 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning LLMs through Multi-perspective User Preference Ranking-based Feedback for Programming Question Answering
May 27, 2024
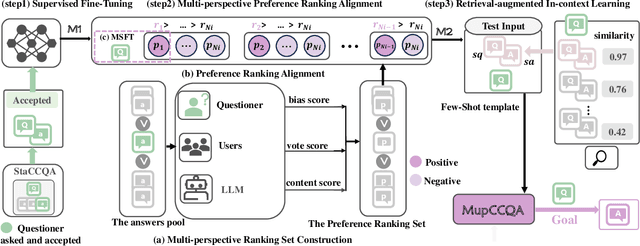
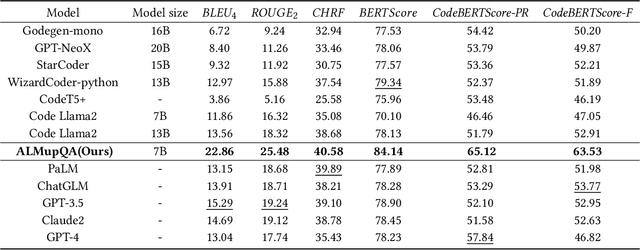
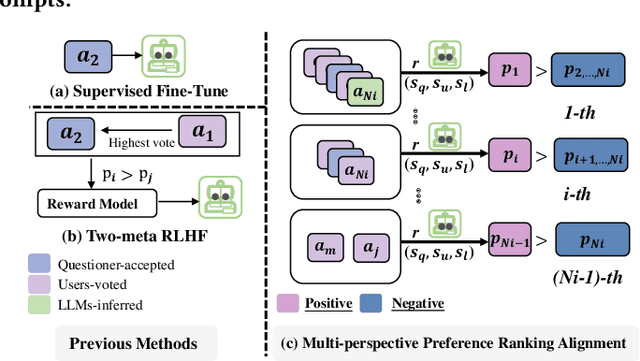
Code Community Question Answering (CCQA) seeks to tackle programming-related issues, thereby boosting productivity in both software engineering and academic research. Recent advancements in Reinforcement Learning from Human Feedback (RLHF) have transformed the fine-tuning process of Large Language Models (LLMs) to produce responses that closely mimic human behavior. Leveraging LLMs with RLHF for practical CCQA applications has thus emerged as a promising area of study. Unlike standard code question-answering tasks, CCQA involves multiple possible answers, with varying user preferences for each response. Additionally, code communities often show a preference for new APIs. These challenges prevent LLMs from generating responses that cater to the diverse preferences of users in CCQA tasks. To address these issues, we propose a novel framework called Aligning LLMs through Multi-perspective User Preference Ranking-based Feedback for Programming Question Answering (ALMupQA) to create user-focused responses. Our approach starts with Multi-perspective Preference Ranking Alignment (MPRA), which synthesizes varied user preferences based on the characteristics of answers from code communities. We then introduce a Retrieval-augmented In-context Learning (RIL) module to mitigate the problem of outdated answers by retrieving responses to similar questions from a question bank. Due to the limited availability of high-quality, multi-answer CCQA datasets, we also developed a dataset named StaCCQA from real code communities. Extensive experiments demonstrated the effectiveness of the ALMupQA framework in terms of accuracy and user preference. Compared to the base model, ALMupQA showed nearly an 11% improvement in BLEU, with increases of 20% and 17.5% in BERTScore and CodeBERTScore, respectively.
