 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Dimensional Ability Diagnosis for Machine Learning Algorithms
Jul 14, 2023Machine learning algorithms have become ubiquitous in a number of applications (e.g. image classification). However, due to the insufficient measurement of traditional metrics (e.g. the coarse-grained Accuracy of each classifier), substantial gaps are usually observed between the real-world performance of these algorithms and their scores in standardized evaluations. In this paper, inspired by the psychometric theories from human measurement, we propose a task-agnostic evaluation framework Camilla, where a multi-dimensional diagnostic metric Ability is defined for collaboratively measuring the multifaceted strength of each machine learning algorithm. Specifically, given the response logs from different algorithms to data samples, we leverage cognitive diagnosis assumptions and neural networks to learn the complex interactions among algorithms, samples and the skills (explicitly or implicitly pre-defined) of each sample. In this way, both the abilities of each algorithm on multiple skills and some of the sample factors (e.g. sample difficulty) can be simultaneously quantified. We conduct extensive experiments with hundreds of machine learning algorithms on four public datasets, and our experimental results demonstrate that Camilla not only can capture the pros and cons of each algorithm more precisely, but also outperforms state-of-the-art baselines on the metric reliability, rank consistency and rank stability.
GraphMI: Extracting Private Graph Data from Graph Neural Networks
Jun 05, 2021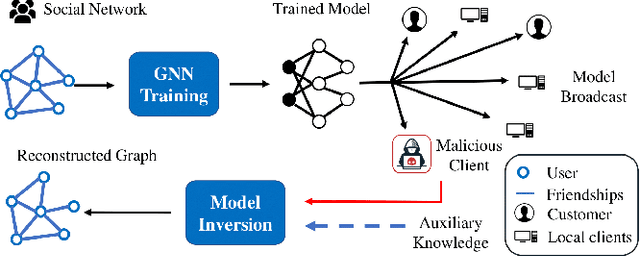

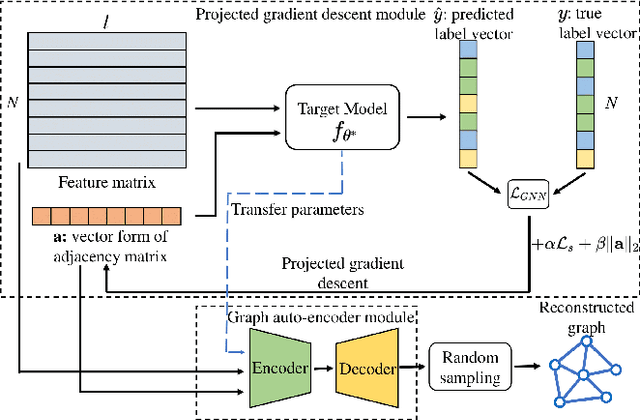
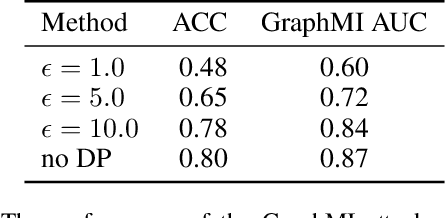
As machine learning becomes more widely used for critical applications, the need to study its implications in privacy turns to be urgent. Given access to the target model and auxiliary information, the model inversion attack aims to infer sensitive features of the training dataset, which leads to great privacy concerns. Despite its success in grid-like domains, directly applying model inversion techniques on non-grid domains such as graph achieves poor attack performance due to the difficulty to fully exploit the intrinsic properties of graphs and attributes of nodes used in Graph Neural Networks (GNN). To bridge this gap, we present \textbf{Graph} \textbf{M}odel \textbf{I}nversion attack (GraphMI), which aims to extract private graph data of the training graph by inverting GNN, one of the state-of-the-art graph analysis tools. Specifically, we firstly propose a projected gradient module to tackle the discreteness of graph edges while preserving the sparsity and smoothness of graph features. Then we design a graph auto-encoder module to efficiently exploit graph topology, node attributes, and target model parameters for edge inference. With the proposed methods, we study the connection between model inversion risk and edge influence and show that edges with greater influence are more likely to be recovered. Extensive experiments over several public datasets demonstrate the effectiveness of our method. We also show that differential privacy in its canonical form can hardly defend our attack while preserving decent utility.
