 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructural damage detection via hierarchical damage information with volumetric assessment
Jul 29, 2024



Image environments and noisy labels hinder deep learning-based inference models in structural damage detection. Post-detection, there is the challenge of reliance on manual assessments of detected damages. As a result, Guided-DetNet, characterized by Generative Attention Module (GAM), Hierarchical Elimination Algorithm (HEA), and Volumetric Contour Visual Assessment (VCVA), is proposed to mitigate complex image environments, noisy labeling, and post-detection manual assessment of structural damages. GAM leverages cross-horizontal and cross-vertical patch merging and cross foreground-background feature fusion to generate varied features to mitigate complex image environments. HEA addresses noisy labeling using hierarchical relationships among classes to refine instances given an image by eliminating unlikely class categories. VCVA assesses the severity of detected damages via volumetric representation and quantification leveraging the Dirac delta distribution. A comprehensive quantitative study, two robustness tests, and an application scenario based on the PEER Hub Image-Net dataset substantiate Guided-DetNet's promising performances. Guided-DetNet outperformed the best-compared models in a triple classification task by a difference of not less than 3% and not less than 2% in a dual detection task under varying metrics.
Learning Attributed Graph Representations with Communicative Message Passing Transformer
Jul 28, 2021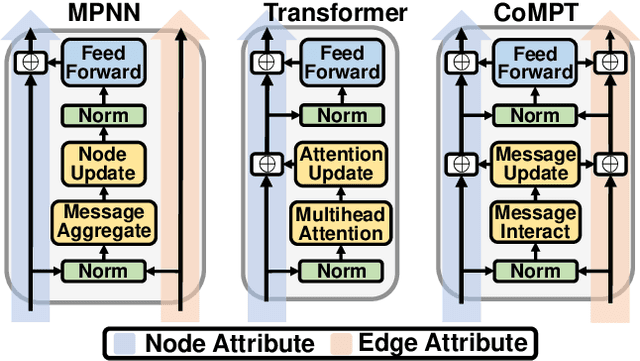
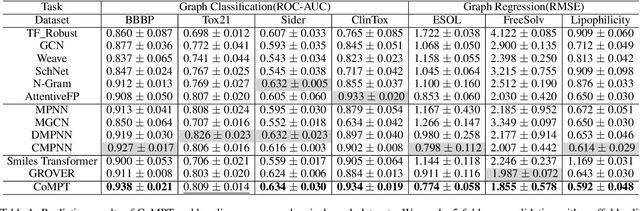
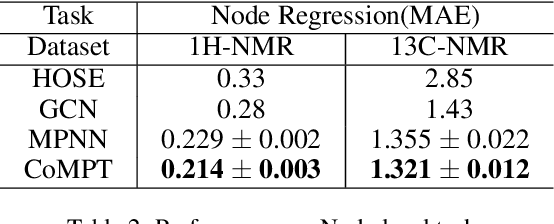
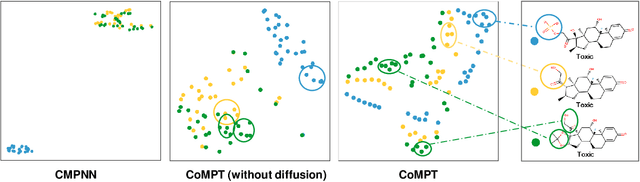
Constructing appropriate representations of molecules lies at the core of numerous tasks such as material science, chemistry and drug designs. Recent researches abstract molecules as attributed graphs and employ graph neural networks (GNN) for molecular representation learning, which have made remarkable achievements in molecular graph modeling. Albeit powerful, current models either are based on local aggregation operations and thus miss higher-order graph properties or focus on only node information without fully using the edge information. For this sake, we propose a Communicative Message Passing Transformer (CoMPT) neural network to improve the molecular graph representation by reinforcing message interactions between nodes and edges based on the Transformer architecture. Unlike the previous transformer-style GNNs that treat molecules as fully connected graphs, we introduce a message diffusion mechanism to leverage the graph connectivity inductive bias and reduce the message enrichment explosion. Extensive experiments demonstrated that the proposed model obtained superior performances (around 4$\%$ on average) against state-of-the-art baselines on seven chemical property datasets (graph-level tasks) and two chemical shift datasets (node-level tasks). Further visualization studies also indicated a better representation capacity achieved by our model.