PND-Net: Physics based Non-local Dual-domain Network for Metal Artifact Reduction
May 28, 2023



Metal artifacts caused by the presence of metallic implants tremendously degrade the reconstructed computed tomography (CT) image quality, affecting clinical diagnosis or reducing the accuracy of organ delineation and dose calculation in radiotherapy. Recently, deep learning methods in sinogram and image domains have been rapidly applied on metal artifact reduction (MAR) task. The supervised dual-domain methods perform well on synthesized data, while unsupervised methods with unpaired data are more generalized on clinical data. However, most existing methods intend to restore the corrupted sinogram within metal trace, which essentially remove beam hardening artifacts but ignore other components of metal artifacts, such as scatter, non-linear partial volume effect and noise. In this paper, we mathematically derive a physical property of metal artifacts which is verified via Monte Carlo (MC) simulation and propose a novel physics based non-local dual-domain network (PND-Net) for MAR in CT imaging. Specifically, we design a novel non-local sinogram decomposition network (NSD-Net) to acquire the weighted artifact component, and an image restoration network (IR-Net) is proposed to reduce the residual and secondary artifacts in the image domain. To facilitate the generalization and robustness of our method on clinical CT images, we employ a trainable fusion network (F-Net) in the artifact synthesis path to achieve unpaired learning. Furthermore, we design an internal consistency loss to ensure the integrity of anatomical structures in the image domain, and introduce the linear interpolation sinogram as prior knowledge to guide sinogram decomposition. Extensive experiments on simulation and clinical data demonstrate that our method outperforms the state-of-the-art MAR methods.
Jamming Modulation: An Active Anti-Jamming Scheme
Sep 05, 2022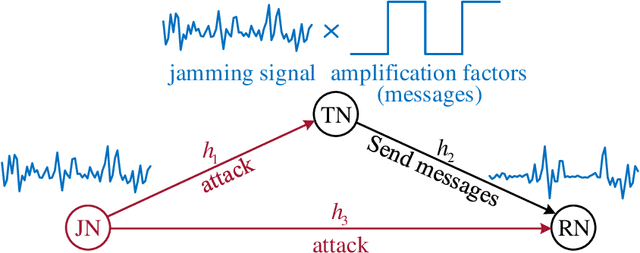
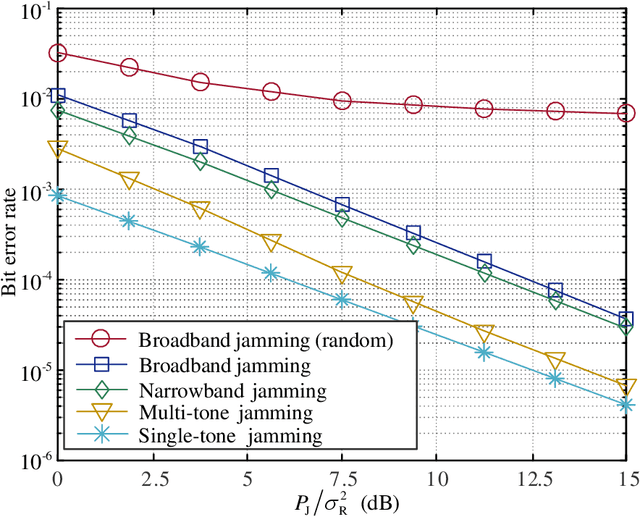
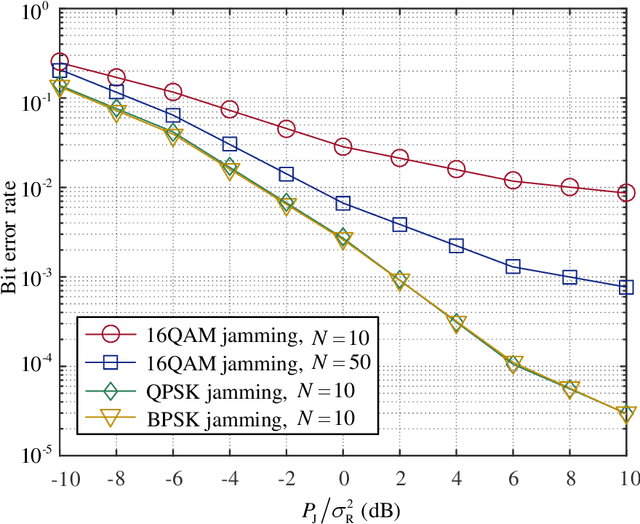
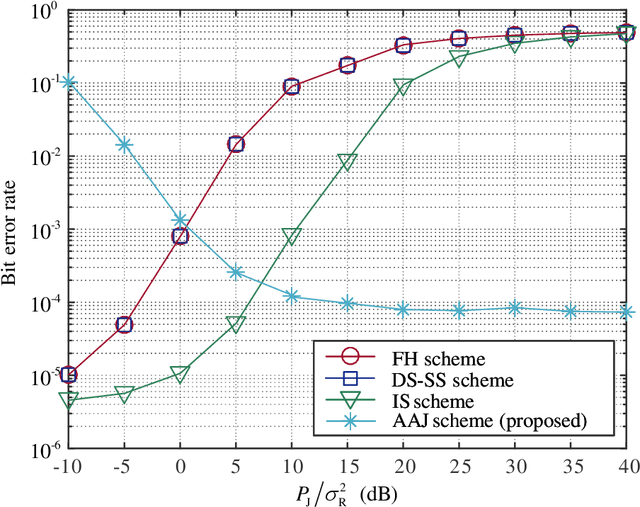