Heterogeneous Graph Representation Learning with Relation Awareness
May 24, 2021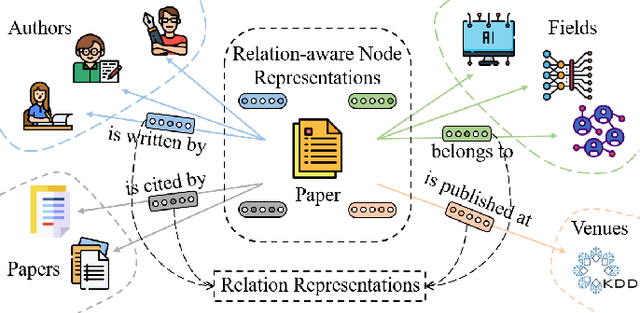

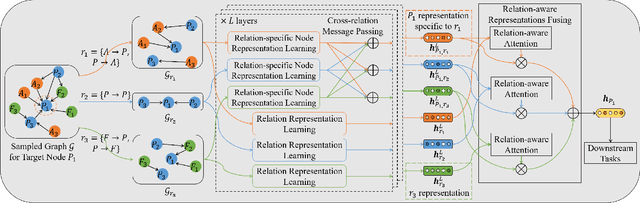

Representation learning on heterogeneous graphs aims to obtain meaningful node representations to facilitate various downstream tasks, such as node classification and link prediction. Existing heterogeneous graph learning methods are primarily developed by following the propagation mechanism of node representations. There are few efforts on studying the role of relations for improving the learning of more fine-grained node representations. Indeed, it is important to collaboratively learn the semantic representations of relations and discern node representations with respect to different relation types. To this end, in this paper, we propose a novel Relation-aware Heterogeneous Graph Neural Network, namely R-HGNN, to learn node representations on heterogeneous graphs at a fine-grained level by considering relation-aware characteristics. Specifically, a dedicated graph convolution component is first designed to learn unique node representations from each relation-specific graph separately. Then, a cross-relation message passing module is developed to improve the interactions of node representations across different relations. Also, the relation representations are learned in a layer-wise manner to capture relation semantics, which are used to guide the node representation learning process. Moreover, a semantic fusing module is presented to aggregate relation-aware node representations into a compact representation with the learned relation representations. Finally, we conduct extensive experiments on a variety of graph learning tasks, and experimental results demonstrate that our approach consistently outperforms existing methods among all the tasks.
Hybrid Micro/Macro Level Convolution for Heterogeneous Graph Learning
Dec 29, 2020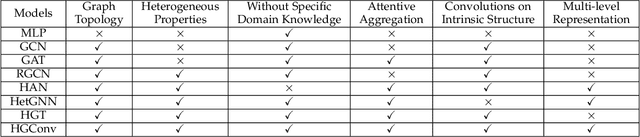
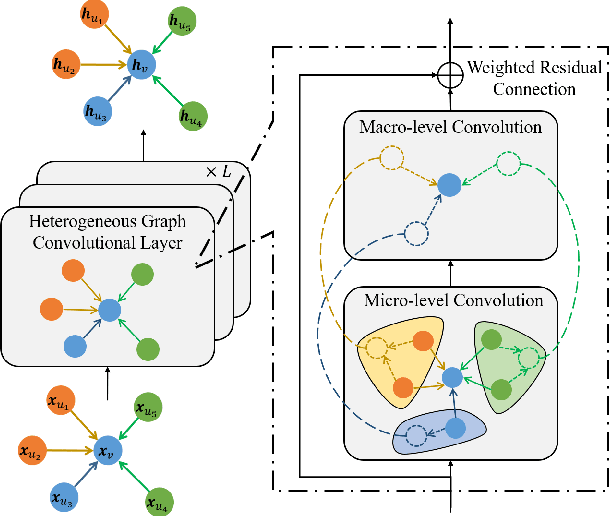