Lossless Point Cloud Attribute Compression with Normal-based Intra Prediction
Jun 23, 2021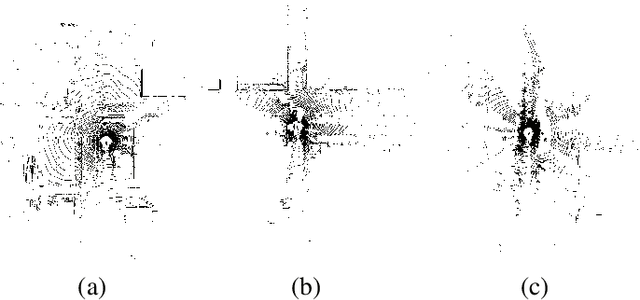
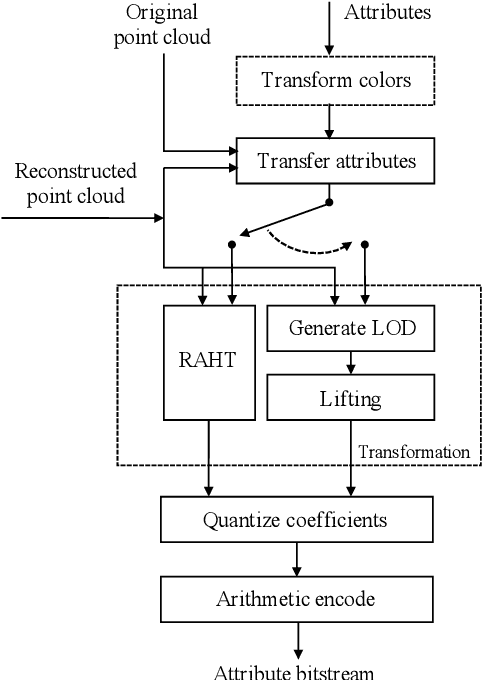
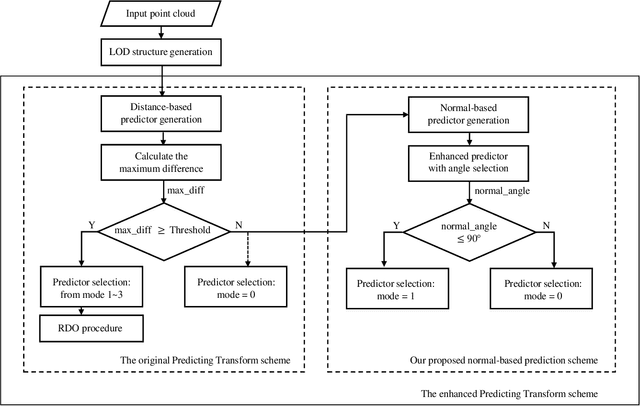
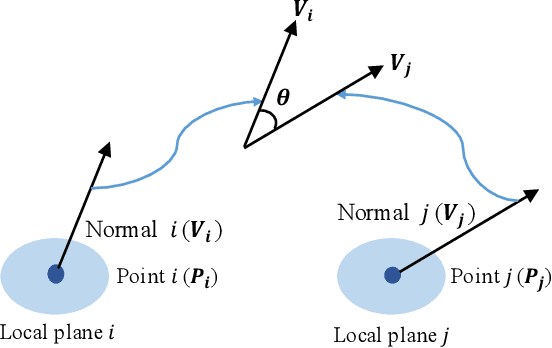
The sparse LiDAR point clouds become more and more popular in various applications, e.g., the autonomous driving. However, for this type of data, there exists much under-explored space in the corresponding compression framework proposed by MPEG, i.e., geometry-based point cloud compression (G-PCC). In G-PCC, only the distance-based similarity is considered in the intra prediction for the attribute compression. In this paper, we propose a normal-based intra prediction scheme, which provides a more efficient lossless attribute compression by introducing the normals of point clouds. The angle between normals is used to further explore accurate local similarity, which optimizes the selection of predictors. We implement our method into the G-PCC reference software. Experimental results over LiDAR acquired datasets demonstrate that our proposed method is able to deliver better compression performance than the G-PCC anchor, with $2.1\%$ gains on average for lossless attribute coding.
