 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVC-Soup: Value-Consistency Guided Multi-Value Alignment for Large Language Models
Mar 18, 2026As large language models (LLMs) increasingly shape content generation, interaction, and decision-making across the Web, aligning them with human values has become a central objective in trustworthy AI. This challenge becomes even more pronounced when aligning multiple, potentially conflicting human values. Although recent approaches, such as reward reweighting, prompt-based supervised fine-tuning, and model merging, attempt to tackle multi-value alignment, they still face two major limitations: (1) training separate models for each value combination is prohibitively expensive; (2) value conflicts substantially degrade alignment performance. These limitations make it difficult to achieve favorable trade-offs across diverse human values. To address these challenges, we revisit multi-value alignment from the perspective of value consistency in data and propose VC-soup, a data filtering and parameter merging framework grounded in value-consistent learning. We first design a value consistency metric based on the cosine similarity between the reward-gap vector of each preference pair and an all-ones vector, which quantifies its cross-value coherence. We then filter out low-consistency preference pairs in each value dataset and train on the remaining data to obtain smooth, value-consistent policy models that better preserve linear mode connectivity. Finally, we linearly combine these policies and apply Pareto filtering across values to obtain solutions with balanced multi-value performance. Extensive experiments and theoretical analysis demonstrate that VC-soup effectively mitigates conflicts and consistently outperforms existing multi-value alignment methods.
BookNet: Book Image Rectification via Cross-Page Attention Network
Jan 29, 2026Book image rectification presents unique challenges in document image processing due to complex geometric distortions from binding constraints, where left and right pages exhibit distinctly asymmetric curvature patterns. However, existing single-page document image rectification methods fail to capture the coupled geometric relationships between adjacent pages in books. In this work, we introduce BookNet, the first end-to-end deep learning framework specifically designed for dual-page book image rectification. BookNet adopts a dual-branch architecture with cross-page attention mechanisms, enabling it to estimate warping flows for both individual pages and the complete book spread, explicitly modeling how left and right pages influence each other. Moreover, to address the absence of specialized datasets, we present Book3D, a large-scale synthetic dataset for training, and Book100, a comprehensive real-world benchmark for evaluation. Extensive experiments demonstrate that BookNet outperforms existing state-of-the-art methods on book image rectification. Code and dataset will be made publicly available.
From Atom to Community: Structured and Evolving Agent Memory for User Behavior Modeling
Jan 26, 2026User behavior modeling lies at the heart of personalized applications like recommender systems. With LLM-based agents, user preference representation has evolved from latent embeddings to semantic memory. While existing memory mechanisms show promise in textual dialogues, modeling non-textual behaviors remains challenging, as preferences must be inferred from implicit signals like clicks without ground truth supervision. Current approaches rely on a single unstructured summary, updated through simple overwriting. However, this is suboptimal: users exhibit multi-faceted interests that get conflated, preferences evolve yet naive overwriting causes forgetting, and sparse individual interactions necessitate collaborative signals. We present STEAM (\textit{\textbf{ST}ructured and \textbf{E}volving \textbf{A}gent \textbf{M}emory}), a novel framework that reimagines how agent memory is organized and updated. STEAM decomposes preferences into atomic memory units, each capturing a distinct interest dimension with explicit links to observed behaviors. To exploit collaborative patterns, STEAM organizes similar memories across users into communities and generates prototype memories for signal propagation. The framework further incorporates adaptive evolution mechanisms, including consolidation for refining memories and formation for capturing emerging interests. Experiments on three real-world datasets demonstrate that STEAM substantially outperforms state-of-the-art baselines in recommendation accuracy, simulation fidelity, and diversity.