Providing quality communications under adversarial electronic attacks, e.g., broadband jamming attacks, is a challenging task. Unlike state-of-the-art approaches which treat jamming signals as destructive interference, this paper presents a novel active anti-jamming (AAJ) scheme for a jammed channel to enhance the communication quality between a transmitter node (TN) and receiver node (RN), where the TN actively exploits the jamming signal as a carrier to send messages. Specifically, the TN is equipped with a programmable-gain amplifier, which is capable of re-modulating the jamming signals for jamming modulation. Considering four typical jamming types, we derive both the bit error rates (BER) and the corresponding optimal detection thresholds of the AAJ scheme. The asymptotic performances of the AAJ scheme are discussed under the high jamming-to-noise ratio (JNR) and sampling rate cases. Our analysis shows that there exists a BER floor for sufficiently large JNR. Simulation results indicate that the proposed AAJ scheme allows the TN to communicate with the RN reliably even under extremely strong and/or broadband jamming. Additionally, we investigate the channel capacity of the proposed AAJ scheme and show that the channel capacity of the AAJ scheme outperforms that of the direct transmission when the JNR is relatively high.
Preference Enhanced Social Influence Modeling for Network-Aware Cascade Prediction
Apr 18, 2022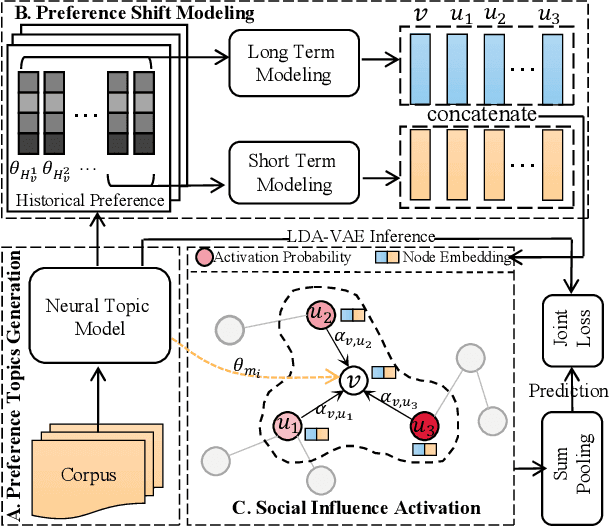
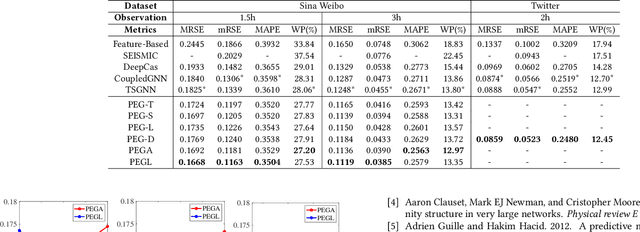
Network-aware cascade size prediction aims to predict the final reposted number of user-generated information via modeling the propagation process in social networks. Estimating the user's reposting probability by social influence, namely state activation plays an important role in the information diffusion process. Therefore, Graph Neural Networks (GNN), which can simulate the information interaction between nodes, has been proved as an effective scheme to handle this prediction task. However, existing studies including GNN-based models usually neglect a vital factor of user's preference which influences the state activation deeply. To that end, we propose a novel framework to promote cascade size prediction by enhancing the user preference modeling according to three stages, i.e., preference topics generation, preference shift modeling, and social influence activation. Our end-to-end method makes the user activating process of information diffusion more adaptive and accurate. Extensive experiments on two large-scale real-world datasets have clearly demonstrated the effectiveness of our proposed model compared to state-of-the-art baselines.