RAI-Net: Range-Adaptive LiDAR Point Cloud Frame Interpolation Network
Jun 01, 2021
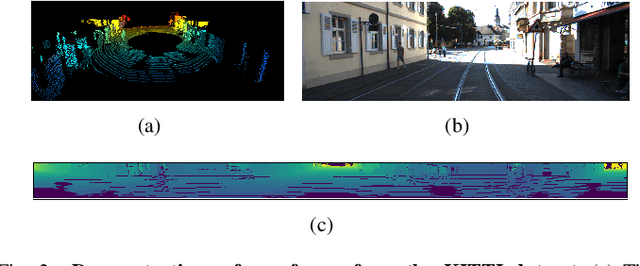

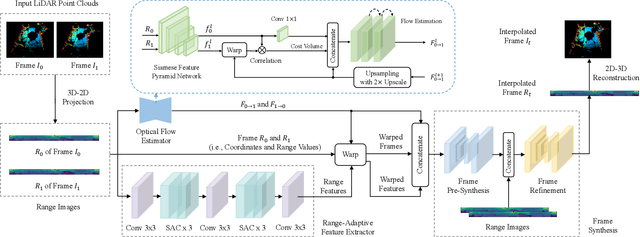
LiDAR point cloud frame interpolation, which synthesizes the intermediate frame between the captured frames, has emerged as an important issue for many applications. Especially for reducing the amounts of point cloud transmission, it is by predicting the intermediate frame based on the reference frames to upsample data to high frame rate ones. However, due to high-dimensional and sparse characteristics of point clouds, it is more difficult to predict the intermediate frame for LiDAR point clouds than videos. In this paper, we propose a novel LiDAR point cloud frame interpolation method, which exploits range images (RIs) as an intermediate representation with CNNs to conduct the frame interpolation process. Considering the inherited characteristics of RIs differ from that of color images, we introduce spatially adaptive convolutions to extract range features adaptively, while a high-efficient flow estimation method is presented to generate optical flows. The proposed model then warps the input frames and range features, based on the optical flows to synthesize the interpolated frame. Extensive experiments on the KITTI dataset have clearly demonstrated that our method consistently achieves superior frame interpolation results with better perceptual quality to that of using state-of-the-art video frame interpolation methods. The proposed method could be integrated into any LiDAR point cloud compression systems for inter prediction.
An Unsupervised Optical Flow Estimation For LiDAR Image Sequences
May 28, 2021
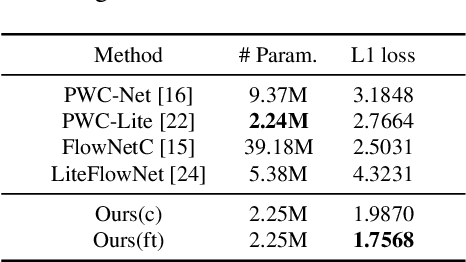

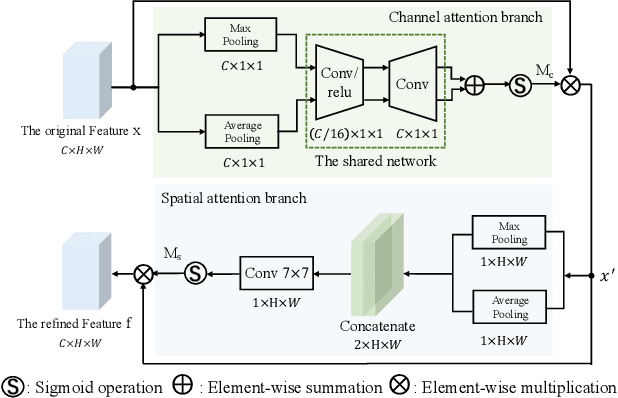
In recent years, the LiDAR images, as a 2D compact representation of 3D LiDAR point clouds, are widely applied in various tasks, e.g., 3D semantic segmentation, LiDAR point cloud compression (PCC). Among these works, the optical flow estimation for LiDAR image sequences has become a key issue, especially for the motion estimation of the inter prediction in PCC. However, the existing optical flow estimation models are likely to be unreliable for LiDAR images. In this work, we first propose a light-weight flow estimation model for LiDAR image sequences. The key novelty of our method lies in two aspects. One is that for the different characteristics (with the spatial-variation feature distribution) of the LiDAR images w.r.t. the normal color images, we introduce the attention mechanism into our model to improve the quality of the estimated flow. The other one is that to tackle the lack of large-scale LiDAR-image annotations, we present an unsupervised method, which directly minimizes the inconsistency between the reference image and the reconstructed image based on the estimated optical flow. Extensive experimental results have shown that our proposed model outperforms other mainstream models on the KITTI dataset, with much fewer parameters.