 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAW-Flow: Advancing RGB-to-RAW Image Reconstruction with Deterministic Latent Flow Matching
Jan 28, 2026RGB-to-RAW reconstruction, or the reverse modeling of a camera Image Signal Processing (ISP) pipeline, aims to recover high-fidelity RAW data from RGB images. Despite notable progress, existing learning-based methods typically treat this task as a direct regression objective and struggle with detail inconsistency and color deviation, due to the ill-posed nature of inverse ISP and the inherent information loss in quantized RGB images. To address these limitations, we pioneer a generative perspective by reformulating RGB-to-RAW reconstruction as a deterministic latent transport problem and introduce a novel framework named RAW-Flow, which leverages flow matching to learn a deterministic vector field in latent space, to effectively bridge the gap between RGB and RAW representations and enable accurate reconstruction of structural details and color information. To further enhance latent transport, we introduce a cross-scale context guidance module that injects hierarchical RGB features into the flow estimation process. Moreover, we design a dual-domain latent autoencoder with a feature alignment constraint to support the proposed latent transport framework, which jointly encodes RGB and RAW inputs while promoting stable training and high-fidelity reconstruction. Extensive experiments demonstrate that RAW-Flow outperforms state-of-the-art approaches both quantitatively and visually.
Multi-visual modality micro drone-based structural damage detection
Jan 15, 2025



Accurate detection and resilience of object detectors in structural damage detection are important in ensuring the continuous use of civil infrastructure. However, achieving robustness in object detectors remains a persistent challenge, impacting their ability to generalize effectively. This study proposes DetectorX, a robust framework for structural damage detection coupled with a micro drone. DetectorX addresses the challenges of object detector robustness by incorporating two innovative modules: a stem block and a spiral pooling technique. The stem block introduces a dynamic visual modality by leveraging the outputs of two Deep Convolutional Neural Network (DCNN) models. The framework employs the proposed event-based reward reinforcement learning to constrain the actions of a parent and child DCNN model leading to a reward. This results in the induction of two dynamic visual modalities alongside the Red, Green, and Blue (RGB) data. This enhancement significantly augments DetectorX's perception and adaptability in diverse environmental situations. Further, a spiral pooling technique, an online image augmentation method, strengthens the framework by increasing feature representations by concatenating spiraled and average/max pooled features. In three extensive experiments: (1) comparative and (2) robustness, which use the Pacific Earthquake Engineering Research Hub ImageNet dataset, and (3) field-experiment, DetectorX performed satisfactorily across varying metrics, including precision (0.88), recall (0.84), average precision (0.91), mean average precision (0.76), and mean average recall (0.73), compared to the competing detectors including You Only Look Once X-medium (YOLOX-m) and others. The study's findings indicate that DetectorX can provide satisfactory results and demonstrate resilience in challenging environments.
Structural damage detection via hierarchical damage information with volumetric assessment
Jul 29, 2024



Image environments and noisy labels hinder deep learning-based inference models in structural damage detection. Post-detection, there is the challenge of reliance on manual assessments of detected damages. As a result, Guided-DetNet, characterized by Generative Attention Module (GAM), Hierarchical Elimination Algorithm (HEA), and Volumetric Contour Visual Assessment (VCVA), is proposed to mitigate complex image environments, noisy labeling, and post-detection manual assessment of structural damages. GAM leverages cross-horizontal and cross-vertical patch merging and cross foreground-background feature fusion to generate varied features to mitigate complex image environments. HEA addresses noisy labeling using hierarchical relationships among classes to refine instances given an image by eliminating unlikely class categories. VCVA assesses the severity of detected damages via volumetric representation and quantification leveraging the Dirac delta distribution. A comprehensive quantitative study, two robustness tests, and an application scenario based on the PEER Hub Image-Net dataset substantiate Guided-DetNet's promising performances. Guided-DetNet outperformed the best-compared models in a triple classification task by a difference of not less than 3% and not less than 2% in a dual detection task under varying metrics.