SIFN: A Sentiment-aware Interactive Fusion Network for Review-based Item Recommendation
Aug 18, 2021
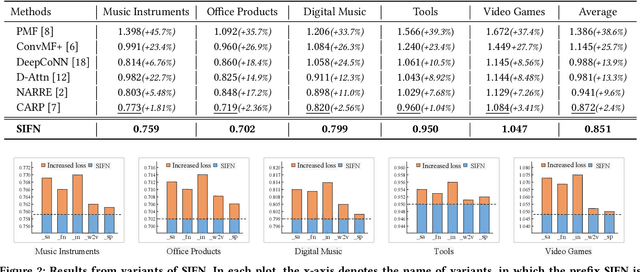
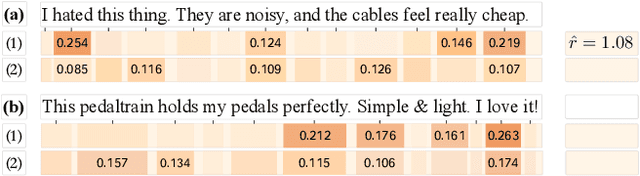
Recent studies in recommender systems have managed to achieve significantly improved performance by leveraging reviews for rating prediction. However, despite being extensively studied, these methods still suffer from some limitations. First, previous studies either encode the document or extract latent sentiment via neural networks, which are difficult to interpret the sentiment of reviewers intuitively. Second, they neglect the personalized interaction of reviews with user/item, i.e., each review has different contributions when modeling the sentiment preference of user/item. To remedy these issues, we propose a Sentiment-aware Interactive Fusion Network (SIFN) for review-based item recommendation. Specifically, we first encode user/item reviews via BERT and propose a light-weighted sentiment learner to extract semantic features of each review. Then, we propose a sentiment prediction task that guides the sentiment learner to extract sentiment-aware features via explicit sentiment labels. Finally, we design a rating prediction task that contains a rating learner with an interactive and fusion module to fuse the identity (i.e., user and item ID) and each review representation so that various interactive features can synergistically influence the final rating score. Experimental results on five real-world datasets demonstrate that the proposed model is superior to state-of-the-art models.
