 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLemon Agent Technical Report
Feb 06, 2026Recent advanced LLM-powered agent systems have exhibited their remarkable capabilities in tackling complex, long-horizon tasks. Nevertheless, they still suffer from inherent limitations in resource efficiency, context management, and multimodal perception. Based on these observations, Lemon Agent is introduced, a multi-agent orchestrator-worker system built on a newly proposed AgentCortex framework, which formalizes the classic Planner-Executor-Memory paradigm through an adaptive task execution mechanism. Our system integrates a hierarchical self-adaptive scheduling mechanism that operates at both the overall orchestrator layer and workers layer. This mechanism can dynamically adjust computational intensity based on task complexity. It enables orchestrator to allocate one or more workers for parallel subtask execution, while workers can further improve operational efficiency by invoking tools concurrently. By virtue of this two-tier architecture, the system achieves synergistic balance between global task coordination and local task execution, thereby optimizing resource utilization and task processing efficiency in complex scenarios. To reduce context redundancy and increase information density during parallel steps, we adopt a three-tier progressive context management strategy. To make fuller use of historical information, we propose a self-evolving memory system, which can extract multi-dimensional valid information from all historical experiences to assist in completing similar tasks. Furthermore, we provide an enhanced MCP toolset. Empirical evaluations on authoritative benchmarks demonstrate that our Lemon Agent can achieve a state-of-the-art 91.36% overall accuracy on GAIA and secures the top position on the xbench-DeepSearch leaderboard with a score of 77+.
Description-Enhanced Label Embedding Contrastive Learning for Text Classification
Jun 15, 2023



Text Classification is one of the fundamental tasks in natural language processing, which requires an agent to determine the most appropriate category for input sentences. Recently, deep neural networks have achieved impressive performance in this area, especially Pre-trained Language Models (PLMs). Usually, these methods concentrate on input sentences and corresponding semantic embedding generation. However, for another essential component: labels, most existing works either treat them as meaningless one-hot vectors or use vanilla embedding methods to learn label representations along with model training, underestimating the semantic information and guidance that these labels reveal. To alleviate this problem and better exploit label information, in this paper, we employ Self-Supervised Learning (SSL) in model learning process and design a novel self-supervised Relation of Relation (R2) classification task for label utilization from a one-hot manner perspective. Then, we propose a novel Relation of Relation Learning Network (R2-Net) for text classification, in which text classification and R2 classification are treated as optimization targets. Meanwhile, triplet loss is employed to enhance the analysis of differences and connections among labels. Moreover, considering that one-hot usage is still short of exploiting label information, we incorporate external knowledge from WordNet to obtain multi-aspect descriptions for label semantic learning and extend R2-Net to a novel Description-Enhanced Label Embedding network (DELE) from a label embedding perspective. ...
LadRa-Net: Locally-Aware Dynamic Re-read Attention Net for Sentence Semantic Matching
Aug 06, 2021
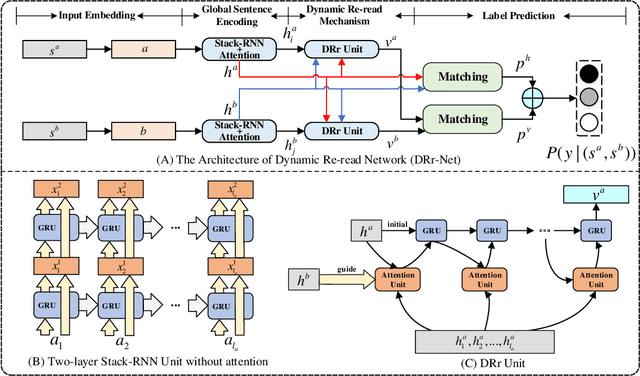

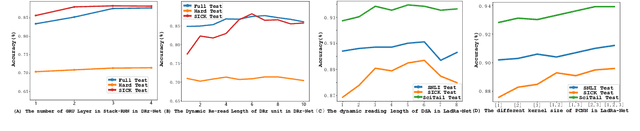
Sentence semantic matching requires an agent to determine the semantic relation between two sentences, which is widely used in various natural language tasks, such as Natural Language Inference (NLI), Paraphrase Identification (PI), and so on. Much recent progress has been made in this area, especially attention-based methods and pre-trained language model based methods. However, most of these methods focus on all the important parts in sentences in a static way and only emphasize how important the words are to the query, inhibiting the ability of attention mechanism. In order to overcome this problem and boost the performance of attention mechanism, we propose a novel dynamic re-read attention, which can pay close attention to one small region of sentences at each step and re-read the important parts for better sentence representations. Based on this attention variation, we develop a novel Dynamic Re-read Network (DRr-Net) for sentence semantic matching. Moreover, selecting one small region in dynamic re-read attention seems insufficient for sentence semantics, and employing pre-trained language models as input encoders will introduce incomplete and fragile representation problems. To this end, we extend DRrNet to Locally-Aware Dynamic Re-read Attention Net (LadRa-Net), in which local structure of sentences is employed to alleviate the shortcoming of Byte-Pair Encoding (BPE) in pre-trained language models and boost the performance of dynamic reread attention. Extensive experiments on two popular sentence semantic matching tasks demonstrate that DRr-Net can significantly improve the performance of sentence semantic matching. Meanwhile, LadRa-Net is able to achieve better performance by considering the local structures of sentences. In addition, it is exceedingly interesting that some discoveries in our experiments are consistent with some findings of psychological research.
