 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAI-Net: Range-Adaptive LiDAR Point Cloud Frame Interpolation Network
Jun 01, 2021
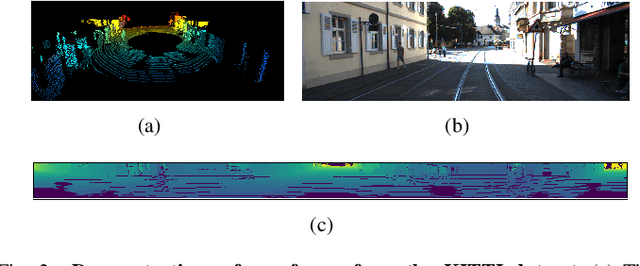

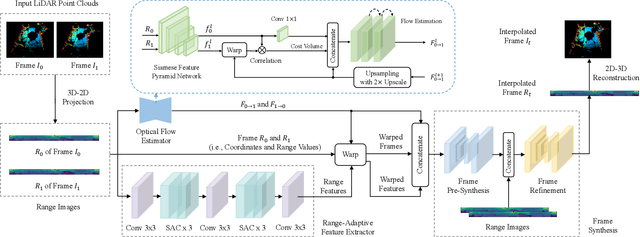
LiDAR point cloud frame interpolation, which synthesizes the intermediate frame between the captured frames, has emerged as an important issue for many applications. Especially for reducing the amounts of point cloud transmission, it is by predicting the intermediate frame based on the reference frames to upsample data to high frame rate ones. However, due to high-dimensional and sparse characteristics of point clouds, it is more difficult to predict the intermediate frame for LiDAR point clouds than videos. In this paper, we propose a novel LiDAR point cloud frame interpolation method, which exploits range images (RIs) as an intermediate representation with CNNs to conduct the frame interpolation process. Considering the inherited characteristics of RIs differ from that of color images, we introduce spatially adaptive convolutions to extract range features adaptively, while a high-efficient flow estimation method is presented to generate optical flows. The proposed model then warps the input frames and range features, based on the optical flows to synthesize the interpolated frame. Extensive experiments on the KITTI dataset have clearly demonstrated that our method consistently achieves superior frame interpolation results with better perceptual quality to that of using state-of-the-art video frame interpolation methods. The proposed method could be integrated into any LiDAR point cloud compression systems for inter prediction.
An Unsupervised Optical Flow Estimation For LiDAR Image Sequences
May 28, 2021
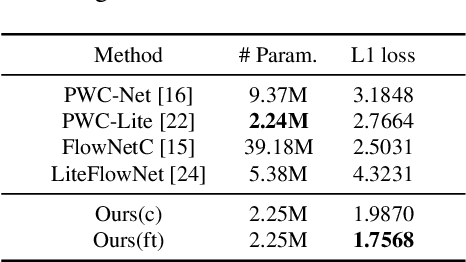

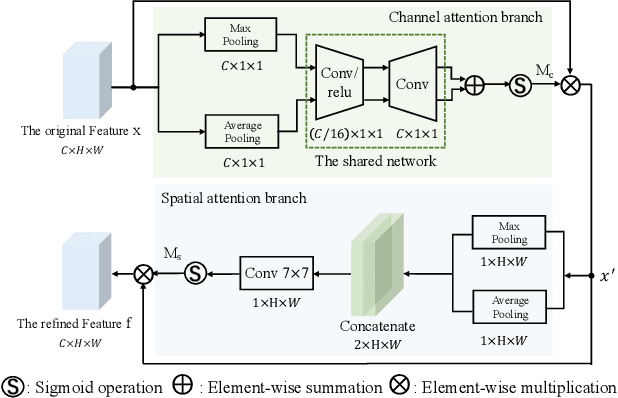
In recent years, the LiDAR images, as a 2D compact representation of 3D LiDAR point clouds, are widely applied in various tasks, e.g., 3D semantic segmentation, LiDAR point cloud compression (PCC). Among these works, the optical flow estimation for LiDAR image sequences has become a key issue, especially for the motion estimation of the inter prediction in PCC. However, the existing optical flow estimation models are likely to be unreliable for LiDAR images. In this work, we first propose a light-weight flow estimation model for LiDAR image sequences. The key novelty of our method lies in two aspects. One is that for the different characteristics (with the spatial-variation feature distribution) of the LiDAR images w.r.t. the normal color images, we introduce the attention mechanism into our model to improve the quality of the estimated flow. The other one is that to tackle the lack of large-scale LiDAR-image annotations, we present an unsupervised method, which directly minimizes the inconsistency between the reference image and the reconstructed image based on the estimated optical flow. Extensive experimental results have shown that our proposed model outperforms other mainstream models on the KITTI dataset, with much fewer parameters.