Mitigating Recommendation Biases via Group-Alignment and Global-Uniformity in Representation Learning
Nov 17, 2025Collaborative Filtering~(CF) plays a crucial role in modern recommender systems, leveraging historical user-item interactions to provide personalized suggestions. However, CF-based methods often encounter biases due to imbalances in training data. This phenomenon makes CF-based methods tend to prioritize recommending popular items and performing unsatisfactorily on inactive users. Existing works address this issue by rebalancing training samples, reranking recommendation results, or making the modeling process robust to the bias. Despite their effectiveness, these approaches can compromise accuracy or be sensitive to weighting strategies, making them challenging to train. In this paper, we deeply analyze the causes and effects of the biases and propose a framework to alleviate biases in recommendation from the perspective of representation distribution, namely Group-Alignment and Global-Uniformity Enhanced Representation Learning for Debiasing Recommendation (AURL). Specifically, we identify two significant problems in the representation distribution of users and items, namely group-discrepancy and global-collapse. These two problems directly lead to biases in the recommendation results. To this end, we propose two simple but effective regularizers in the representation space, respectively named group-alignment and global-uniformity. The goal of group-alignment is to bring the representation distribution of long-tail entities closer to that of popular entities, while global-uniformity aims to preserve the information of entities as much as possible by evenly distributing representations. Our method directly optimizes both the group-alignment and global-uniformity regularization terms to mitigate recommendation biases. Extensive experiments on three real datasets and various recommendation backbones verify the superiority of our proposed framework.
A Survey on Generative Recommendation: Data, Model, and Tasks
Oct 31, 2025Recommender systems serve as foundational infrastructure in modern information ecosystems, helping users navigate digital content and discover items aligned with their preferences. At their core, recommender systems address a fundamental problem: matching users with items. Over the past decades, the field has experienced successive paradigm shifts, from collaborative filtering and matrix factorization in the machine learning era to neural architectures in the deep learning era. Recently, the emergence of generative models, especially large language models (LLMs) and diffusion models, have sparked a new paradigm: generative recommendation, which reconceptualizes recommendation as a generation task rather than discriminative scoring. This survey provides a comprehensive examination through a unified tripartite framework spanning data, model, and task dimensions. Rather than simply categorizing works, we systematically decompose approaches into operational stages-data augmentation and unification, model alignment and training, task formulation and execution. At the data level, generative models enable knowledge-infused augmentation and agent-based simulation while unifying heterogeneous signals. At the model level, we taxonomize LLM-based methods, large recommendation models, and diffusion approaches, analyzing their alignment mechanisms and innovations. At the task level, we illuminate new capabilities including conversational interaction, explainable reasoning, and personalized content generation. We identify five key advantages: world knowledge integration, natural language understanding, reasoning capabilities, scaling laws, and creative generation. We critically examine challenges in benchmark design, model robustness, and deployment efficiency, while charting a roadmap toward intelligent recommendation assistants that fundamentally reshape human-information interaction.
WeaveRec: An LLM-Based Cross-Domain Sequential Recommendation Framework with Model Merging
Oct 30, 2025



Cross-Domain Sequential Recommendation (CDSR) seeks to improve user preference modeling by transferring knowledge from multiple domains. Despite the progress made in CDSR, most existing methods rely on overlapping users or items to establish cross-domain correlations-a requirement that rarely holds in real-world settings. The advent of large language models (LLM) and model-merging techniques appears to overcome this limitation by unifying multi-domain data without explicit overlaps. Yet, our empirical study shows that naively training an LLM on combined domains-or simply merging several domain-specific LLMs-often degrades performance relative to a model trained solely on the target domain. To address these challenges, we first experimentally investigate the cause of suboptimal performance in LLM-based cross-domain recommendation and model merging. Building on these insights, we introduce WeaveRec, which cross-trains multiple LoRA modules with source and target domain data in a weaving fashion, and fuses them via model merging. WeaveRec can be extended to multi-source domain scenarios and notably does not introduce additional inference-time cost in terms of latency or memory. Furthermore, we provide a theoretical guarantee that WeaveRec can reduce the upper bound of the expected error in the target domain. Extensive experiments on single-source, multi-source, and cross-platform cross-domain recommendation scenarios validate that WeaveRec effectively mitigates performance degradation and consistently outperforms baseline approaches in real-world recommendation tasks.