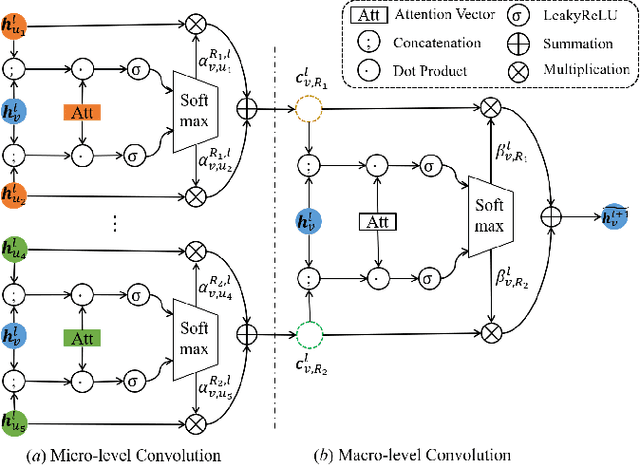
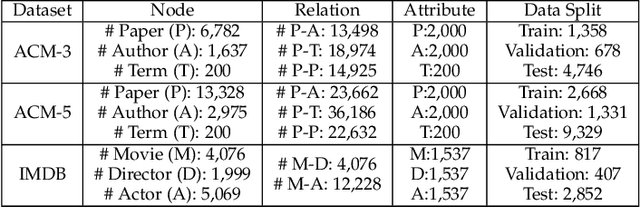
Heterogeneous graphs are pervasive in practical scenarios, where each graph consists of multiple types of nodes and edges. Representation learning on heterogeneous graphs aims to obtain low-dimensional node representations that could preserve both node attributes and relation information. However, most of the existing graph convolution approaches were designed for homogeneous graphs, and therefore cannot handle heterogeneous graphs. Some recent methods designed for heterogeneous graphs are also faced with several issues, including the insufficient utilization of heterogeneous properties, structural information loss, and lack of interpretability. In this paper, we propose HGConv, a novel Heterogeneous Graph Convolution approach, to learn comprehensive node representations on heterogeneous graphs with a hybrid micro/macro level convolutional operation. Different from existing methods, HGConv could perform convolutions on the intrinsic structure of heterogeneous graphs directly at both micro and macro levels: A micro-level convolution to learn the importance of nodes within the same relation, and a macro-level convolution to distinguish the subtle difference across different relations. The hybrid strategy enables HGConv to fully leverage heterogeneous information with proper interpretability. Moreover, a weighted residual connection is designed to aggregate both inherent attributes and neighbor information of the focal node adaptively. Extensive experiments on various tasks demonstrate not only the superiority of HGConv over existing methods, but also the intuitive interpretability of our approach for graph analysis.
Predicting Temporal Sets with Deep Neural Networks
Jul 08, 2020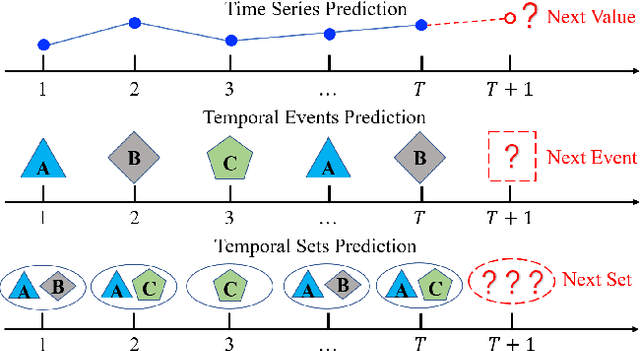
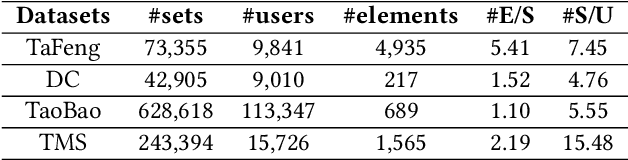
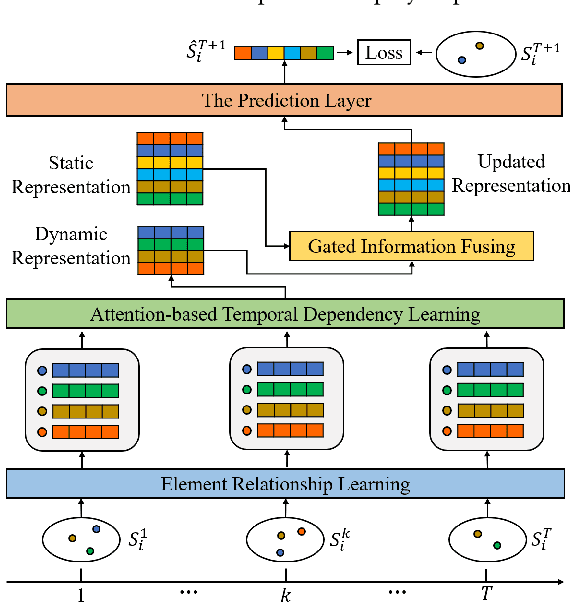
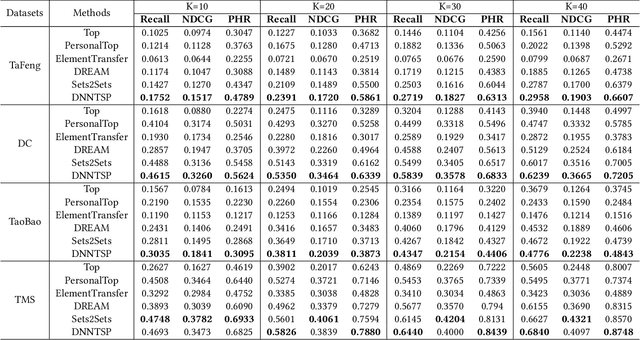