DGA-Net Dynamic Gaussian Attention Network for Sentence Semantic Matching
Jun 09, 2021
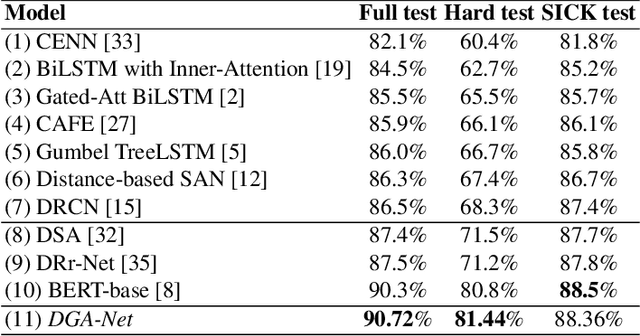


Sentence semantic matching requires an agent to determine the semantic relation between two sentences, where much recent progress has been made by the advancement of representation learning techniques and inspiration of human behaviors. Among all these methods, attention mechanism plays an essential role by selecting important parts effectively. However, current attention methods either focus on all the important parts in a static way or only select one important part at one attention step dynamically, which leaves a large space for further improvement. To this end, in this paper, we design a novel Dynamic Gaussian Attention Network (DGA-Net) to combine the advantages of current static and dynamic attention methods. More specifically, we first leverage pre-trained language model to encode the input sentences and construct semantic representations from a global perspective. Then, we develop a Dynamic Gaussian Attention (DGA) to dynamically capture the important parts and corresponding local contexts from a detailed perspective. Finally, we combine the global information and detailed local information together to decide the semantic relation of sentences comprehensively and precisely. Extensive experiments on two popular sentence semantic matching tasks demonstrate that our proposed DGA-Net is effective in improving the ability of attention mechanism.
R$^2$-Net: Relation of Relation Learning Network for Sentence Semantic Matching
Dec 16, 2020
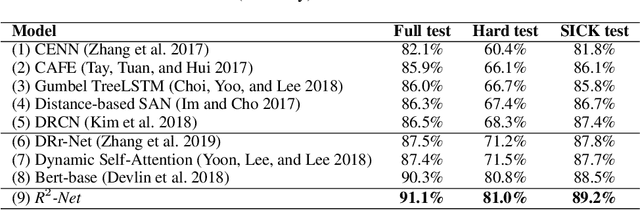
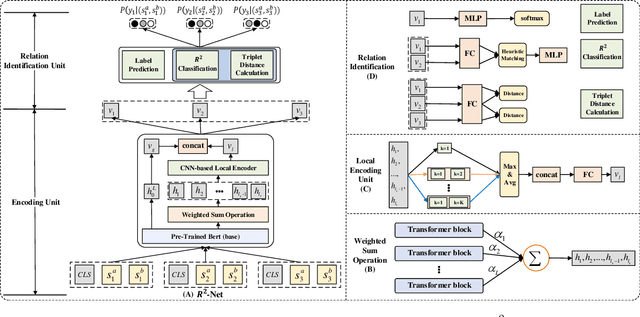
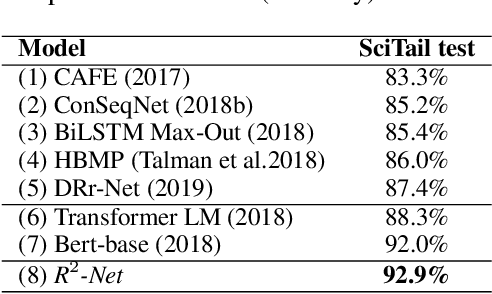
Sentence semantic matching is one of the fundamental tasks in natural language processing, which requires an agent to determine the semantic relation among input sentences. Recently, deep neural networks have achieved impressive performance in this area, especially BERT. Despite the effectiveness of these models, most of them treat output labels as meaningless one-hot vectors, underestimating the semantic information and guidance of relations that these labels reveal, especially for tasks with a small number of labels. To address this problem, we propose a Relation of Relation Learning Network (R2-Net) for sentence semantic matching. Specifically, we first employ BERT to encode the input sentences from a global perspective. Then a CNN-based encoder is designed to capture keywords and phrase information from a local perspective. To fully leverage labels for better relation information extraction, we introduce a self-supervised relation of relation classification task for guiding R2-Net to consider more about labels. Meanwhile, a triplet loss is employed to distinguish the intra-class and inter-class relations in a finer granularity. Empirical experiments on two sentence semantic matching tasks demonstrate the superiority of our proposed model. As a byproduct, we have released the codes to facilitate other researches.
