 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Parking Trajectory Generation Using Deep Reinforcement Learning
Apr 29, 2025



Autonomous parking is a key technology in modern autonomous driving systems, requiring high precision, strong adaptability, and efficiency in complex environments. This paper proposes a Deep Reinforcement Learning (DRL) framework based on the Soft Actor-Critic (SAC) algorithm to optimize autonomous parking tasks. SAC, an off-policy method with entropy regularization, is particularly well-suited for continuous action spaces, enabling fine-grained vehicle control. We model the parking task as a Markov Decision Process (MDP) and train an agent to maximize cumulative rewards while balancing exploration and exploitation through entropy maximization. The proposed system integrates multiple sensor inputs into a high-dimensional state space and leverages SAC's dual critic networks and policy network to achieve stable learning. Simulation results show that the SAC-based approach delivers high parking success rates, reduced maneuver times, and robust handling of dynamic obstacles, outperforming traditional rule-based methods and other DRL algorithms. This study demonstrates SAC's potential in autonomous parking and lays the foundation for real-world applications.
FedSS: Federated Learning with Smart Selection of clients
Jul 10, 2022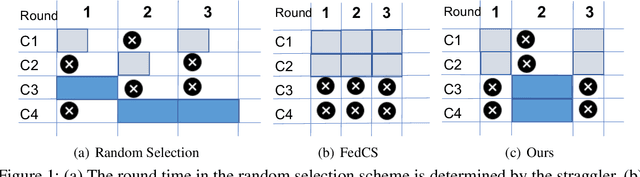


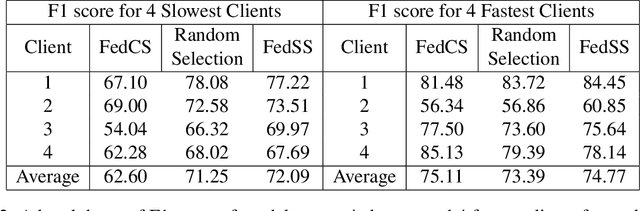
Federated learning provides the ability to learn over heterogeneous user data in a distributed manner, while preserving user privacy. However, its current clients selection technique is a source of bias as it discriminates against slow clients. For starters, it selects clients that satisfy certain network and system specific criteria, thus not selecting slow clients. Even when such clients are included in the training process, they either straggle the training or are altogether dropped from the round for being too slow. Our proposed idea looks to find a sweet spot between fast convergence and heterogeneity by looking at smart clients selection and scheduling techniques.
Skeptical Deep Learning with Distribution Correction
Nov 09, 2018
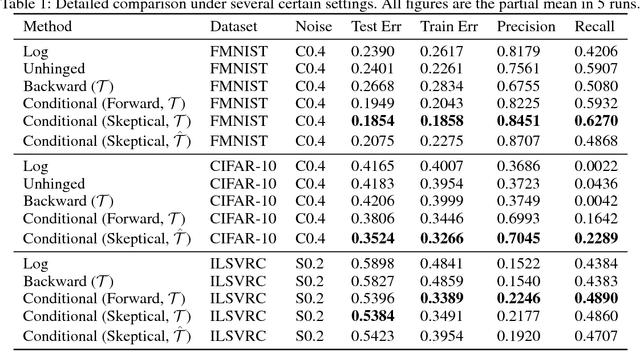

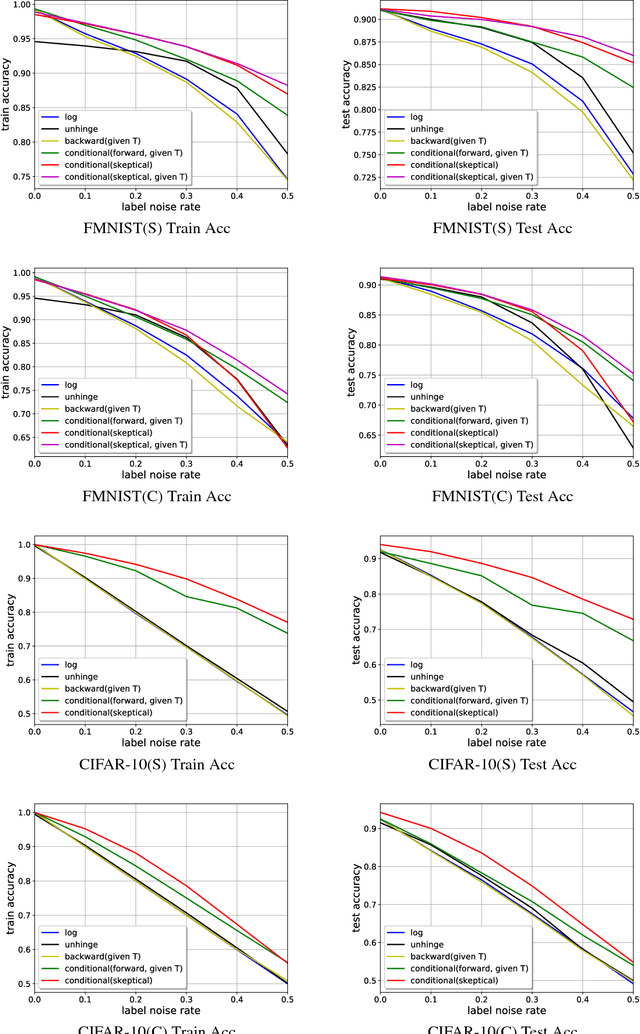
Recently deep neural networks have been successfully used for various classification tasks, especially for problems with massive perfectly labeled training data. However, it is often costly to have large-scale credible labels in real-world applications. One solution is to make supervised learning robust with imperfectly labeled input. In this paper, we develop a distribution correction approach that allows deep neural networks to avoid overfitting imperfect training data. Specifically, we treat the noisy input as samples from an incorrect distribution, which will be automatically corrected during our training process. We test our approach on several classification datasets with elaborately generated noisy labels. The results show significantly higher prediction and recovery accuracy with our approach compared to alternative methods.