TarDiff: Target-Oriented Diffusion Guidance for Synthetic Electronic Health Record Time Series Generation
Apr 24, 2025Synthetic Electronic Health Record (EHR) time-series generation is crucial for advancing clinical machine learning models, as it helps address data scarcity by providing more training data. However, most existing approaches focus primarily on replicating statistical distributions and temporal dependencies of real-world data. We argue that fidelity to observed data alone does not guarantee better model performance, as common patterns may dominate, limiting the representation of rare but important conditions. This highlights the need for generate synthetic samples to improve performance of specific clinical models to fulfill their target outcomes. To address this, we propose TarDiff, a novel target-oriented diffusion framework that integrates task-specific influence guidance into the synthetic data generation process. Unlike conventional approaches that mimic training data distributions, TarDiff optimizes synthetic samples by quantifying their expected contribution to improving downstream model performance through influence functions. Specifically, we measure the reduction in task-specific loss induced by synthetic samples and embed this influence gradient into the reverse diffusion process, thereby steering the generation towards utility-optimized data. Evaluated on six publicly available EHR datasets, TarDiff achieves state-of-the-art performance, outperforming existing methods by up to 20.4% in AUPRC and 18.4% in AUROC. Our results demonstrate that TarDiff not only preserves temporal fidelity but also enhances downstream model performance, offering a robust solution to data scarcity and class imbalance in healthcare analytics.
MiMu: Mitigating Multiple Shortcut Learning Behavior of Transformers
Apr 14, 2025Empirical Risk Minimization (ERM) models often rely on spurious correlations between features and labels during the learning process, leading to shortcut learning behavior that undermines robustness generalization performance. Current research mainly targets identifying or mitigating a single shortcut; however, in real-world scenarios, cues within the data are diverse and unknown. In empirical studies, we reveal that the models rely to varying extents on different shortcuts. Compared to weak shortcuts, models depend more heavily on strong shortcuts, resulting in their poor generalization ability. To address these challenges, we propose MiMu, a novel method integrated with Transformer-based ERMs designed to Mitigate Multiple shortcut learning behavior, which incorporates self-calibration strategy and self-improvement strategy. In the source model, we preliminarily propose the self-calibration strategy to prevent the model from relying on shortcuts and make overconfident predictions. Then, we further design self-improvement strategy in target model to reduce the reliance on multiple shortcuts. The random mask strategy involves randomly masking partial attention positions to diversify the focus of target model other than concentrating on a fixed region. Meanwhile, the adaptive attention alignment module facilitates the alignment of attention weights to the calibrated source model, without the need for post-hoc attention maps or supervision. Finally, extensive experiments conducted on Natural Language Processing (NLP) and Computer Vision (CV) demonstrate the effectiveness of MiMu in improving robustness generalization abilities.