Given a sequence of sets, where each set contains an arbitrary number of elements, the problem of temporal sets prediction aims to predict the elements in the subsequent set. In practice, temporal sets prediction is much more complex than predictive modelling of temporal events and time series, and is still an open problem. Many possible existing methods, if adapted for the problem of temporal sets prediction, usually follow a two-step strategy by first projecting temporal sets into latent representations and then learning a predictive model with the latent representations. The two-step approach often leads to information loss and unsatisfactory prediction performance. In this paper, we propose an integrated solution based on the deep neural networks for temporal sets prediction. A unique perspective of our approach is to learn element relationship by constructing set-level co-occurrence graph and then perform graph convolutions on the dynamic relationship graphs. Moreover, we design an attention-based module to adaptively learn the temporal dependency of elements and sets. Finally, we provide a gated updating mechanism to find the hidden shared patterns in different sequences and fuse both static and dynamic information to improve the prediction performance. Experiments on real-world data sets demonstrate that our approach can achieve competitive performances even with a portion of the training data and can outperform existing methods with a significant margin.
Exploiting Cognitive Structure for Adaptive Learning
May 23, 2019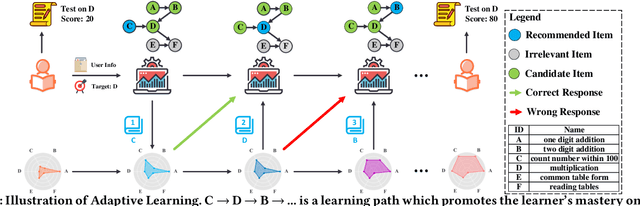
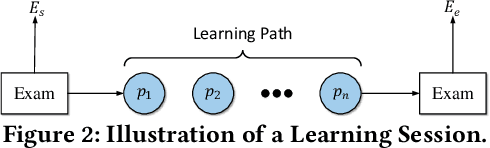
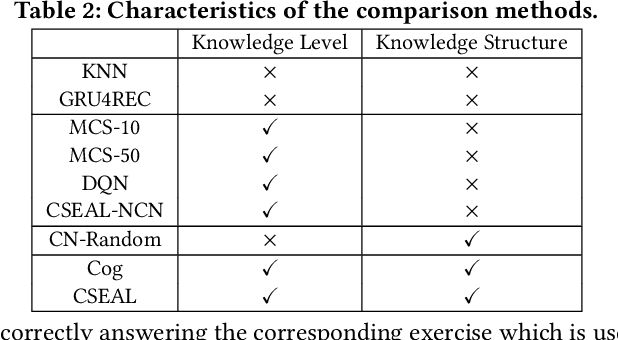
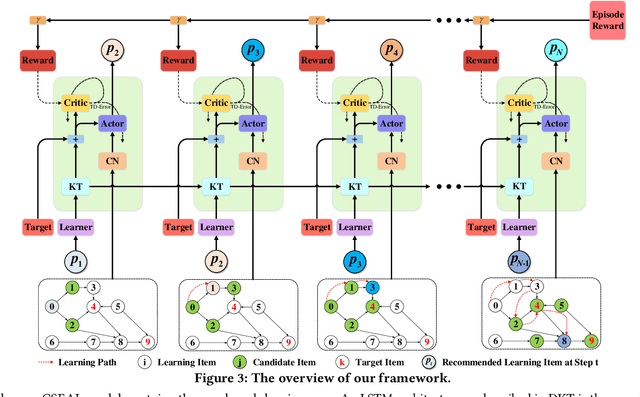
Adaptive learning, also known as adaptive teaching, relies on learning path recommendation, which sequentially recommends personalized learning items (e.g., lectures, exercises) to satisfy the unique needs of each learner. Although it is well known that modeling the cognitive structure including knowledge level of learners and knowledge structure (e.g., the prerequisite relations) of learning items is