 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkeptical Deep Learning with Distribution Correction
Paper and Code
Nov 09, 2018
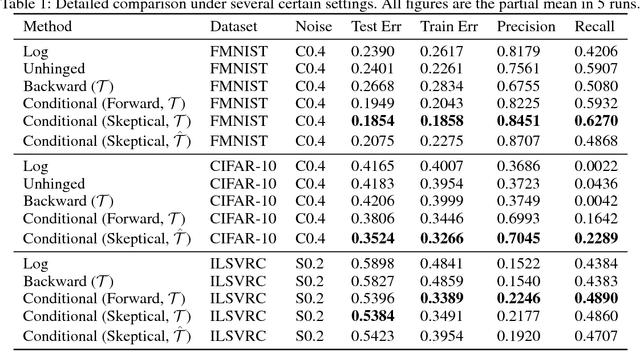

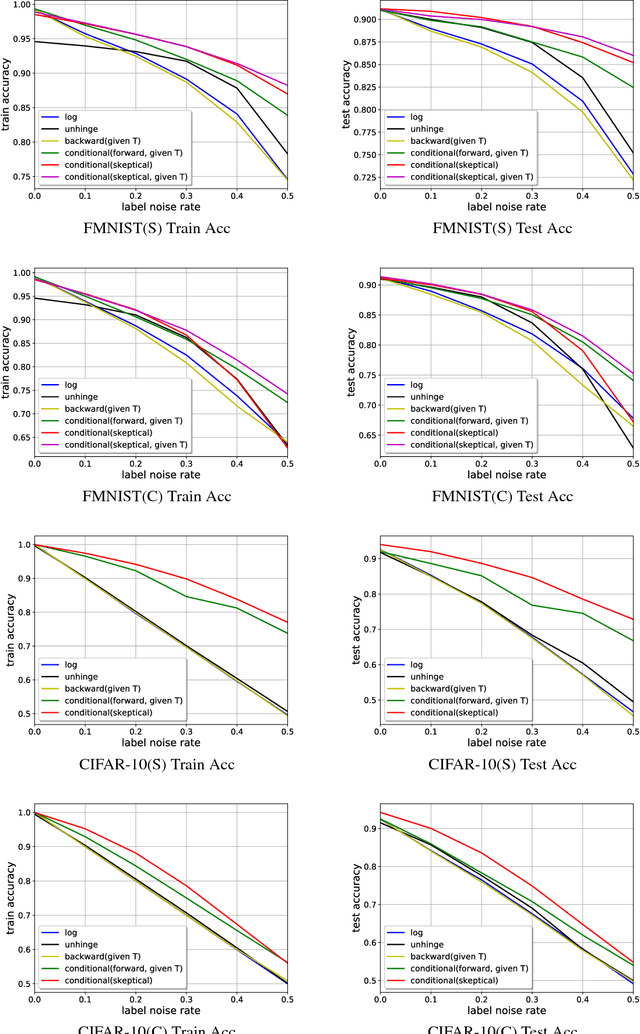
Recently deep neural networks have been successfully used for various classification tasks, especially for problems with massive perfectly labeled training data. However, it is often costly to have large-scale credible labels in real-world applications. One solution is to make supervised learning robust with imperfectly labeled input. In this paper, we develop a distribution correction approach that allows deep neural networks to avoid overfitting imperfect training data. Specifically, we treat the noisy input as samples from an incorrect distribution, which will be automatically corrected during our training process. We test our approach on several classification datasets with elaborately generated noisy labels. The results show significantly higher prediction and recovery accuracy with our approach compared to alternative methods.