Detecting Domain Polarity-Changes of Words in a Sentiment Lexicon
Apr 29, 2020
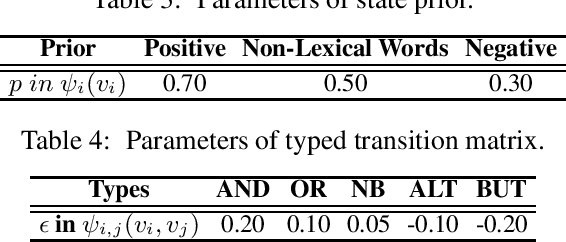
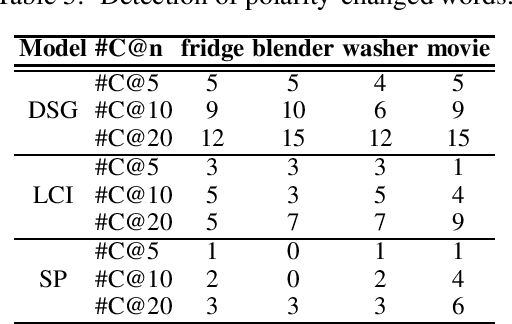
Sentiment lexicons are instrumental for sentiment analysis. One can use a set of sentiment words provided in a sentiment lexicon and a lexicon-based classifier to perform sentiment classification. One major issue with this approach is that many sentiment words are domain dependent. That is, they may be positive in some domains but negative in some others. We refer to this problem as domain polarity-changes of words. Detecting such words and correcting their sentiment for an application domain is very important. In this paper, we propose a graph-based technique to tackle this problem. Experimental results show its effectiveness on multiple real-world datasets.
Deep Technology Tracing for High-tech Companies
Jan 02, 2020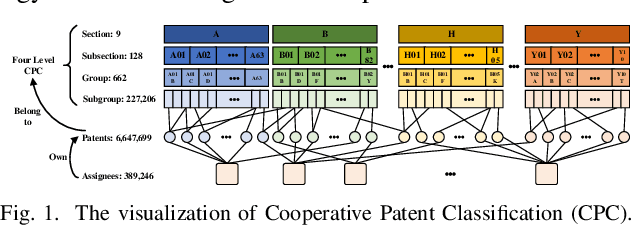
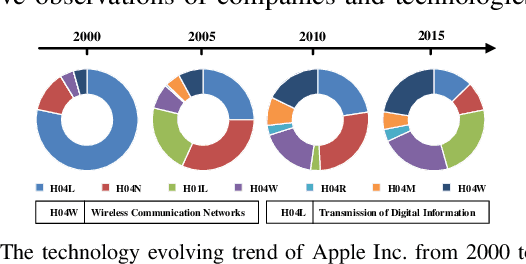
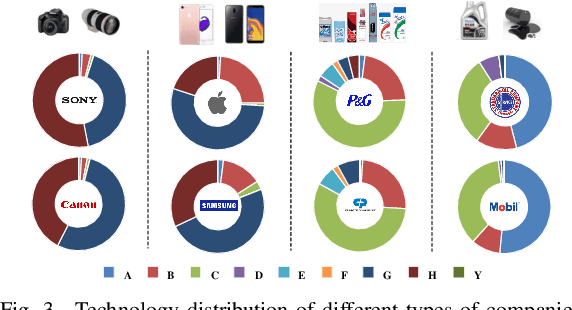
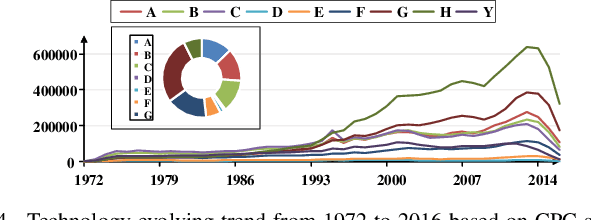
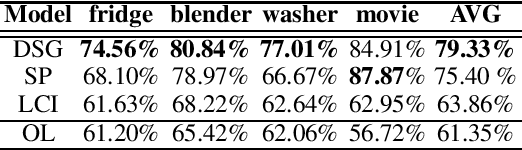
Technological change and innovation are vitally important, especially for high-tech companies. However, factors influencing their future research and development (R&D) trends are both complicated and various, leading it a quite difficult task to make technology tracing for high-tech companies. To this end, in this paper, we develop a novel data-driven solution, i.e., Deep Technology Forecasting (DTF) framework, to automatically find the most possible technology directions customized to each high-tech company. Specially, DTF consists of three components: Potential Competitor Recognition (PCR), Collaborative Technology Recognition (CTR), and Deep Technology Tracing (DTT) neural network. For one thing, PCR and CTR aim to capture competitive relations among enterprises and collaborative relations among technologies, respectively. For another, DTT is designed for modeling dynamic interactions between companies and technologies with the above relations involved. Finally, we evaluate our DTF framework on real-world patent data, and the experimental results clearly prove that DTF can precisely help to prospect future technology emphasis of companies by exploiting hybrid factors.