important for learning path recommendation, existing methods for adaptive learning often separately focus on either knowledge levels of learners or knowledge structure of learning items. To fully exploit the multifaceted cognitive structure for learning path recommendation, we propose a Cognitive Structure Enhanced framework for Adaptive Learning, named CSEAL. By viewing path recommendation as a Markov Decision Process and applying an actor-critic algorithm, CSEAL can sequentially identify the right learning items to different learners. Specifically, we first utilize a recurrent neural network to trace the evolving knowledge levels of learners at each learning step. Then, we design a navigation algorithm on the knowledge structure to ensure the logicality of learning paths, which reduces the search space in the decision process. Finally, the actor-critic algorithm is used to determine what to learn next and whose parameters are dynamically updated along the learning path. Extensive experiments on real-world data demonstrate the effectiveness and robustness of CSEAL.
Skeptical Deep Learning with Distribution Correction
Nov 09, 2018
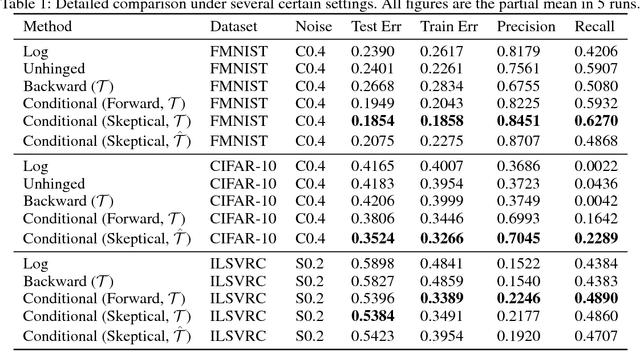

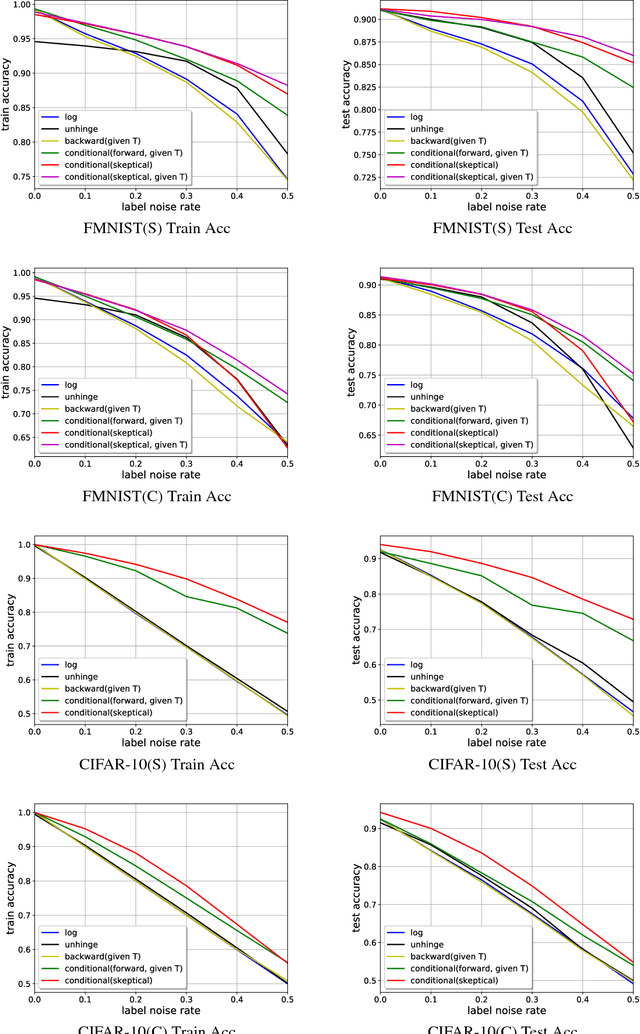
Recently deep neural networks have been successfully used for various classification tasks, especially for problems with massive perfectly labeled training data. However, it is often costly to have large-scale credible labels in real-world applications. One solution is to make supervised learning robust with imperfectly labeled input. In this paper, we develop a distribution correction approach that allows deep neural networks to avoid overfitting imperfect training data. Specifically, we treat the noisy input as samples from an incorrect distribution, which will be automatically corrected during our training process. We test our approach on several classification datasets with elaborately generated noisy labels. The results show significantly higher prediction and recovery accuracy with our approach compared to alternative methods.