CTooth+: A Large-scale Dental Cone Beam Computed Tomography Dataset and Benchmark for Tooth Volume Segmentation
Aug 02, 2022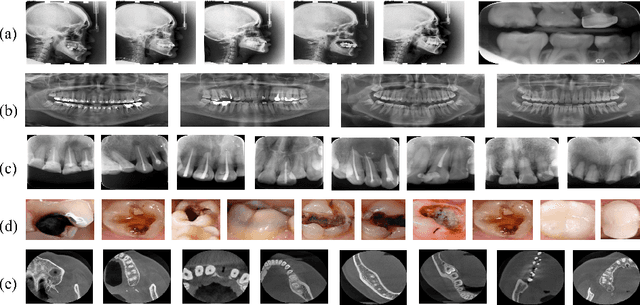
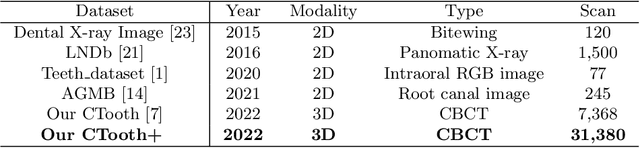
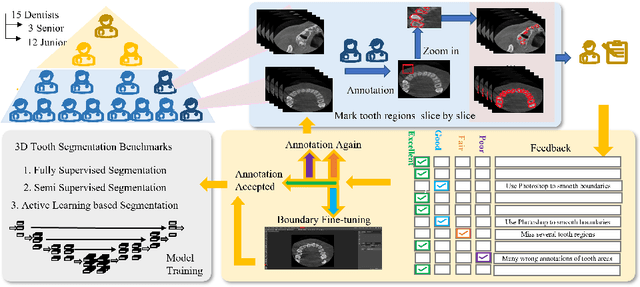
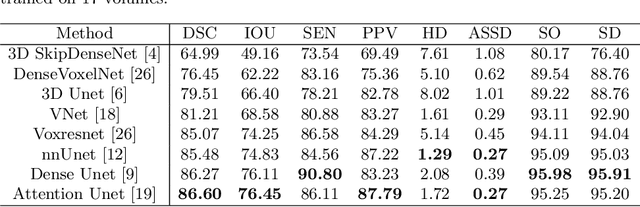
Accurate tooth volume segmentation is a prerequisite for computer-aided dental analysis. Deep learning-based tooth segmentation methods have achieved satisfying performances but require a large quantity of tooth data with ground truth. The dental data publicly available is limited meaning the existing methods can not be reproduced, evaluated and applied in clinical practice. In this paper, we establish a 3D dental CBCT dataset CTooth+, with 22 fully annotated volumes and 146 unlabeled volumes. We further evaluate several state-of-the-art tooth volume segmentation strategies based on fully-supervised learning, semi-supervised learning and active learning, and define the performance principles. This work provides a new benchmark for the tooth volume segmentation task, and the experiment can serve as the baseline for future AI-based dental imaging research and clinical application development.
CTooth: A Fully Annotated 3D Dataset and Benchmark for Tooth Volume Segmentation on Cone Beam Computed Tomography Images
Jun 17, 2022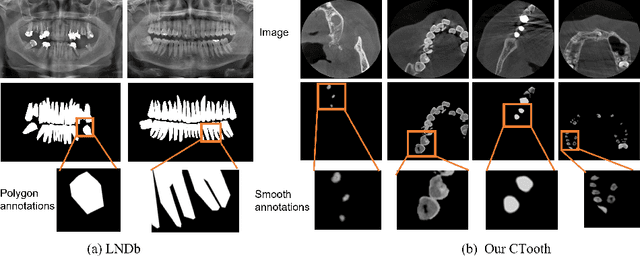
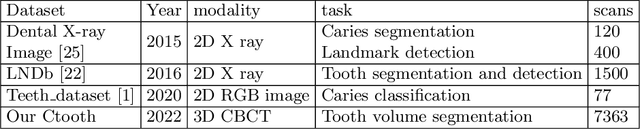
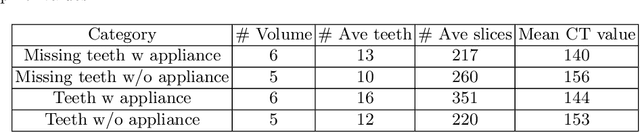
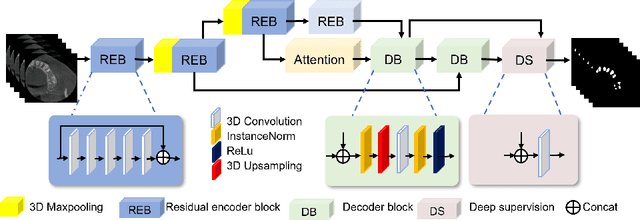
3D tooth segmentation is a prerequisite for computer-aided dental diagnosis and treatment. However, segmenting all tooth regions manually is subjective and time-consuming. Recently, deep learning-based segmentation methods produce convincing results and reduce manual annotation efforts, but it requires a large quantity of ground truth for training. To our knowledge, there are few tooth data available for the 3D segmentation study. In this paper, we establish a fully annotated cone beam computed tomography dataset CTooth with tooth gold standard. This dataset contains 22 volumes (7363 slices) with fine tooth labels annotated by experienced radiographic interpreters. To ensure a relative even data sampling distribution, data variance is included in the CTooth including missing teeth and dental restoration. Several state-of-the-art segmentation methods are evaluated on this dataset. Afterwards, we further summarise and apply a series of 3D attention-based Unet variants for segmenting tooth volumes. This work provides a new benchmark for the tooth volume segmentation task. Experimental evidence proves that attention modules of the 3D UNet structure boost responses in tooth areas and inhibit the influence of background and noise. The best performance is achieved by 3D Unet with SKNet attention module, of 88.04 \% Dice and 78.71 \% IOU, respectively. The attention-based Unet framework outperforms other state-of-the-art methods on the CTooth dataset. The codebase and dataset are released.