Multi-Interactive Attention Network for Fine-grained Feature Learning in CTR Prediction
Dec 13, 2020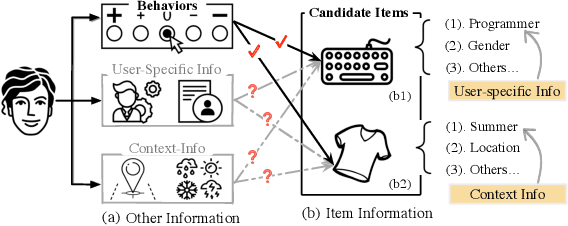
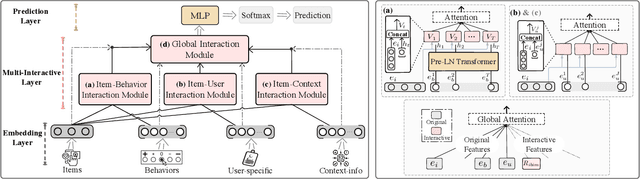
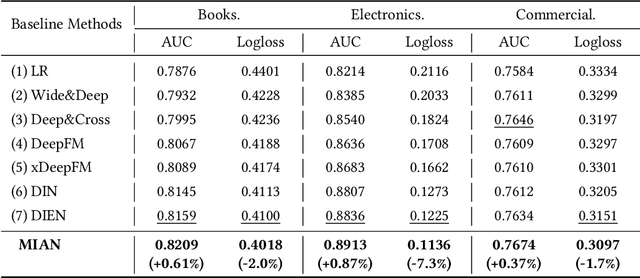
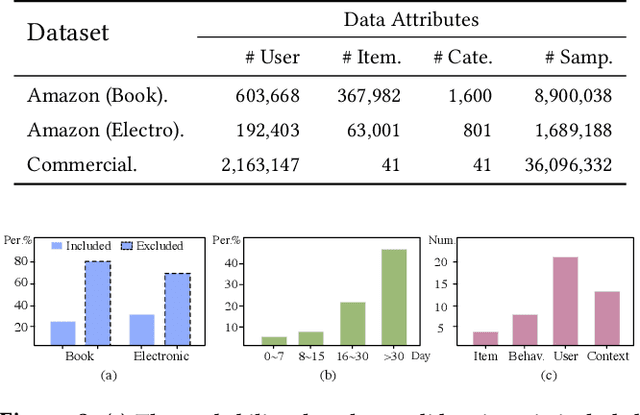
In the Click-Through Rate (CTR) prediction scenario, user's sequential behaviors are well utilized to capture the user interest in the recent literature. However, despite being extensively studied, these sequential methods still suffer from three limitations. First, existing methods mostly utilize attention on the behavior of users, which is not always suitable for CTR prediction, because users often click on new products that are irrelevant to any historical behaviors. Second, in the real scenario, there exist numerous users that have operations a long time ago, but turn relatively inactive in recent times. Thus, it is hard to precisely capture user's current preferences through early behaviors. Third, multiple representations of user's historical behaviors in different feature subspaces are largely ignored. To remedy these issues, we propose a Multi-Interactive Attention Network (MIAN) to comprehensively extract the latent relationship among all kinds of fine-grained features (e.g., gender, age and occupation in user-profile). Specifically, MIAN contains a Multi-Interactive Layer (MIL) that integrates three local interaction modules to capture multiple representations of user preference through sequential behaviors and simultaneously utilize the fine-grained user-specific as well as context information. In addition, we design a Global Interaction Module (GIM) to learn the high-order interactions and balance the different impacts of multiple features. Finally, Offline experiment results from three datasets, together with an Online A/B test in a large-scale recommendation system, demonstrate the effectiveness of our proposed approach.
Sampling-Decomposable Generative Adversarial Recommender
Nov 02, 2020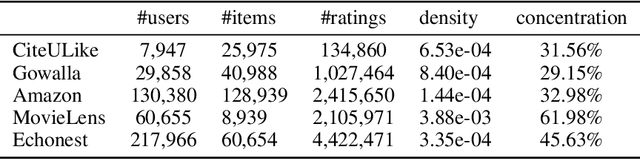
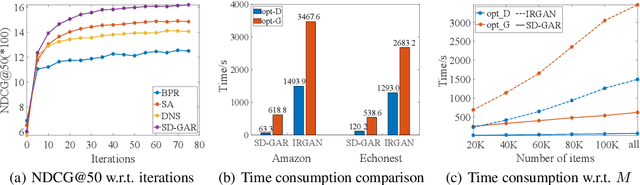
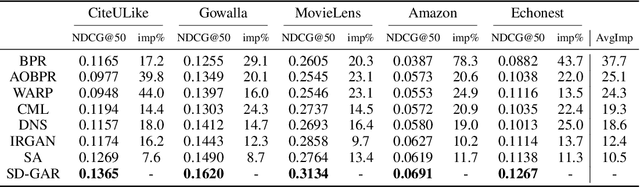
Recommendation techniques are important approaches for alleviating information overload. Being often trained on implicit user feedback, many recommenders suffer from the sparsity challenge due to the lack of explicitly negative samples. The GAN-style recommenders (i.e., IRGAN) addresses the challenge by learning a generator and a discriminator adversarially, such that the generator produces increasingly difficult samples for the discriminator to accelerate optimizing the discrimination objective. However, producing samples from the