Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedSS: Federated Learning with Smart Selection of clients
Paper and Code
Jul 10, 2022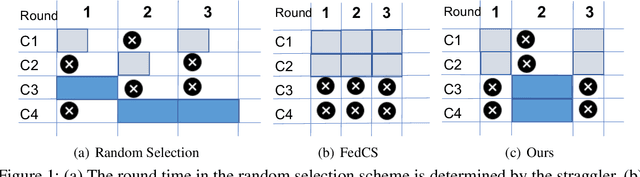


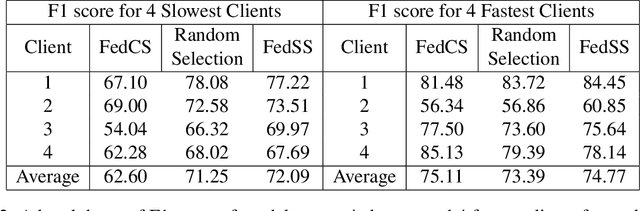
Federated learning provides the ability to learn over heterogeneous user data in a distributed manner, while preserving user privacy. However, its current clients selection technique is a source of bias as it discriminates against slow clients. For starters, it selects clients that satisfy certain network and system specific criteria, thus not selecting slow clients. Even when such clients are included in the training process, they either straggle the training or are altogether dropped from the round for being too slow. Our proposed idea looks to find a sweet spot between fast convergence and heterogeneity by looking at smart clients selection and scheduling techniques.
View paper on
 OpenReview
OpenReview