 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCTooth+: A Large-scale Dental Cone Beam Computed Tomography Dataset and Benchmark for Tooth Volume Segmentation
Aug 02, 2022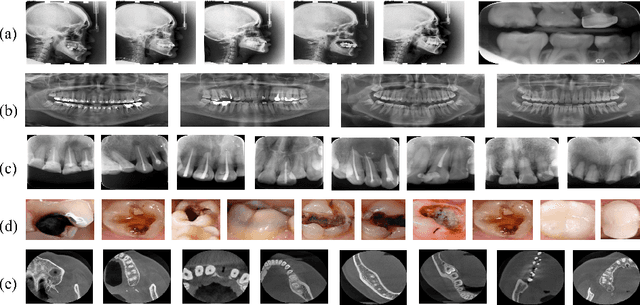
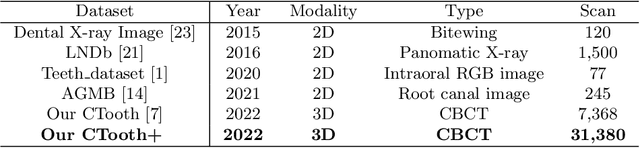
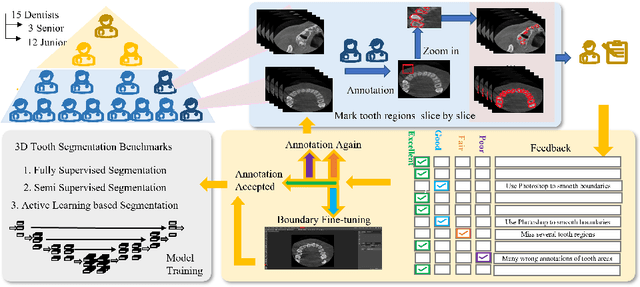
Accurate tooth volume segmentation is a prerequisite for computer-aided dental analysis. Deep learning-based tooth segmentation methods have achieved satisfying performances but require a large quantity of tooth data with ground truth. The dental data publicly available is limited meaning the existing methods can not be reproduced, evaluated and applied in clinical practice. In this paper, we establish a 3D dental CBCT dataset CTooth+, with 22 fully annotated volumes and 146 unlabeled volumes. We further evaluate several state-of-the-art tooth volume segmentation strategies based on fully-supervised learning, semi-supervised learning and active learning, and define the performance principles. This work provides a new benchmark for the tooth volume segmentation task, and the experiment can serve as the baseline for future AI-based dental imaging research and clinical application development.
CTooth: A Fully Annotated 3D Dataset and Benchmark for Tooth Volume Segmentation on Cone Beam Computed Tomography Images
Jun 17, 2022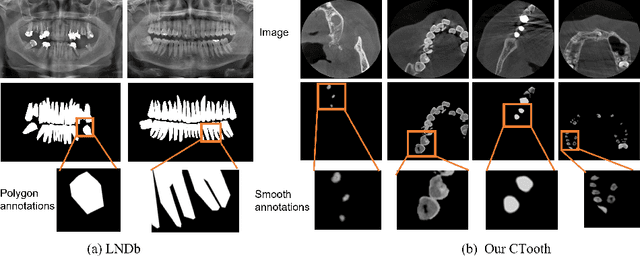
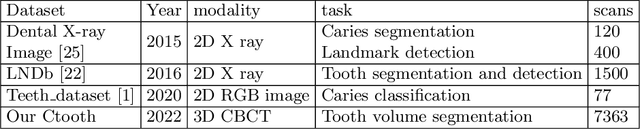
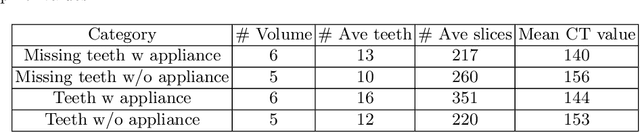
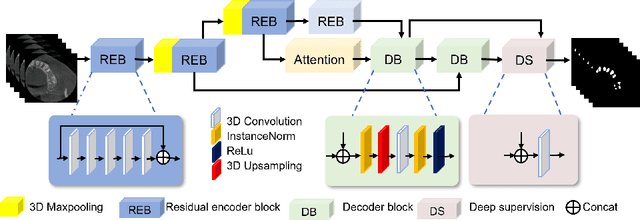
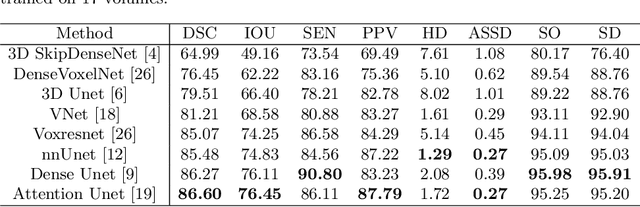
3D tooth segmentation is a prerequisite for computer-aided dental diagnosis and treatment. However, segmenting all tooth regions manually is subjective and time-consuming. Recently, deep learning-based segmentation methods produce convincing results and reduce manual annotation efforts, but it requires a large quantity of ground truth for training. To our knowledge, there are few tooth data available for the 3D segmentation study. In this paper, we establish a fully annotated cone beam computed tomography dataset CTooth with tooth gold standard. This dataset contains 22 volumes (7363 slices) with fine tooth labels annotated by experienced radiographic interpreters. To ensure a relative even data sampling distribution, data variance is included in the CTooth including missing teeth and dental restoration. Several state-of-the-art segmentation methods are evaluated on this dataset. Afterwards, we further summarise and apply a series of 3D attention-based Unet variants for segmenting tooth volumes. This work provides a new benchmark for the tooth volume segmentation task. Experimental evidence proves that attention modules of the 3D UNet structure boost responses in tooth areas and inhibit the influence of background and noise. The best performance is achieved by 3D Unet with SKNet attention module, of 88.04 \% Dice and 78.71 \% IOU, respectively. The attention-based Unet framework outperforms other state-of-the-art methods on the CTooth dataset. The codebase and dataset are released.