generator is very time-consuming, and our empirical study shows that the discriminator performs poor in top-k item recommendation. To this end, a theoretical analysis is made for the GAN-style algorithms, showing that the generator of limit capacity is diverged from the optimal generator. This may interpret the limitation of discriminator's performance. Based on these findings, we propose a Sampling-Decomposable Generative Adversarial Recommender (SD-GAR). In the framework, the divergence between some generator and the optimum is compensated by self-normalized importance sampling; the efficiency of sample generation is improved with a sampling-decomposable generator, such that each sample can be generated in O(1) with the Vose-Alias method. Interestingly, due to decomposability of sampling, the generator can be optimized with the closed-form solutions in an alternating manner, being different from policy gradient in the GAN-style algorithms. We extensively evaluate the proposed algorithm with five real-world recommendation datasets. The results show that SD-GAR outperforms IRGAN by 12.4% and the SOTA recommender by 10% on average. Moreover, discriminator training can be 20x faster on the dataset with more than 120K items.
Deep Technology Tracing for High-tech Companies
Jan 02, 2020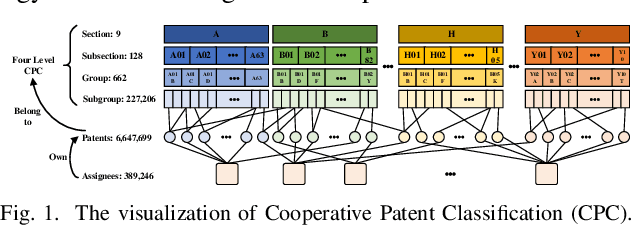
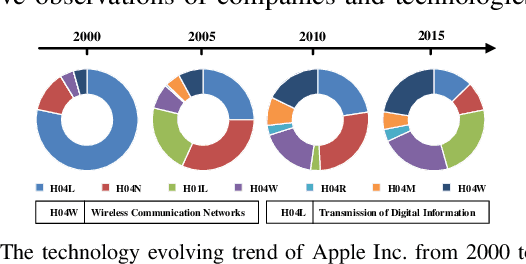
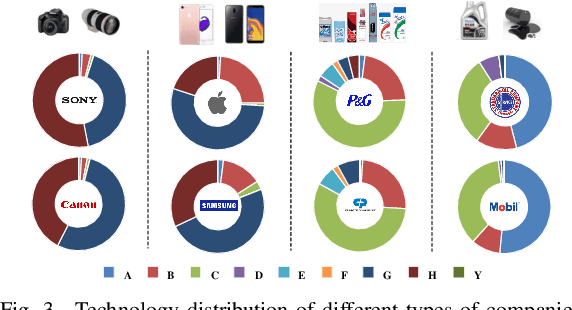
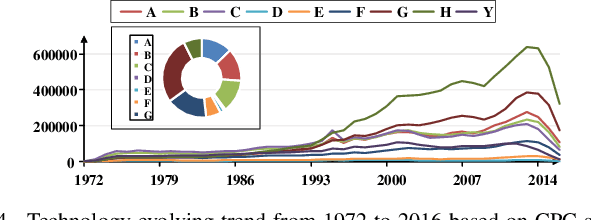
Technological change and innovation are vitally important, especially for high-tech companies. However, factors influencing their future research and development (R&D) trends are both complicated and various, leading it a quite difficult task to make technology tracing for high-tech companies. To this end, in this paper, we develop a novel data-driven solution, i.e., Deep Technology Forecasting (DTF) framework, to automatically find the most possible technology directions customized to each high-tech company. Specially, DTF consists of three components: Potential Competitor Recognition (PCR), Collaborative Technology Recognition (CTR), and Deep Technology Tracing (DTT) neural network. For one thing, PCR and CTR aim to capture competitive relations among enterprises and collaborative relations among technologies, respectively. For another, DTT is designed for modeling dynamic interactions between companies and technologies with the above relations involved. Finally, we evaluate our DTF framework on real-world patent data, and the experimental results clearly prove that DTF can precisely help to prospect future technology emphasis of companies by exploiting hybrid factors.