Seeing the Forest from the Trees in Two Looks: Matrix Sketching by Cascaded Bilateral Sampling
Jul 27, 2016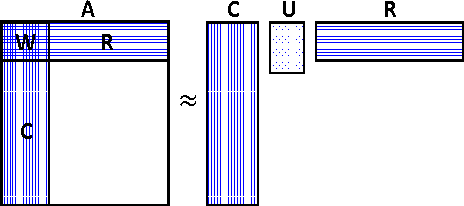

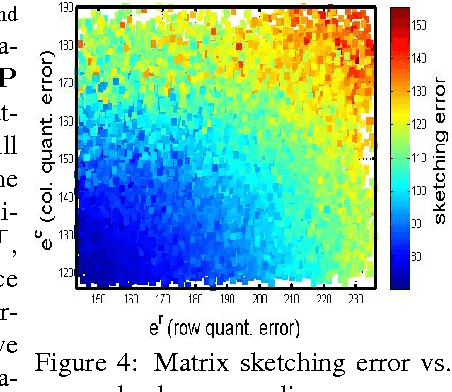
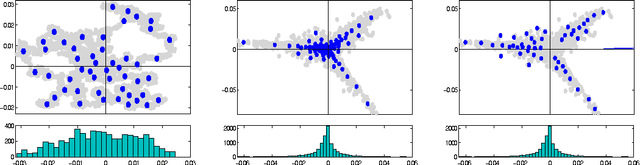
Matrix sketching is aimed at finding close approximations of a matrix by factors of much smaller dimensions, which has important applications in optimization and machine learning. Given a matrix A of size m by n, state-of-the-art randomized algorithms take O(m * n) time and space to obtain its low-rank decomposition. Although quite useful, the need to store or manipulate the entire matrix makes it a computational bottleneck for truly large and dense inputs. Can we sketch an m-by-n matrix in O(m + n) cost by accessing only a small fraction of its rows and columns, without knowing anything about the remaining data? In this paper, we propose the cascaded bilateral sampling (CABS) framework to solve this problem. We start from demonstrating how the approximation quality of bilateral matrix sketching depends on the encoding powers of sampling. In particular, the sampled rows and columns should correspond to the code-vectors in the ground truth decompositions. Motivated by this analysis, we propose to first generate a pilot-sketch using simple random sampling, and then pursue more advanced, "follow-up" sampling on the pilot-sketch factors seeking maximal encoding powers. In this cascading process, the rise of approximation quality is shown to be lower-bounded by the improvement of encoding powers in the follow-up sampling step, thus theoretically guarantees the algorithmic boosting property. Computationally, our framework only takes linear time and space, and at the same time its performance rivals the quality of state-of-the-art algorithms consuming a quadratic amount of resources. Empirical evaluations on benchmark data fully demonstrate the potential of our methods in large scale matrix sketching and related areas.