of MiMu in improving robustness generalization abilities.
Do LLMs Overcome Shortcut Learning? An Evaluation of Shortcut Challenges in Large Language Models
Oct 17, 2024



Large Language Models (LLMs) have shown remarkable capabilities in various natural language processing tasks. However, LLMs may rely on dataset biases as shortcuts for prediction, which can significantly impair their robustness and generalization capabilities. This paper presents Shortcut Suite, a comprehensive test suite designed to evaluate the impact of shortcuts on LLMs' performance, incorporating six shortcut types, five evaluation metrics, and four prompting strategies. Our extensive experiments yield several key findings: 1) LLMs demonstrate varying reliance on shortcuts for downstream tasks, significantly impairing their performance. 2) Larger LLMs are more likely to utilize shortcuts under zero-shot and few-shot in-context learning prompts. 3) Chain-of-thought prompting notably reduces shortcut reliance and outperforms other prompting strategies, while few-shot prompts generally underperform compared to zero-shot prompts. 4) LLMs often exhibit overconfidence in their predictions, especially when dealing with datasets that contain shortcuts. 5) LLMs generally have a lower explanation quality in shortcut-laden datasets, with errors falling into three types: distraction, disguised comprehension, and logical fallacy. Our findings offer new insights for evaluating robustness and generalization in LLMs and suggest potential directions for mitigating the reliance on shortcuts. The code is available at \url {https://github.com/yyhappier/ShortcutSuite.git}.
Event Grounded Criminal Court View Generation with Cooperative (Large) Language Models
Apr 13, 2024



With the development of legal intelligence, Criminal Court View Generation has attracted much attention as a crucial task of legal intelligence, which aims to generate concise and coherent texts that summarize case facts and provide explanations for verdicts. Existing researches explore the key information in case facts to yield the court views. Most of them employ a coarse-grained approach that partitions the facts into broad segments (e.g., verdict-related sentences) to make predictions. However, this approach fails to capture the complex details present in the case facts, such as various criminal elements and legal events. To this end, in this paper, we propose an Event Grounded Generation (EGG) method for criminal court view generation with cooperative (Large) Language Models, which introduces