Skeptical Deep Learning with Distribution Correction
Nov 09, 2018
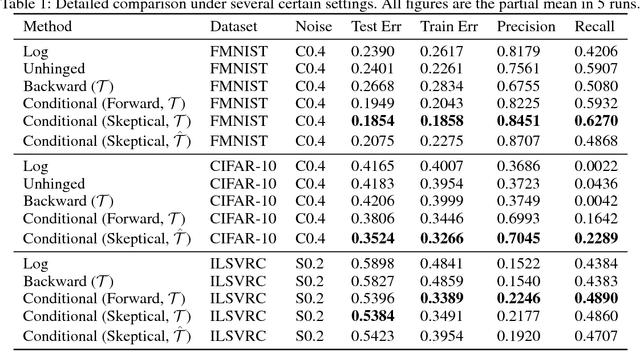

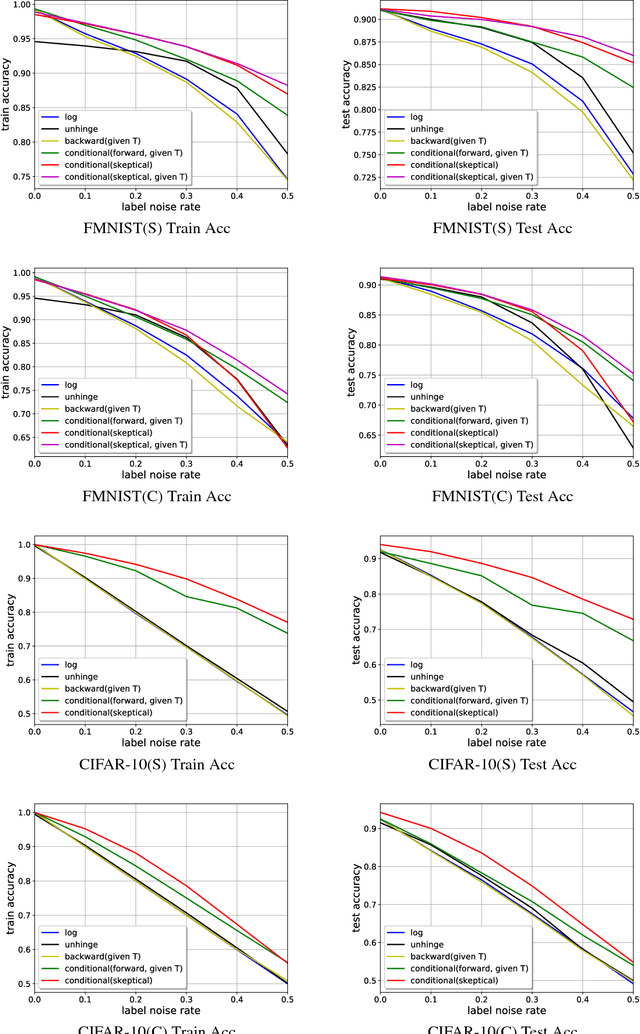
Recently deep neural networks have been successfully used for various classification tasks, especially for problems with massive perfectly labeled training data. However, it is often costly to have large-scale credible labels in real-world applications. One solution is to make supervised learning robust with imperfectly labeled input. In this paper, we develop a distribution correction approach that allows deep neural networks to avoid overfitting imperfect training data. Specifically, we treat the noisy input as samples from an incorrect distribution, which will be automatically corrected during our training process. We test our approach on several classification datasets with elaborately generated noisy labels. The results show significantly higher prediction and recovery accuracy with our approach compared to alternative methods.