MoLoRec: A Generalizable and Efficient Framework for LLM-Based Recommendation
Feb 12, 2025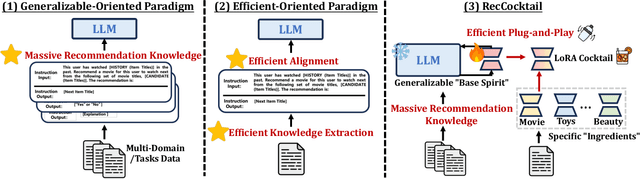
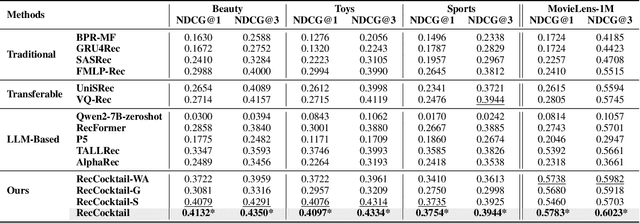
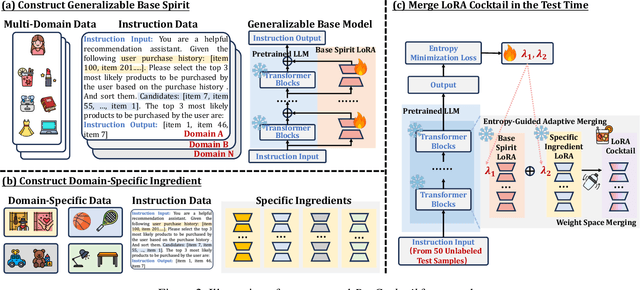
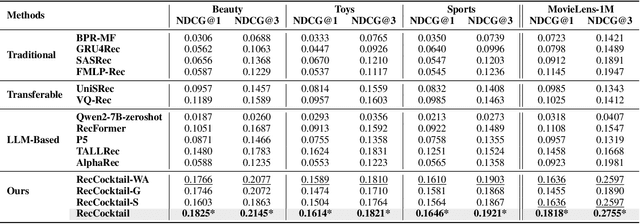
Large Language Models (LLMs) have achieved remarkable success in recent years, owing to their impressive generalization capabilities and rich world knowledge. To capitalize on the potential of using LLMs as recommender systems, mainstream approaches typically focus on two paradigms. The first paradigm designs multi-domain or multi-task instruction data for generalizable recommendation, so as to align LLMs with general recommendation areas and deal with cold-start recommendation. The second paradigm enhances domain-specific recommendation tasks with parameter-efficient fine-tuning techniques, in order to improve models under the warm recommendation scenarios. While most previous works treat these two paradigms separately, we argue that they have complementary advantages, and combining them together would be helpful. To that end, in this paper, we propose a generalizable and efficient LLM-based recommendation framework MoLoRec. Our approach starts by parameter-efficient fine-tuning a domain-general module with general recommendation instruction data, to align LLM with recommendation knowledge. Then, given users' behavior of a specific domain, we construct a domain-specific instruction dataset and apply efficient fine-tuning to the pre-trained LLM. After that, we provide approaches to integrate the above domain-general part and domain-specific part with parameters mixture. Please note that, MoLoRec is efficient with plug and play, as the domain-general module is trained only once, and any domain-specific plug-in can be efficiently merged with only domain-specific fine-tuning. Extensive experiments on multiple datasets under both warm and cold-start recommendation scenarios validate the effectiveness and generality of the proposed MoLoRec.
InvDiff: Invariant Guidance for Bias Mitigation in Diffusion Models
Dec 11, 2024



As one of the most successful generative models, diffusion models have demonstrated remarkable efficacy in synthesizing high-quality images. These models learn the underlying high-dimensional data distribution in an unsupervised manner. Despite their success, diffusion models are highly data-driven and prone to inheriting the imbalances and biases present in real-world data. Some studies have attempted to address these issues by designing text prompts for known biases or using bias labels to construct unbiased data. While these methods have shown improved results, real-world scenarios often contain various unknown biases, and obtaining bias labels is particularly challenging. In this paper, we emphasize the necessity of mitigating bias in pre-trained diffusion models without relying on auxiliary bias annotations. To tackle this problem, we propose a framework, InvDiff, which aims to learn invariant semantic information for diffusion guidance. Specifically, we propose identifying underlying biases in the training data and designing a novel debiasing training objective. Then, we employ a lightweight trainable module that automatically preserves invariant semantic information and uses it to guide the diffusion model's sampling process toward unbiased outcomes simultaneously. Notably, we only need to learn a small number of parameters in the lightweight learnable module without altering the pre-trained diffusion model. Furthermore, we provide a theoretical guarantee that the implementation of InvDiff is equivalent to reducing the error upper bound of generalization. Extensive experimental results on three publicly available benchmarks demonstrate that InvDiff effectively reduces biases while maintaining the quality of image generation. Our code is available at https://github.com/Hundredl/InvDiff.