the fine-grained event information into the generation. Specifically, we first design a LLMs-based extraction method that can extract events in case facts without massive annotated events. Then, we incorporate the extracted events into court view generation by merging case facts and events. Besides, considering the computational burden posed by the use of LLMs in the extraction phase of EGG, we propose a LLMs-free EGG method that can eliminate the requirement for event extraction using LLMs in the inference phase. Extensive experimental results on a real-world dataset clearly validate the effectiveness of our proposed method.
Deep learning radiomics for assessment of gastroesophageal varices in people with compensated advanced chronic liver disease
Jun 13, 2023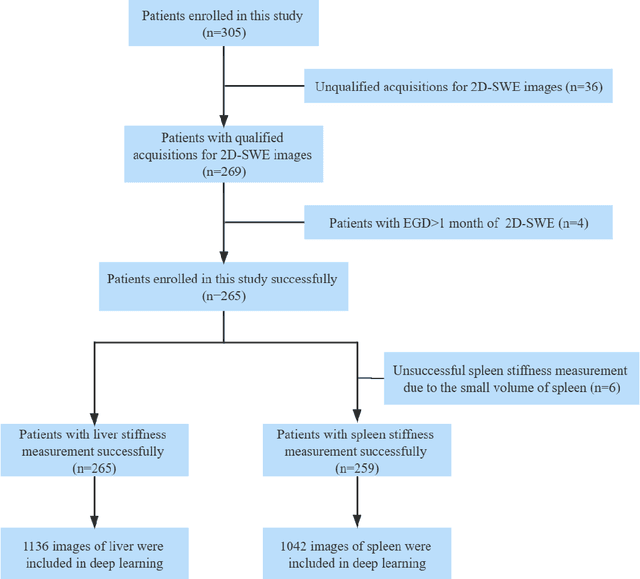
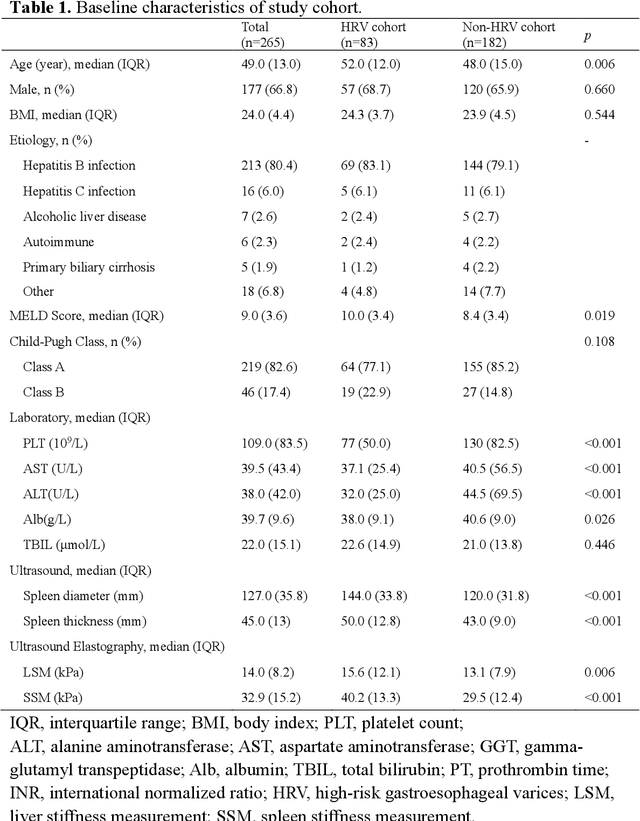
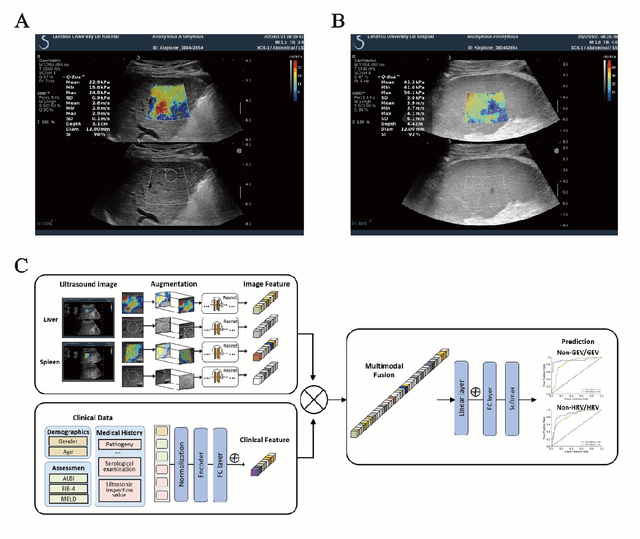
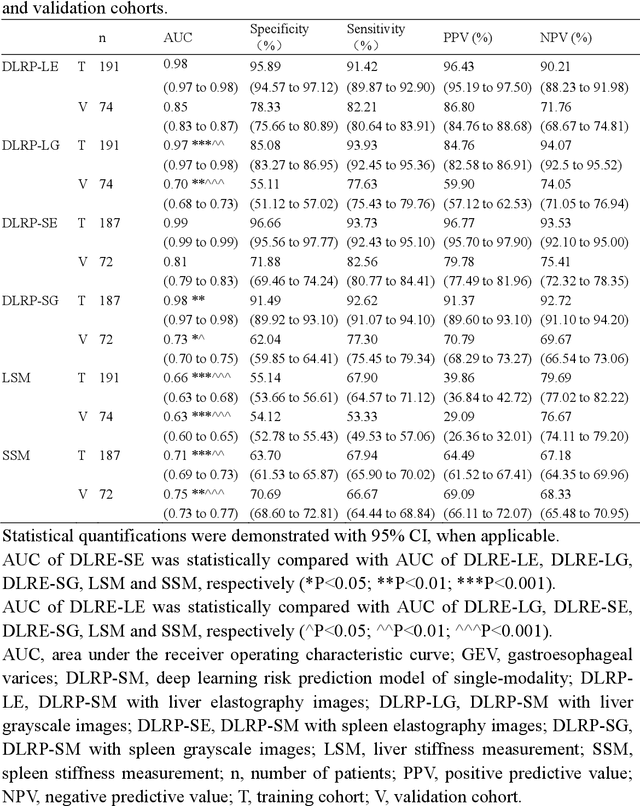
Objective: Bleeding from gastroesophageal varices (GEV) is a medical emergency associated with high mortality. We aim to construct an artificial intelligence-based model of two-dimensional shear wave elastography (2D-SWE) of the liver and spleen to precisely assess the risk of GEV and high-risk gastroesophageal varices (HRV). Design: A prospective multicenter study was conducted in patients with compensated advanced chronic liver disease. 305 patients were enrolled from 12 hospitals, and finally 265 patients were included, with 1136 liver stiffness measurement (LSM) images and 1042 spleen stiffness measurement (SSM) images generated by 2D-SWE. We leveraged deep learning methods to uncover associations between image features and patient risk, and thus conducted models to predict GEV and HRV. Results: A multi-modality Deep Learning Risk Prediction model (DLRP) was constructed to assess GEV and HRV, based on LSM and SSM images, and clinical information. Validation analysis revealed that the AUCs of DLRP were 0.91 for GEV (95% CI 0.90 to 0.93, p < 0.05) and 0.88 for HRV (95% CI 0.86 to 0.89, p < 0.01), which were significantly and robustly better than canonical risk indicators, including the value of LSM and SSM. Moreover, DLPR was better than the model using individual parameters, including LSM and SSM images. In HRV prediction, the 2D-SWE images of SSM outperform LSM (p < 0.01). Conclusion: DLRP shows excellent performance in predicting GEV and HRV over canonical risk indicators LSM and SSM. Additionally, the 2D-SWE images of SSM provided more information for better accuracy in predicting HRV than the LSM.