Skeptical Deep Learning with Distribution Correction
Nov 09, 2018
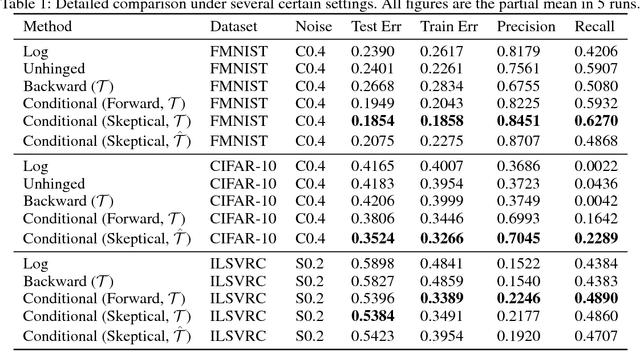

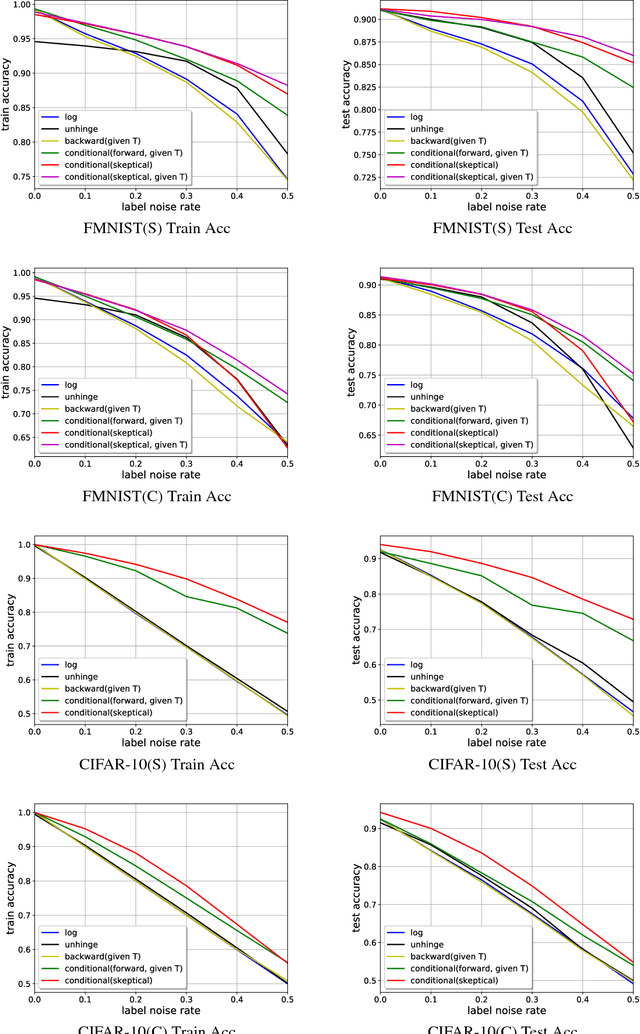
Recently deep neural networks have been successfully used for various classification tasks, especially for problems with massive perfectly labeled training data. However, it is often costly to have large-scale credible labels in real-world applications. One solution is to make supervised learning robust with imperfectly labeled input. In this paper, we develop a distribution correction approach that allows deep neural networks to avoid overfitting imperfect training data. Specifically, we treat the noisy input as samples from an incorrect distribution, which will be automatically corrected during our training process. We test our approach on several classification datasets with elaborately generated noisy labels. The results show significantly higher prediction and recovery accuracy with our approach compared to alternative methods.