Lossless Point Cloud Attribute Compression with Normal-based Intra Prediction
Jun 23, 2021
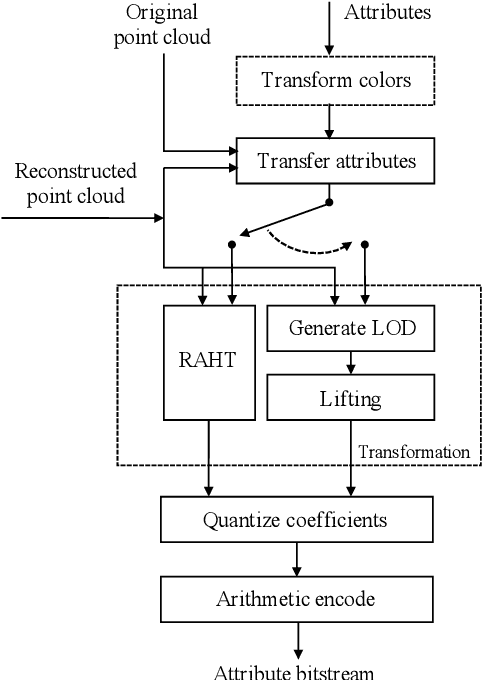
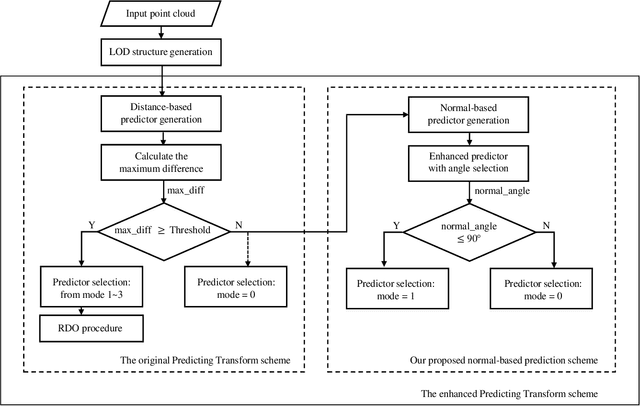
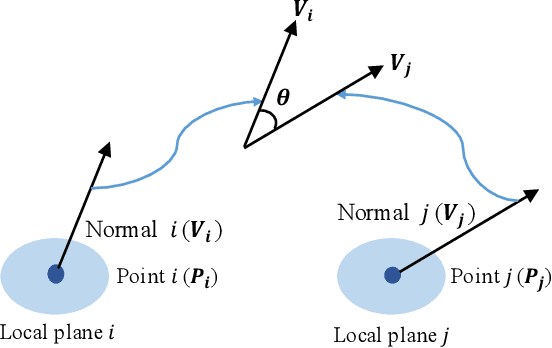
The sparse LiDAR point clouds become more and more popular in various applications, e.g., the autonomous driving. However, for this type of data, there exists much under-explored space in the corresponding compression framework proposed by MPEG, i.e., geometry-based point cloud compression (G-PCC). In G-PCC, only the distance-based similarity is considered in the intra prediction for the attribute compression. In this paper, we propose a normal-based intra prediction scheme, which provides a more efficient lossless attribute compression by introducing the normals of point clouds. The angle between normals is used to further explore accurate local similarity, which optimizes the selection of predictors. We implement our method into the G-PCC reference software. Experimental results over LiDAR acquired datasets demonstrate that our proposed method is able to deliver better compression performance than the G-PCC anchor, with $2.1\%$ gains on average for lossless attribute coding.
RAI-Net: Range-Adaptive LiDAR Point Cloud Frame Interpolation Network
Jun 01, 2021

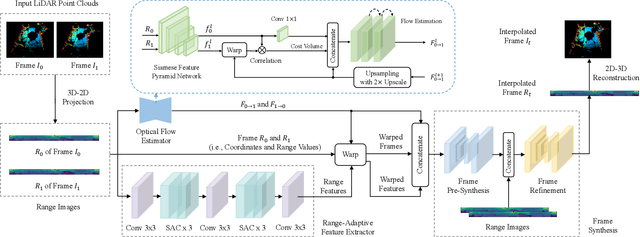
LiDAR point cloud frame interpolation, which synthesizes the intermediate frame between the captured frames, has emerged as an important issue for many applications. Especially for reducing the amounts of point cloud transmission, it is by predicting the intermediate frame based on the reference frames to upsample data to high frame rate ones. However, due to high-dimensional and sparse characteristics of point clouds, it is more difficult to predict the intermediate frame for LiDAR point clouds than videos. In this paper, we propose a novel LiDAR point cloud frame interpolation method, which exploits range images (RIs) as an intermediate representation with CNNs to conduct the frame interpolation process. Considering the inherited characteristics of RIs differ from that of color images, we introduce spatially adaptive convolutions to extract range features adaptively, while a high-efficient flow estimation method is presented to generate optical flows. The proposed model then warps the input frames and range features, based on the optical flows to synthesize the interpolated frame. Extensive experiments on the KITTI dataset have clearly demonstrated that our method consistently achieves superior frame interpolation results with better perceptual quality to that of using state-of-the-art video frame interpolation methods. The proposed method could be integrated into any LiDAR point cloud compression systems for inter prediction.